 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Easy-to-Read in Germany: A Survey on its Current State and Available Resources
Jun 05, 2023
Easy-to-Read Language (E2R) is a controlled language variant that makes any written text more accessible through the use of clear, direct and simple language. It is mainly aimed at people with cognitive or intellectual disabilities, among other target users. Plain Language (PL), on the other hand, is a variant of a given language, which aims to promote the use of simple language to communicate information. German counts with Leichte Sprache (LS), its version of E2R, and Einfache Sprache (ES), its version of PL. In recent years, important developments have been conducted in the field of LS. This paper offers an updated overview of the existing Natural Language Processing (NLP) tools and resources for LS. Besides, it also aims to set out the situation with regard to LS and ES in Germany.
Query Encoder Distillation via Embedding Alignment is a Strong Baseline Method to Boost Dense Retriever Online Efficiency
Jun 05, 2023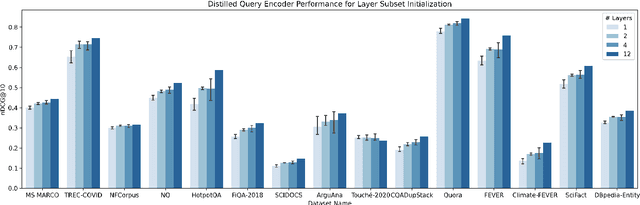
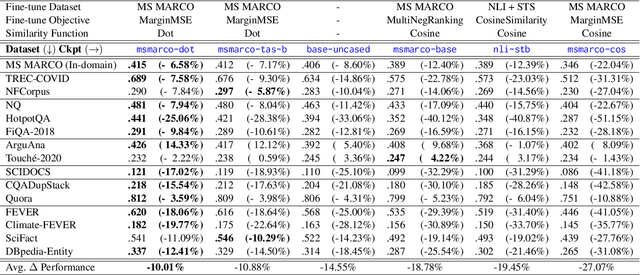
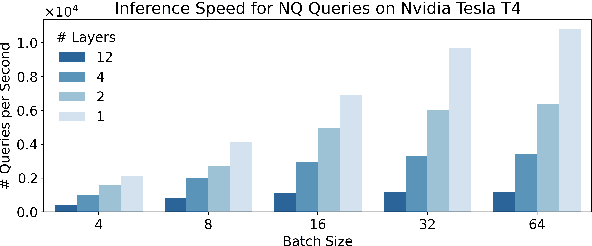

The information retrieval community has made significant progress in improving the efficiency of Dual Encoder (DE) dense passage retrieval systems, making them suitable for latency-sensitive settings. However, many proposed procedures are often too complex or resource-intensive, which makes it difficult for practitioners to adopt them or identify sources of empirical gains. Therefore, in this work, we propose a trivially simple recipe to serve as a baseline method for boosting the efficiency of DE retrievers leveraging an asymmetric architecture. Our results demonstrate that even a 2-layer, BERT-based query encoder can still retain 92.5% of the full DE performance on the BEIR benchmark via unsupervised distillation and proper student initialization. We hope that our findings will encourage the community to re-evaluate the trade-offs between method complexity and performance improvements.
Skill Disentanglement for Imitation Learning from Suboptimal Demonstrations
Jun 13, 2023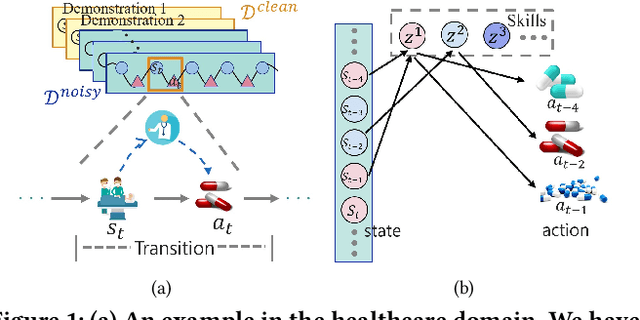
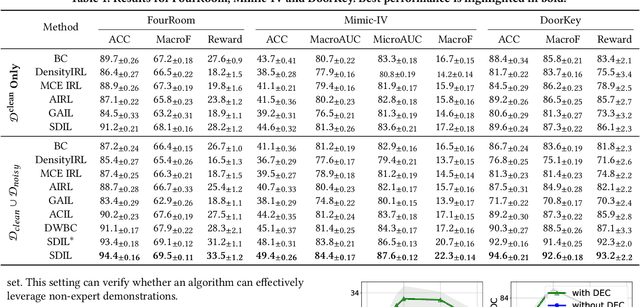
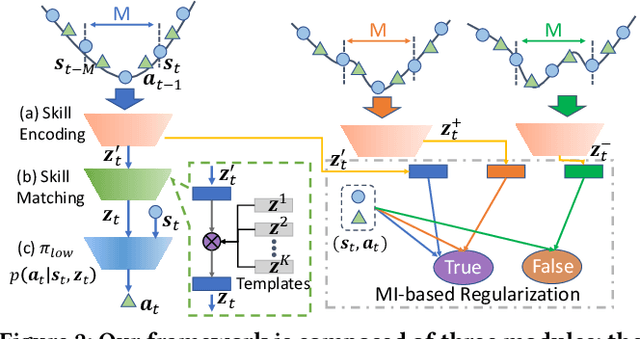
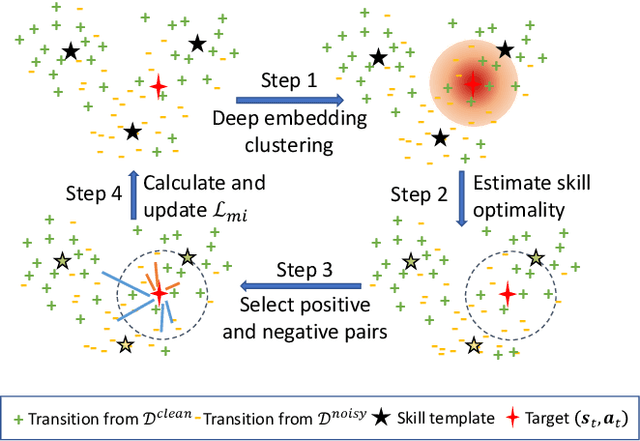
Imitation learning has achieved great success in many sequential decision-making tasks, in which a neural agent is learned by imitating collected human demonstrations. However, existing algorithms typically require a large number of high-quality demonstrations that are difficult and expensive to collect. Usually, a trade-off needs to be made between demonstration quality and quantity in practice. Targeting this problem, in this work we consider the imitation of sub-optimal demonstrations, with both a small clean demonstration set and a large noisy set. Some pioneering works have been proposed, but they suffer from many limitations, e.g., assuming a demonstration to be of the same optimality throughout time steps and failing to provide any interpretation w.r.t knowledge learned from the noisy set. Addressing these problems, we propose {\method} by evaluating and imitating at the sub-demonstration level, encoding action primitives of varying quality into different skills. Concretely, {\method} consists of a high-level controller to discover skills and a skill-conditioned module to capture action-taking policies, and is trained following a two-phase pipeline by first discovering skills with all demonstrations and then adapting the controller to only the clean set. A mutual-information-based regularization and a dynamic sub-demonstration optimality estimator are designed to promote disentanglement in the skill space. Extensive experiments are conducted over two gym environments and a real-world healthcare dataset to demonstrate the superiority of {\method} in learning from sub-optimal demonstrations and its improved interpretability by examining learned skills.
How Can Recommender Systems Benefit from Large Language Models: A Survey
Jun 12, 2023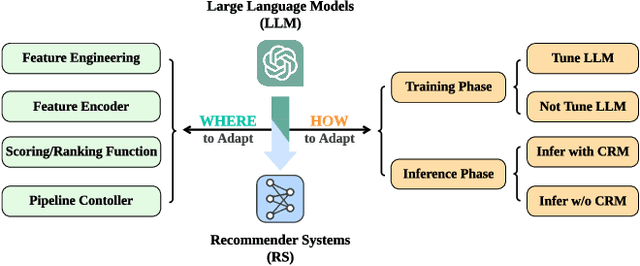
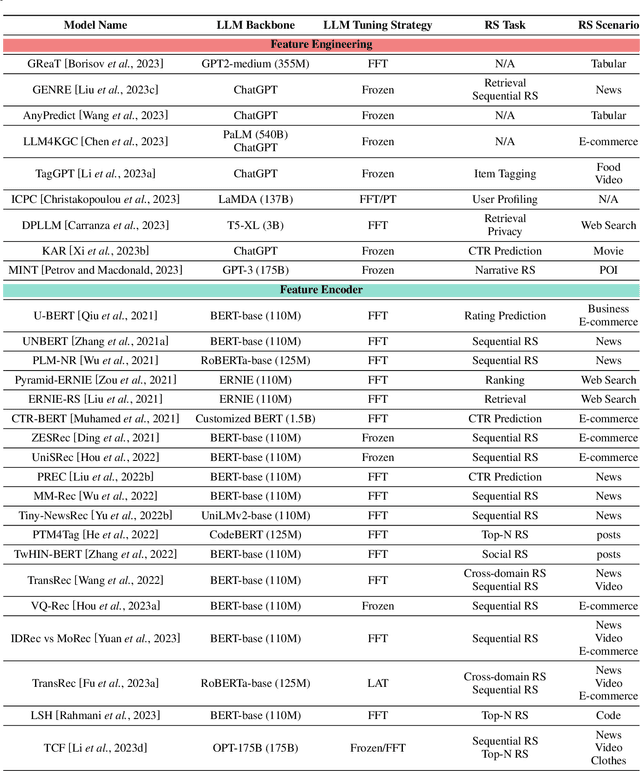
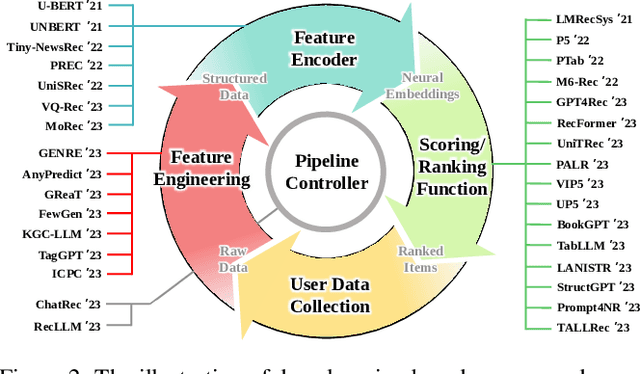
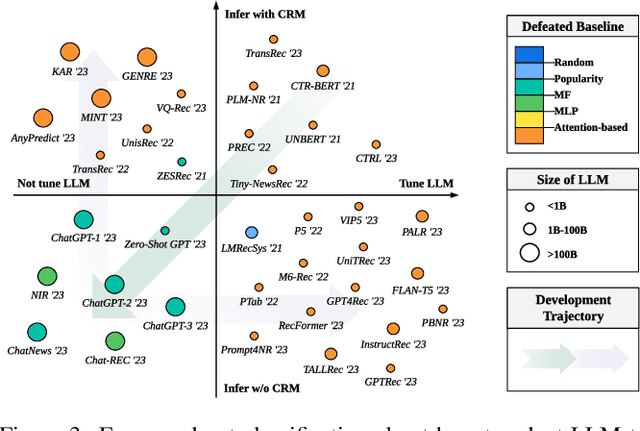
Recommender systems (RS) play important roles to match users' information needs for Internet applications. In natural language processing (NLP) domains, large language model (LLM) has shown astonishing emergent abilities (e.g., instruction following, reasoning), thus giving rise to the promising research direction of adapting LLM to RS for performance enhancements and user experience improvements. In this paper, we conduct a comprehensive survey on this research direction from an application-oriented view. We first summarize existing research works from two orthogonal perspectives: where and how to adapt LLM to RS. For the "WHERE" question, we discuss the roles that LLM could play in different stages of the recommendation pipeline, i.e., feature engineering, feature encoder, scoring/ranking function, and pipeline controller. For the "HOW" question, we investigate the training and inference strategies, resulting in two fine-grained taxonomy criteria, i.e., whether to tune LLMs or not, and whether to involve conventional recommendation model (CRM) for inference. Detailed analysis and general development trajectories are provided for both questions, respectively. Then, we highlight key challenges in adapting LLM to RS from three aspects, i.e., efficiency, effectiveness, and ethics. Finally, we summarize the survey and discuss the future prospects. We also actively maintain a GitHub repository for papers and other related resources in this rising direction: https://github.com/CHIANGEL/Awesome-LLM-for-RecSys.
Augmenting Language Models with Long-Term Memory
Jun 12, 2023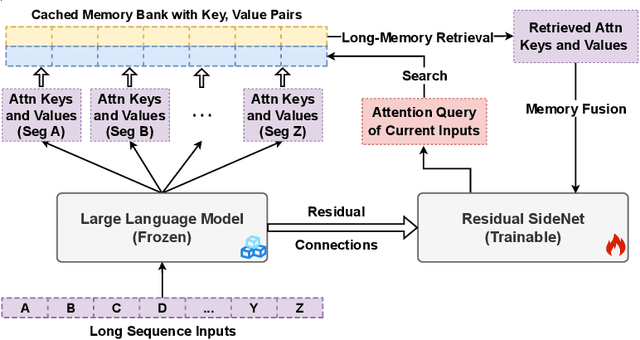

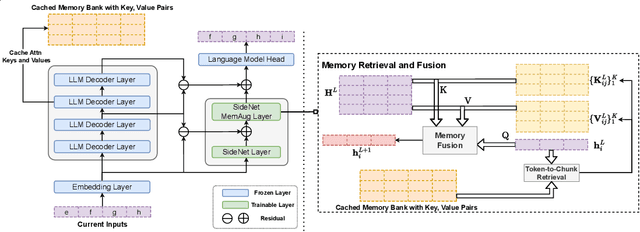

Existing large language models (LLMs) can only afford fix-sized inputs due to the input length limit, preventing them from utilizing rich long-context information from past inputs. To address this, we propose a framework, Language Models Augmented with Long-Term Memory (LongMem), which enables LLMs to memorize long history. We design a novel decoupled network architecture with the original backbone LLM frozen as a memory encoder and an adaptive residual side-network as a memory retriever and reader. Such a decoupled memory design can easily cache and update long-term past contexts for memory retrieval without suffering from memory staleness. Enhanced with memory-augmented adaptation training, LongMem can thus memorize long past context and use long-term memory for language modeling. The proposed memory retrieval module can handle unlimited-length context in its memory bank to benefit various downstream tasks. Typically, LongMem can enlarge the long-form memory to 65k tokens and thus cache many-shot extra demonstration examples as long-form memory for in-context learning. Experiments show that our method outperforms strong long-context models on ChapterBreak, a challenging long-context modeling benchmark, and achieves remarkable improvements on memory-augmented in-context learning over LLMs. The results demonstrate that the proposed method is effective in helping language models to memorize and utilize long-form contents. Our code is open-sourced at https://aka.ms/LongMem.
Occlusion-Aware Path Planning for Collision Avoidance: Leveraging Potential Field Method with Responsibility-Sensitive Safety
Jun 12, 2023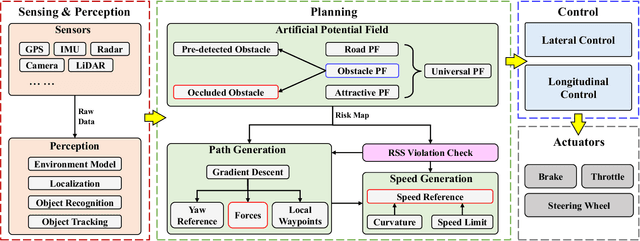
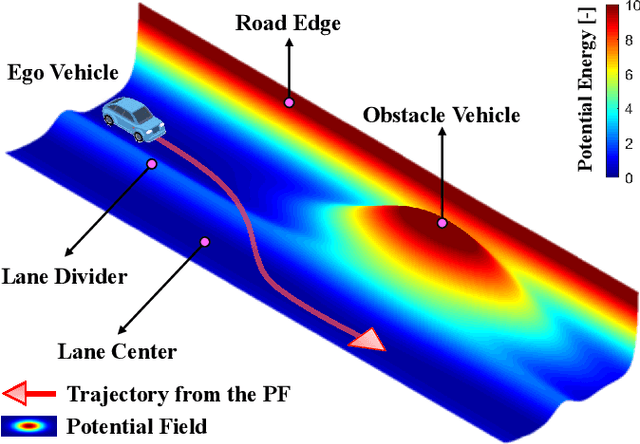
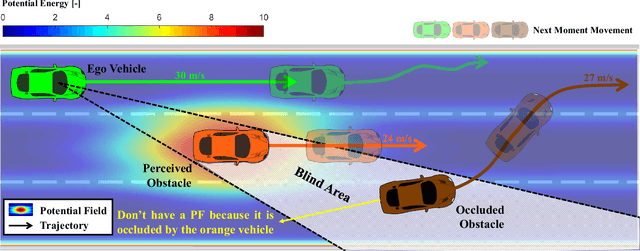
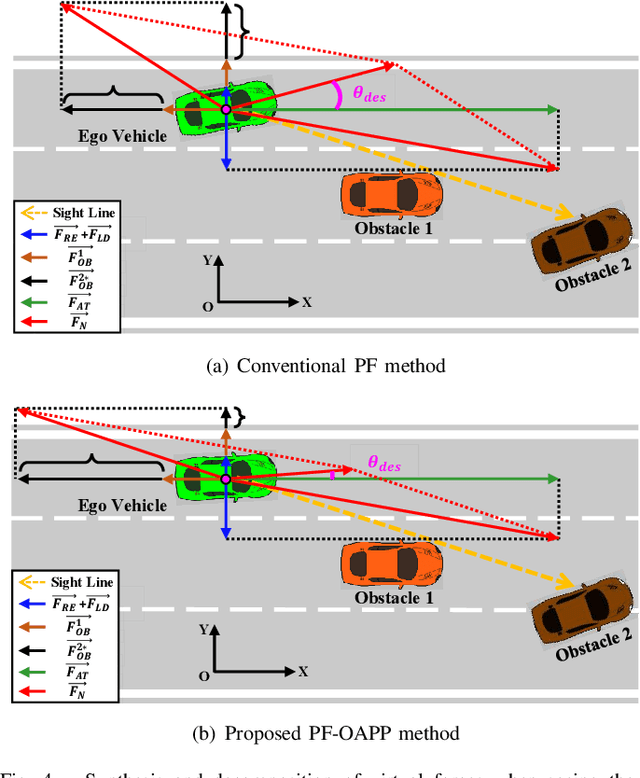
Collision avoidance (CA) has always been the foremost task for autonomous vehicles (AVs) under safety criteria. And path planning is directly responsible for generating a safe path to accomplish CA while satisfying other commands. Due to the real-time computation and simple structure, the potential field (PF) has emerged as one of the mainstream path-planning algorithms. However, the current PF is primarily simulated in ideal CA scenarios, assuming complete obstacle information while disregarding occlusion issues where obstacles can be partially or entirely hidden from the AV's sensors. During the occlusion period, the occluded obstacles do not possess a PF. Once the occlusion is over, these obstacles can generate an instantaneous virtual force that impacts the ego vehicle. Therefore, we propose an occlusion-aware path planning (OAPP) with the responsibility-sensitive safety (RSS)-based PF to tackle the occlusion problem for non-connected AVs. We first categorize the detected and occluded obstacles, and then we proceed to the RSS violation check. Finally, we can generate different virtual forces from the PF for occluded and non-occluded obstacles. We compare the proposed OAPP method with other PF-based path planning methods via MATLAB/Simulink. The simulation results indicate that the proposed method can eliminate instantaneous lateral oscillation or sway and produce a smoother path than conventional PF methods.
PGformer: Proxy-Bridged Game Transformer for Multi-Person Extremely Interactive Motion Prediction
Jun 12, 2023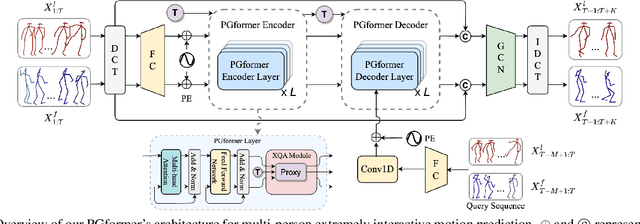
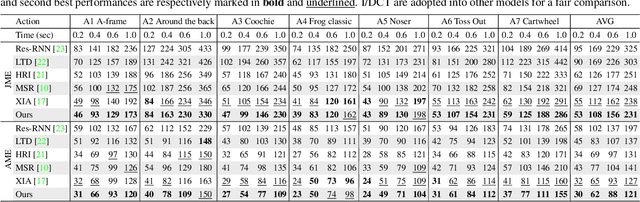
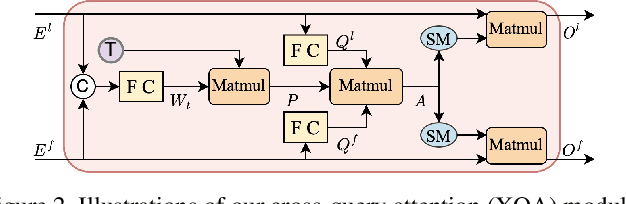
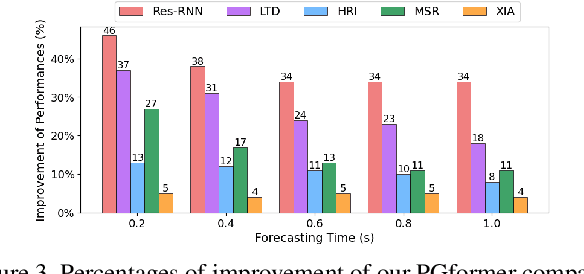
Multi-person motion prediction is a challenging task, especially for real-world scenarios of densely interacted persons. Most previous works have been devoted to studying the case of weak interactions (e.g., hand-shaking), which typically forecast each human pose in isolation. In this paper, we focus on motion prediction for multiple persons with extreme collaborations and attempt to explore the relationships between the highly interactive persons' motion trajectories. Specifically, a novel cross-query attention (XQA) module is proposed to bilaterally learn the cross-dependencies between the two pose sequences tailored for this situation. Additionally, we introduce and build a proxy entity to bridge the involved persons, which cooperates with our proposed XQA module and subtly controls the bidirectional information flows, acting as a motion intermediary. We then adapt these designs to a Transformer-based architecture and devise a simple yet effective end-to-end framework called proxy-bridged game Transformer (PGformer) for multi-person interactive motion prediction. The effectiveness of our method has been evaluated on the challenging ExPI dataset, which involves highly interactive actions. We show that our PGformer consistently outperforms the state-of-the-art methods in both short- and long-term predictions by a large margin. Besides, our approach can also be compatible with the weakly interacted CMU-Mocap and MuPoTS-3D datasets and achieve encouraging results. Our code will become publicly available upon acceptance.
IoT Localization and Optimized Topology Extraction Using Eigenvector Synchronization
May 28, 2023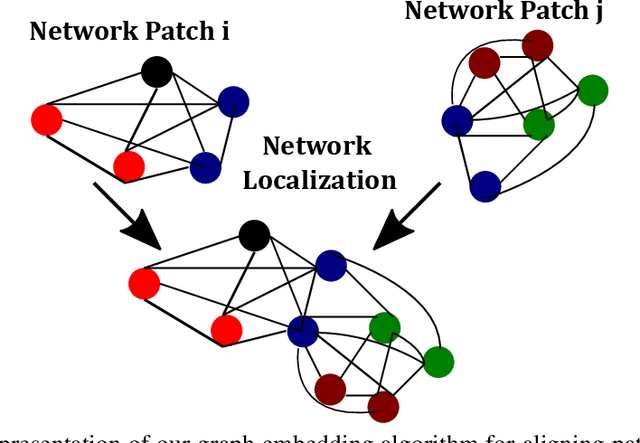
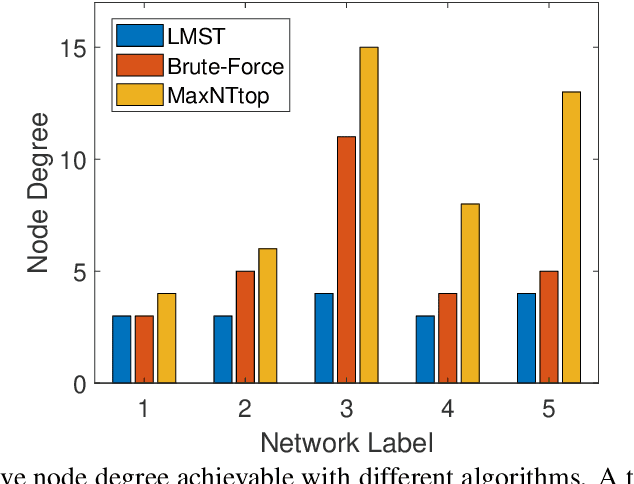
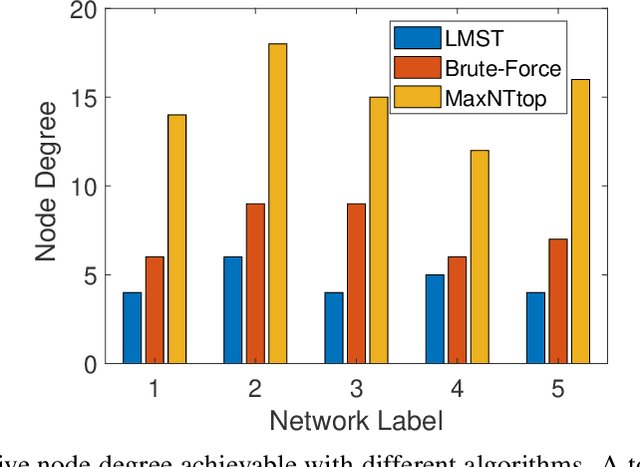
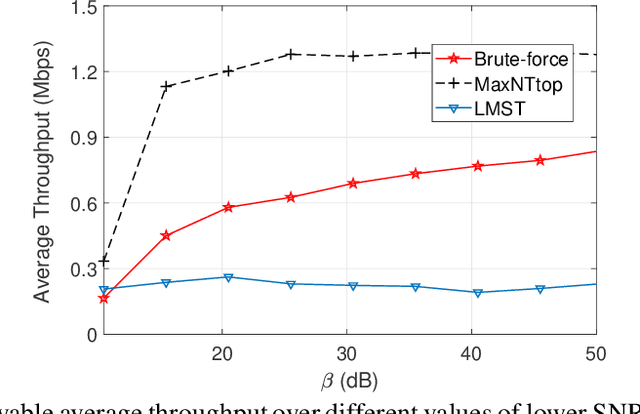
Internet-of-Things (IoT) devices are low size, weight and power (SWaP), low complexity and include sensors, meters, wearables and trackers. Transmitting information with high signal power is exacting on device battery life, therefore an efficient link and network configuration is absolutely crucial to avoid signal power enhancement in interference-rich environment and resorting to battery-life extending strategies. Efficient network configuration can also ensure fulfilment of network performance metrics like throughput, coding rate and spectral efficiency. We formulate a novel approach of first localizing the IoT nodes and then extracting the network topology for information exchange between the nodes (devices, gateway and sinks), such that overall network throughput is maximized. The nodes are localized using noisy measurements of a subset of Euclidean distances between two nodes. Realizable subsets of neighboring devices agree with their own position within the entire network graph through eigenvector synchronization. Using communication global graph-model-based technique, network topology is constructed in terms of transmit power allocation with the aim of maximizing spatial usage and overall network throughput. This topology extraction problem is solved using the concept of linear programming.
Atomic and Subgraph-aware Bilateral Aggregation for Molecular Representation Learning
May 22, 2023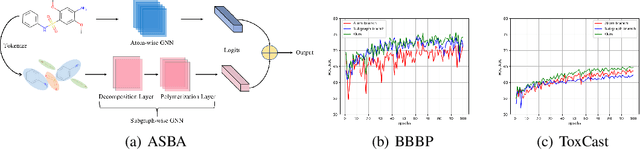

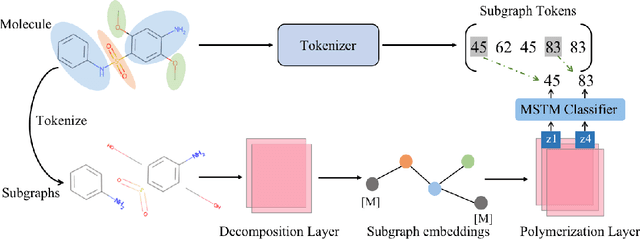
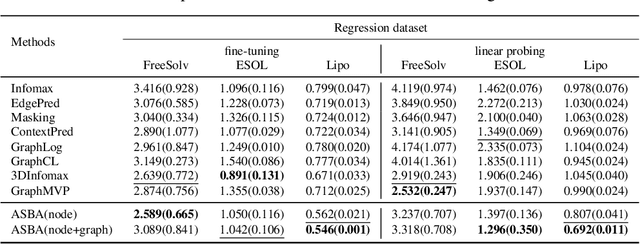
Molecular representation learning is a crucial task in predicting molecular properties. Molecules are often modeled as graphs where atoms and chemical bonds are represented as nodes and edges, respectively, and Graph Neural Networks (GNNs) have been commonly utilized to predict atom-related properties, such as reactivity and solubility. However, functional groups (subgraphs) are closely related to some chemical properties of molecules, such as efficacy, and metabolic properties, which cannot be solely determined by individual atoms. In this paper, we introduce a new model for molecular representation learning called the Atomic and Subgraph-aware Bilateral Aggregation (ASBA), which addresses the limitations of previous atom-wise and subgraph-wise models by incorporating both types of information. ASBA consists of two branches, one for atom-wise information and the other for subgraph-wise information. Considering existing atom-wise GNNs cannot properly extract invariant subgraph features, we propose a decomposition-polymerization GNN architecture for the subgraph-wise branch. Furthermore, we propose cooperative node-level and graph-level self-supervised learning strategies for ASBA to improve its generalization. Our method offers a more comprehensive way to learn representations for molecular property prediction and has broad potential in drug and material discovery applications. Extensive experiments have demonstrated the effectiveness of our method.
Cascaded information enhancement and cross-modal attention feature fusion for multispectral pedestrian detection
Feb 17, 2023
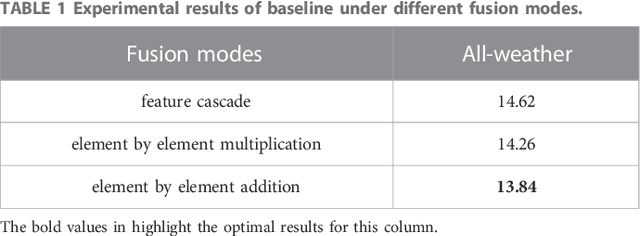
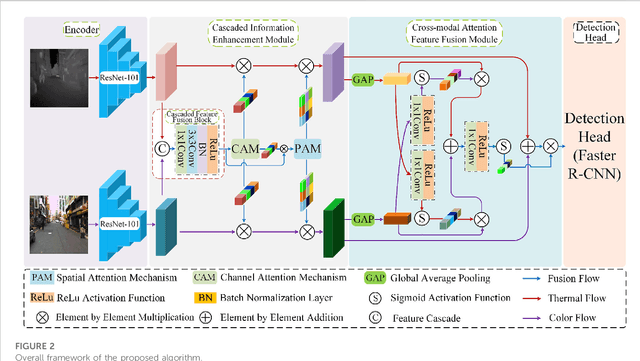
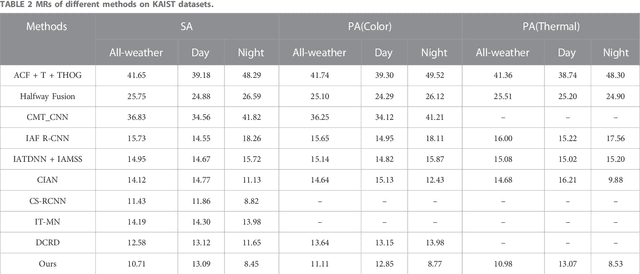
Multispectral pedestrian detection is a technology designed to detect and locate pedestrians in Color and Thermal images, which has been widely used in automatic driving, video surveillance, etc. So far most available multispectral pedestrian detection algorithms only achieved limited success in pedestrian detection because of the lacking take into account the confusion of pedestrian information and background noise in Color and Thermal images. Here we propose a multispectral pedestrian detection algorithm, which mainly consists of a cascaded information enhancement module and a cross-modal attention feature fusion module. On the one hand, the cascaded information enhancement module adopts the channel and spatial attention mechanism to perform attention weighting on the features fused by the cascaded feature fusion block. Moreover, it multiplies the single-modal features with the attention weight element by element to enhance the pedestrian features in the single-modal and thus suppress the interference from the background. On the other hand, the cross-modal attention feature fusion module mines the features of both Color and Thermal modalities to complement each other, then the global features are constructed by adding the cross-modal complemented features element by element, which are attentionally weighted to achieve the effective fusion of the two modal features. Finally, the fused features are input into the detection head to detect and locate pedestrians. Extensive experiments have been performed on two improved versions of annotations (sanitized annotations and paired annotations) of the public dataset KAIST. The experimental results show that our method demonstrates a lower pedestrian miss rate and more accurate pedestrian detection boxes compared to the comparison method. Additionally, the ablation experiment also proved the effectiveness of each module designed in this paper.