 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Procedural Graph Extraction with Structural and Logical Refinement
Jan 27, 2026Automatically extracting workflows as procedural graphs from natural language is promising yet underexplored, demanding both structural validity and logical alignment. While recent large language models (LLMs) show potential for procedural graph extraction, they often produce ill-formed structures or misinterpret logical flows. We present \model{}, a multi-agent framework that formulates procedural graph extraction as a multi-round reasoning process with dedicated structural and logical refinement. The framework iterates through three stages: (1) a graph extraction phase with the graph builder agent, (2) a structural feedback phase in which a simulation agent diagnoses and explains structural defects, and (3) a logical feedback phase in which a semantic agent aligns semantics between flow logic and linguistic cues in the source text. Important feedback is prioritized and expressed in natural language, which is injected into subsequent prompts, enabling interpretable and controllable refinement. This modular design allows agents to target distinct error types without supervision or parameter updates. Experiments demonstrate that \model{} achieves substantial improvements in both structural correctness and logical consistency over strong baselines.
xTime: Extreme Event Prediction with Hierarchical Knowledge Distillation and Expert Fusion
Oct 23, 2025Extreme events frequently occur in real-world time series and often carry significant practical implications. In domains such as climate and healthcare, these events, such as floods, heatwaves, or acute medical episodes, can lead to serious consequences. Accurate forecasting of such events is therefore of substantial importance. Most existing time series forecasting models are optimized for overall performance within the prediction window, but often struggle to accurately predict extreme events, such as high temperatures or heart rate spikes. The main challenges are data imbalance and the neglect of valuable information contained in intermediate events that precede extreme events. In this paper, we propose xTime, a novel framework for extreme event forecasting in time series. xTime leverages knowledge distillation to transfer information from models trained on lower-rarity events, thereby improving prediction performance on rarer ones. In addition, we introduce a mixture of experts (MoE) mechanism that dynamically selects and fuses outputs from expert models across different rarity levels, which further improves the forecasting performance for extreme events. Experiments on multiple datasets show that xTime achieves consistent improvements, with forecasting accuracy on extreme events improving from 3% to 78%.
DeepSieve: Information Sieving via LLM-as-a-Knowledge-Router
Jul 30, 2025Large Language Models (LLMs) excel at many reasoning tasks but struggle with knowledge-intensive queries due to their inability to dynamically access up-to-date or domain-specific information. Retrieval-Augmented Generation (RAG) has emerged as a promising solution, enabling LLMs to ground their responses in external sources. However, existing RAG methods lack fine-grained control over both the query and source sides, often resulting in noisy retrieval and shallow reasoning. In this work, we introduce DeepSieve, an agentic RAG framework that incorporates information sieving via LLM-as-a-knowledge-router. DeepSieve decomposes complex queries into structured sub-questions and recursively routes each to the most suitable knowledge source, filtering irrelevant information through a multi-stage distillation process. Our design emphasizes modularity, transparency, and adaptability, leveraging recent advances in agentic system design. Experiments on multi-hop QA tasks across heterogeneous sources demonstrate improved reasoning depth, retrieval precision, and interpretability over conventional RAG approaches. Our codes are available at https://github.com/MinghoKwok/DeepSieve.
Multi-Modal View Enhanced Large Vision Models for Long-Term Time Series Forecasting
May 29, 2025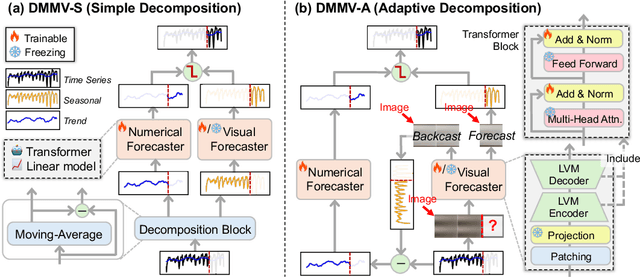

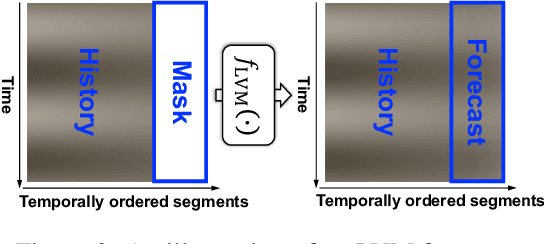

Time series, typically represented as numerical sequences, can also be transformed into images and texts, offering multi-modal views (MMVs) of the same underlying signal. These MMVs can reveal complementary patterns and enable the use of powerful pre-trained large models, such as large vision models (LVMs), for long-term time series forecasting (LTSF). However, as we identified in this work, applying LVMs to LTSF poses an inductive bias towards "forecasting periods". To harness this bias, we propose DMMV, a novel decomposition-based multi-modal view framework that leverages trend-seasonal decomposition and a novel backcast residual based adaptive decomposition to integrate MMVs for LTSF. Comparative evaluations against 14 state-of-the-art (SOTA) models across diverse datasets show that DMMV outperforms single-view and existing multi-modal baselines, achieving the best mean squared error (MSE) on 6 out of 8 benchmark datasets.
Multi-modal Time Series Analysis: A Tutorial and Survey
Mar 17, 2025Multi-modal time series analysis has recently emerged as a prominent research area in data mining, driven by the increasing availability of diverse data modalities, such as text, images, and structured tabular data from real-world sources. However, effective analysis of multi-modal time series is hindered by data heterogeneity, modality gap, misalignment, and inherent noise. Recent advancements in multi-modal time series methods have exploited the multi-modal context via cross-modal interactions based on deep learning methods, significantly enhancing various downstream tasks. In this tutorial and survey, we present a systematic and up-to-date overview of multi-modal time series datasets and methods. We first state the existing challenges of multi-modal time series analysis and our motivations, with a brief introduction of preliminaries. Then, we summarize the general pipeline and categorize existing methods through a unified cross-modal interaction framework encompassing fusion, alignment, and transference at different levels (\textit{i.e.}, input, intermediate, output), where key concepts and ideas are highlighted. We also discuss the real-world applications of multi-modal analysis for both standard and spatial time series, tailored to general and specific domains. Finally, we discuss future research directions to help practitioners explore and exploit multi-modal time series. The up-to-date resources are provided in the GitHub repository: https://github.com/UConn-DSIS/Multi-modal-Time-Series-Analysis
Explainable Multi-modal Time Series Prediction with LLM-in-the-Loop
Mar 02, 2025



Time series analysis provides essential insights for real-world system dynamics and informs downstream decision-making, yet most existing methods often overlook the rich contextual signals present in auxiliary modalities. To bridge this gap, we introduce TimeXL, a multi-modal prediction framework that integrates a prototype-based time series encoder with three collaborating Large Language Models (LLMs) to deliver more accurate predictions and interpretable explanations. First, a multi-modal prototype-based encoder processes both time series and textual inputs to generate preliminary forecasts alongside case-based rationales. These outputs then feed into a prediction LLM, which refines the forecasts by reasoning over the encoder's predictions and explanations. Next, a reflection LLM compares the predicted values against the ground truth, identifying textual inconsistencies or noise. Guided by this feedback, a refinement LLM iteratively enhances text quality and triggers encoder retraining. This closed-loop workflow -- prediction, critique (reflect), and refinement -- continuously boosts the framework's performance and interpretability. Empirical evaluations on four real-world datasets demonstrate that TimeXL achieves up to 8.9\% improvement in AUC and produces human-centric, multi-modal explanations, highlighting the power of LLM-driven reasoning for time series prediction.
TimeCAP: Learning to Contextualize, Augment, and Predict Time Series Events with Large Language Model Agents
Feb 17, 2025Time series data is essential in various applications, including climate modeling, healthcare monitoring, and financial analytics. Understanding the contextual information associated with real-world time series data is often essential for accurate and reliable event predictions. In this paper, we introduce TimeCAP, a time-series processing framework that creatively employs Large Language Models (LLMs) as contextualizers of time series data, extending their typical usage as predictors. TimeCAP incorporates two independent LLM agents: one generates a textual summary capturing the context of the time series, while the other uses this enriched summary to make more informed predictions. In addition, TimeCAP employs a multi-modal encoder that synergizes with the LLM agents, enhancing predictive performance through mutual augmentation of inputs with in-context examples. Experimental results on real-world datasets demonstrate that TimeCAP outperforms state-of-the-art methods for time series event prediction, including those utilizing LLMs as predictors, achieving an average improvement of 28.75% in F1 score.
PAIL: Performance based Adversarial Imitation Learning Engine for Carbon Neutral Optimization
Jul 12, 2024



Achieving carbon neutrality within industrial operations has become increasingly imperative for sustainable development. It is both a significant challenge and a key opportunity for operational optimization in industry 4.0. In recent years, Deep Reinforcement Learning (DRL) based methods offer promising enhancements for sequential optimization processes and can be used for reducing carbon emissions. However, existing DRL methods need a pre-defined reward function to assess the impact of each action on the final sustainable development goals (SDG). In many real applications, such a reward function cannot be given in advance. To address the problem, this study proposes a Performance based Adversarial Imitation Learning (PAIL) engine. It is a novel method to acquire optimal operational policies for carbon neutrality without any pre-defined action rewards. Specifically, PAIL employs a Transformer-based policy generator to encode historical information and predict following actions within a multi-dimensional space. The entire action sequence will be iteratively updated by an environmental simulator. Then PAIL uses a discriminator to minimize the discrepancy between generated sequences and real-world samples of high SDG. In parallel, a Q-learning framework based performance estimator is designed to estimate the impact of each action on SDG. Based on these estimations, PAIL refines generated policies with the rewards from both discriminator and performance estimator. PAIL is evaluated on multiple real-world application cases and datasets. The experiment results demonstrate the effectiveness of PAIL comparing to other state-of-the-art baselines. In addition, PAIL offers meaningful interpretability for the optimization in carbon neutrality.
InfuserKI: Enhancing Large Language Models with Knowledge Graphs via Infuser-Guided Knowledge Integration
Feb 18, 2024



Though Large Language Models (LLMs) have shown remarkable open-generation capabilities across diverse domains, they struggle with knowledge-intensive tasks. To alleviate this issue, knowledge integration methods have been proposed to enhance LLMs with domain-specific knowledge graphs using external modules. However, they suffer from data inefficiency as they require both known and unknown knowledge for fine-tuning. Thus, we study a novel problem of integrating unknown knowledge into LLMs efficiently without unnecessary overlap of known knowledge. Injecting new knowledge poses the risk of forgetting previously acquired knowledge. To tackle this, we propose a novel Infuser-Guided Knowledge Integration (InfuserKI) framework that utilizes transformer internal states to determine whether to enhance the original LLM output with additional information, thereby effectively mitigating knowledge forgetting. Evaluations on the UMLS-2.5k and MetaQA domain knowledge graphs demonstrate that InfuserKI can effectively acquire new knowledge and outperform state-of-the-art baselines by 9% and 6%, respectively, in reducing knowledge forgetting.
Dynamic DAG Discovery for Interpretable Imitation Learning
Oct 12, 2023



Imitation learning, which learns agent policy by mimicking expert demonstration, has shown promising results in many applications such as medical treatment regimes and self-driving vehicles. However, it remains a difficult task to interpret control policies learned by the agent. Difficulties mainly come from two aspects: 1) agents in imitation learning are usually implemented as deep neural networks, which are black-box models and lack interpretability; 2) the latent causal mechanism behind agents' decisions may vary along the trajectory, rather than staying static throughout time steps. To increase transparency and offer better interpretability of the neural agent, we propose to expose its captured knowledge in the form of a directed acyclic causal graph, with nodes being action and state variables and edges denoting the causal relations behind predictions. Furthermore, we design this causal discovery process to be state-dependent, enabling it to model the dynamics in latent causal graphs. Concretely, we conduct causal discovery from the perspective of Granger causality and propose a self-explainable imitation learning framework, {\method}. The proposed framework is composed of three parts: a dynamic causal discovery module, a causality encoding module, and a prediction module, and is trained in an end-to-end manner. After the model is learned, we can obtain causal relations among states and action variables behind its decisions, exposing policies learned by it. Experimental results on both synthetic and real-world datasets demonstrate the effectiveness of the proposed {\method} in learning the dynamic causal graphs for understanding the decision-making of imitation learning meanwhile maintaining high prediction accuracy.