 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
Apr 09, 2024
The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 x 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 x 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 x 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks. The InternLM-XComposer2-4KHD model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
CasSR: Activating Image Power for Real-World Image Super-Resolution
Mar 18, 2024
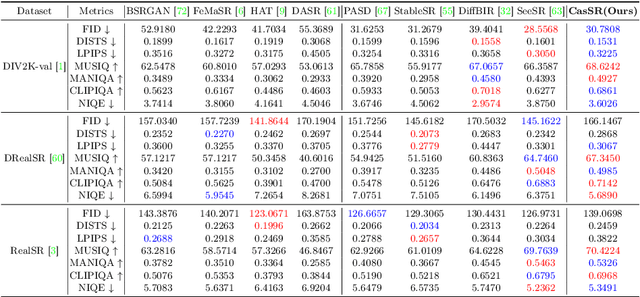


The objective of image super-resolution is to generate clean and high-resolution images from degraded versions. Recent advancements in diffusion modeling have led to the emergence of various image super-resolution techniques that leverage pretrained text-to-image (T2I) models. Nevertheless, due to the prevalent severe degradation in low-resolution images and the inherent characteristics of diffusion models, achieving high-fidelity image restoration remains challenging. Existing methods often exhibit issues including semantic loss, artifacts, and the introduction of spurious content not present in the original image. To tackle this challenge, we propose Cascaded diffusion for Super-Resolution, CasSR , a novel method designed to produce highly detailed and realistic images. In particular, we develop a cascaded controllable diffusion model that aims to optimize the extraction of information from low-resolution images. This model generates a preliminary reference image to facilitate initial information extraction and degradation mitigation. Furthermore, we propose a multi-attention mechanism to enhance the T2I model's capability in maximizing the restoration of the original image content. Through a comprehensive blend of qualitative and quantitative analyses, we substantiate the efficacy and superiority of our approach.
Dynamic Conditional Optimal Transport through Simulation-Free Flows
Apr 05, 2024We study the geometry of conditional optimal transport (COT) and prove a dynamical formulation which generalizes the Benamou-Brenier Theorem. With these tools, we propose a simulation-free flow-based method for conditional generative modeling. Our method couples an arbitrary source distribution to a specified target distribution through a triangular COT plan. We build on the framework of flow matching to train a conditional generative model by approximating the geodesic path of measures induced by this COT plan. Our theory and methods are applicable in the infinite-dimensional setting, making them well suited for inverse problems. Empirically, we demonstrate our proposed method on two image-to-image translation tasks and an infinite-dimensional Bayesian inverse problem.
Enhancing Historical Image Retrieval with Compositional Cues
Mar 21, 2024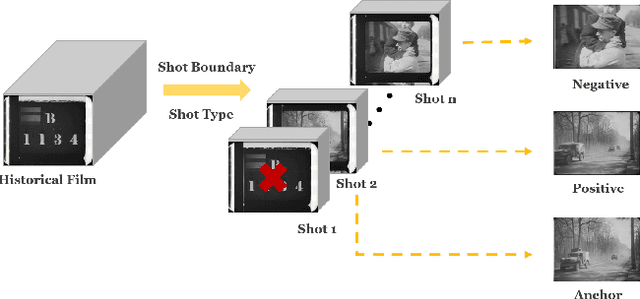

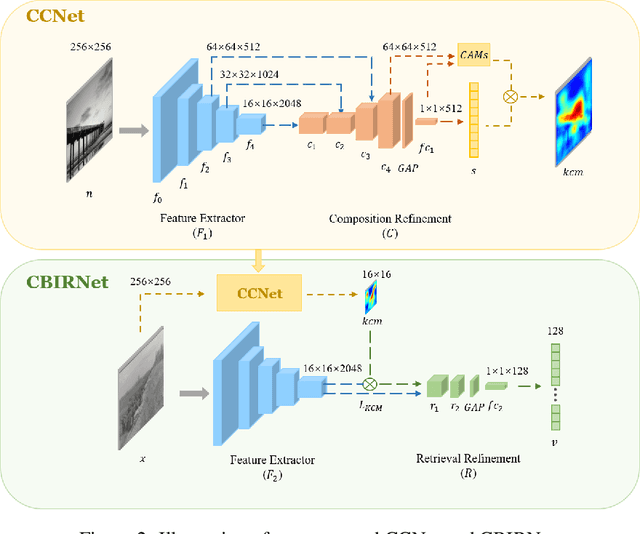
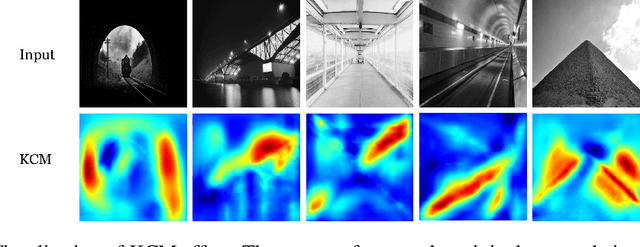
In analyzing vast amounts of digitally stored historical image data, existing content-based retrieval methods often overlook significant non-semantic information, limiting their effectiveness for flexible exploration across varied themes. To broaden the applicability of image retrieval methods for diverse purposes and uncover more general patterns, we innovatively introduce a crucial factor from computational aesthetics, namely image composition, into this topic. By explicitly integrating composition-related information extracted by CNN into the designed retrieval model, our method considers both the image's composition rules and semantic information. Qualitative and quantitative experiments demonstrate that the image retrieval network guided by composition information outperforms those relying solely on content information, facilitating the identification of images in databases closer to the target image in human perception. Please visit https://github.com/linty5/CCBIR to try our codes.
Theoretical Bound-Guided Hierarchical VAE for Neural Image Codecs
Mar 27, 2024Recent studies reveal a significant theoretical link between variational autoencoders (VAEs) and rate-distortion theory, notably in utilizing VAEs to estimate the theoretical upper bound of the information rate-distortion function of images. Such estimated theoretical bounds substantially exceed the performance of existing neural image codecs (NICs). To narrow this gap, we propose a theoretical bound-guided hierarchical VAE (BG-VAE) for NIC. The proposed BG-VAE leverages the theoretical bound to guide the NIC model towards enhanced performance. We implement the BG-VAE using Hierarchical VAEs and demonstrate its effectiveness through extensive experiments. Along with advanced neural network blocks, we provide a versatile, variable-rate NIC that outperforms existing methods when considering both rate-distortion performance and computational complexity. The code is available at BG-VAE.
MedIAnomaly: A comparative study of anomaly detection in medical images
Apr 06, 2024Anomaly detection (AD) aims at detecting abnormal samples that deviate from the expected normal patterns. Generally, it can be trained on merely normal data without the requirement for abnormal samples, and thereby plays an important role in the recognition of rare diseases and health screening in the medical domain. Despite numerous related studies, we observe a lack of a fair and comprehensive evaluation, which causes some ambiguous conclusions and hinders the development of this field. This paper focuses on building a benchmark with unified implementation and comparison to address this problem. In particular, seven medical datasets with five image modalities, including chest X-rays, brain MRIs, retinal fundus images, dermatoscopic images, and histopathology whole slide images are organized for extensive evaluation. Twenty-seven typical AD methods, including reconstruction and self-supervised learning-based methods, are involved in comparison of image-level anomaly classification and pixel-level anomaly segmentation. Furthermore, we for the first time formally explore the effect of key components in existing methods, clearly revealing unresolved challenges and potential future directions. The datasets and code are available at \url{https://github.com/caiyu6666/MedIAnomaly}.
Depth Estimation fusing Image and Radar Measurements with Uncertain Directions
Mar 23, 2024This paper proposes a depth estimation method using radar-image fusion by addressing the uncertain vertical directions of sparse radar measurements. In prior radar-image fusion work, image features are merged with the uncertain sparse depths measured by radar through convolutional layers. This approach is disturbed by the features computed with the uncertain radar depths. Furthermore, since the features are computed with a fully convolutional network, the uncertainty of each depth corresponding to a pixel is spread out over its surrounding pixels. Our method avoids this problem by computing features only with an image and conditioning the features pixelwise with the radar depth. Furthermore, the set of possibly correct radar directions is identified with reliable LiDAR measurements, which are available only in the training stage. Our method improves training data by learning only these possibly correct radar directions, while the previous method trains raw radar measurements, including erroneous measurements. Experimental results demonstrate that our method can improve the quantitative and qualitative results compared with its base method using radar-image fusion.
Unsupervised Intrinsic Image Decomposition with LiDAR Intensity Enhanced Training
Mar 21, 2024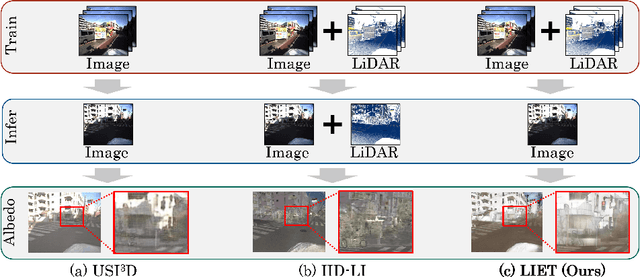
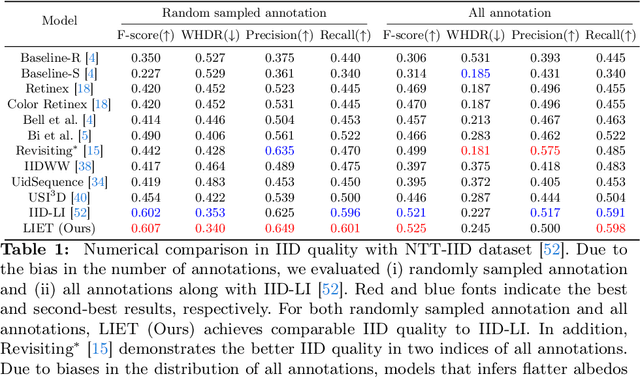


Unsupervised intrinsic image decomposition (IID) is the process of separating a natural image into albedo and shade without these ground truths. A recent model employing light detection and ranging (LiDAR) intensity demonstrated impressive performance, though the necessity of LiDAR intensity during inference restricts its practicality. Thus, IID models employing only a single image during inference while keeping as high IID quality as the one with an image plus LiDAR intensity are highly desired. To address this challenge, we propose a novel approach that utilizes only an image during inference while utilizing an image and LiDAR intensity during training. Specifically, we introduce a partially-shared model that accepts an image and LiDAR intensity individually using a different specific encoder but processes them together in specific components to learn shared representations. In addition, to enhance IID quality, we propose albedo-alignment loss and image-LiDAR conversion (ILC) paths. Albedo-alignment loss aligns the gray-scale albedo from an image to that inferred from LiDAR intensity, thereby reducing cast shadows in albedo from an image due to the absence of cast shadows in LiDAR intensity. Furthermore, to translate the input image into albedo and shade style while keeping the image contents, the input image is separated into style code and content code by encoders. The ILC path mutually translates the image and LiDAR intensity, which share content but differ in style, contributing to the distinct differentiation of style from content. Consequently, LIET achieves comparable IID quality to the existing model with LiDAR intensity, while utilizing only an image without LiDAR intensity during inference.
Pixel-wise RL on Diffusion Models: Reinforcement Learning from Rich Feedback
Apr 05, 2024Latent diffusion models are the state-of-the-art for synthetic image generation. To align these models with human preferences, training the models using reinforcement learning on human feedback is crucial. Black et. al 2024 introduced denoising diffusion policy optimisation (DDPO), which accounts for the iterative denoising nature of the generation by modelling it as a Markov chain with a final reward. As the reward is a single value that determines the model's performance on the entire image, the model has to navigate a very sparse reward landscape and so requires a large sample count. In this work, we extend the DDPO by presenting the Pixel-wise Policy Optimisation (PXPO) algorithm, which can take feedback for each pixel, providing a more nuanced reward to the model.
On the Fly Robotic-Assisted Medical Instrument Planning and Execution Using Mixed Reality
Apr 08, 2024Robotic-assisted medical systems (RAMS) have gained significant attention for their advantages in alleviating surgeons' fatigue and improving patients' outcomes. These systems comprise a range of human-computer interactions, including medical scene monitoring, anatomical target planning, and robot manipulation. However, despite its versatility and effectiveness, RAMS demands expertise in robotics, leading to a high learning cost for the operator. In this work, we introduce a novel framework using mixed reality technologies to ease the use of RAMS. The proposed framework achieves real-time planning and execution of medical instruments by providing 3D anatomical image overlay, human-robot collision detection, and robot programming interface. These features, integrated with an easy-to-use calibration method for head-mounted display, improve the effectiveness of human-robot interactions. To assess the feasibility of the framework, two medical applications are presented in this work: 1) coil placement during transcranial magnetic stimulation and 2) drill and injector device positioning during femoroplasty. Results from these use cases demonstrate its potential to extend to a wider range of medical scenarios.