 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom `May' to `Is': Certainty Distortion in Language Model Rewriting
Jun 06, 2026Humans increasingly turn to Language Models (LMs) in ways that shape beliefs and drive decisions, including discussing, rewriting, and summarizing information from scientific articles, news, and medical reports. However, in these domains, where how confidently a claim is expressed matters, little is known about whether LMs faithfully preserve it. In this work, we investigate certainty distortion in LMs, defined as meaningful changes in expressed certainty when semantic content is preserved. We propose an LM-based evaluation metric that is consistent with population-level judgments of certainty. Using this metric, we characterize certainty distortion across different sizes and families of models in the context of scientific and medical communication tasks. Our results show that certainty distortion affects up to 75\% of LM outputs and is systematically asymmetric in rewriting tasks with most LMs being 1.5-2$\times$ more likely to increase the expressed certainty than to decrease it. These effects can compound over repeated paraphrasing: in the medical domain, claude-haiku-4-5 increases certainty of 20\% examples after a single iteration, increasing to 40\% after five iterations. Prompt-based interventions reduce overall certainty distortion but do not eliminate it. Together, these findings reveal a general bias toward inflating expressed certainty, with direct implications for users who rely on LMs in high-stakes domains.
Learning to Assign Prediction Tasks to Agents with Capacity Constraints
May 27, 2026We address the problem of learning to assign prediction tasks to one agent from a set of available human or AI agents. In particular, we focus on the sequential learning of agent expertise and assignment policies where each agent is constrained to handle a fraction of tasks. We provide a general theoretical characterization of this problem in terms of agent capacities, differences in agent expertise, and task context. We then develop a framework of sequential explore-exploit policy-learning algorithms that seek to maximize overall performance. Experimental results over a variety of tabular, image, and text prediction tasks demonstrate systematic gains from our policy-learning algorithms relative to non-contextual baselines across different types of agents, including LLMs and humans.
The Impact of AI Usage and Informativeness on Skill Development in Logical Reasoning
May 20, 2026Artificial intelligence (AI) is being increasingly integrated into human problem-solving, yet its effects on individual skill development remain unclear. We examine how both AI usage and informativeness can shape learning in the context of a controlled logical reasoning task with on-demand access to AI assistance. We find that greater AI usage is associated with weaker skill development: heavy AI users underperform relative to comparable peers, whereas light AI users perform similarly to matched users who do not use AI. We also find in our study that these patterns are mediated by AI informativeness. Low-information AI neither improves immediate performance nor preserves performance after AI assistance is removed, and is linked to weaker learning overall. On the other hand, high-information AI was found to improve short-run performance without reducing post-AI outcomes on average in our experiments, but with heterogeneous effects. Our findings in general suggest that AI can, depending on context, either complement human skill development by amplifying independent reasoning or can act as a substitute that undermines such reasoning, with the implication that regulating AI access and usage will be important for promoting skill development in the presence of AI assistance.
Bayesian Inference for Correlated Human Experts and Classifiers
Jun 05, 2025



Applications of machine learning often involve making predictions based on both model outputs and the opinions of human experts. In this context, we investigate the problem of querying experts for class label predictions, using as few human queries as possible, and leveraging the class probability estimates of pre-trained classifiers. We develop a general Bayesian framework for this problem, modeling expert correlation via a joint latent representation, enabling simulation-based inference about the utility of additional expert queries, as well as inference of posterior distributions over unobserved expert labels. We apply our approach to two real-world medical classification problems, as well as to CIFAR-10H and ImageNet-16H, demonstrating substantial reductions relative to baselines in the cost of querying human experts while maintaining high prediction accuracy.
Semantic Probabilistic Control of Language Models
May 04, 2025Semantic control entails steering LM generations towards satisfying subtle non-lexical constraints, e.g., toxicity, sentiment, or politeness, attributes that can be captured by a sequence-level verifier. It can thus be viewed as sampling from the LM distribution conditioned on the target attribute, a computationally intractable problem due to the non-decomposable nature of the verifier. Existing approaches to LM control either only deal with syntactic constraints which cannot capture the aforementioned attributes, or rely on sampling to explore the conditional LM distribution, an ineffective estimator for low-probability events. In this work, we leverage a verifier's gradient information to efficiently reason over all generations that satisfy the target attribute, enabling precise steering of LM generations by reweighing the next-token distribution. Starting from an initial sample, we create a local LM distribution favoring semantically similar sentences. This approximation enables the tractable computation of an expected sentence embedding. We use this expected embedding, informed by the verifier's evaluation at the initial sample, to estimate the probability of satisfying the constraint, which directly informs the update to the next-token distribution. We evaluated the effectiveness of our approach in controlling the toxicity, sentiment, and topic-adherence of LMs yielding generations satisfying the constraint with high probability (>95%) without degrading their quality.
Deep Linear Hawkes Processes
Dec 27, 2024Marked temporal point processes (MTPPs) are used to model sequences of different types of events with irregular arrival times, with broad applications ranging from healthcare and social networks to finance. We address shortcomings in existing point process models by drawing connections between modern deep state-space models (SSMs) and linear Hawkes processes (LHPs), culminating in an MTPP that we call the deep linear Hawkes process (DLHP). The DLHP modifies the linear differential equations in deep SSMs to be stochastic jump differential equations, akin to LHPs. After discretizing, the resulting recurrence can be implemented efficiently using a parallel scan. This brings parallelism and linear scaling to MTPP models. This contrasts with attention-based MTPPs, which scale quadratically, and RNN-based MTPPs, which do not parallelize across the sequence length. We show empirically that DLHPs match or outperform existing models across a broad range of metrics on eight real-world datasets. Our proposed DLHP model is the first instance of the unique architectural capabilities of SSMs being leveraged to construct a new class of MTPP models.
Benchmark Data Repositories for Better Benchmarking
Oct 31, 2024



In machine learning research, it is common to evaluate algorithms via their performance on standard benchmark datasets. While a growing body of work establishes guidelines for -- and levies criticisms at -- data and benchmarking practices in machine learning, comparatively less attention has been paid to the data repositories where these datasets are stored, documented, and shared. In this paper, we analyze the landscape of these $\textit{benchmark data repositories}$ and the role they can play in improving benchmarking. This role includes addressing issues with both datasets themselves (e.g., representational harms, construct validity) and the manner in which evaluation is carried out using such datasets (e.g., overemphasis on a few datasets and metrics, lack of reproducibility). To this end, we identify and discuss a set of considerations surrounding the design and use of benchmark data repositories, with a focus on improving benchmarking practices in machine learning.
ELBOing Stein: Variational Bayes with Stein Mixture Inference
Oct 30, 2024



Stein variational gradient descent (SVGD) [Liu and Wang, 2016] performs approximate Bayesian inference by representing the posterior with a set of particles. However, SVGD suffers from variance collapse, i.e. poor predictions due to underestimating uncertainty [Ba et al., 2021], even for moderately-dimensional models such as small Bayesian neural networks (BNNs). To address this issue, we generalize SVGD by letting each particle parameterize a component distribution in a mixture model. Our method, Stein Mixture Inference (SMI), optimizes a lower bound to the evidence (ELBO) and introduces user-specified guides parameterized by particles. SMI extends the Nonlinear SVGD framework [Wang and Liu, 2019] to the case of variational Bayes. SMI effectively avoids variance collapse, judging by a previously described test developed for this purpose, and performs well on standard data sets. In addition, SMI requires considerably fewer particles than SVGD to accurately estimate uncertainty for small BNNs. The synergistic combination of NSVGD, ELBO optimization and user-specified guides establishes a promising approach towards variational Bayesian inference in the case of tall and wide data.
EventFlow: Forecasting Continuous-Time Event Data with Flow Matching
Oct 09, 2024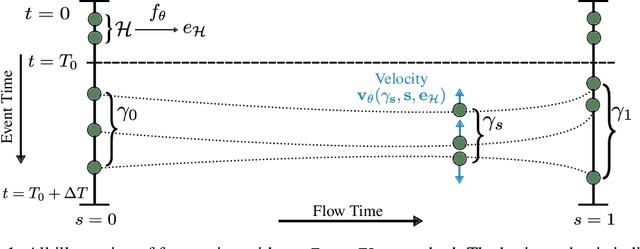
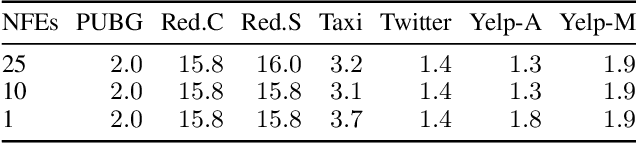
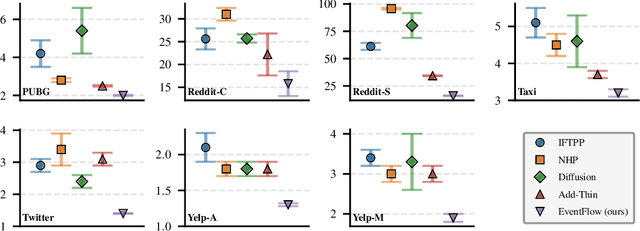
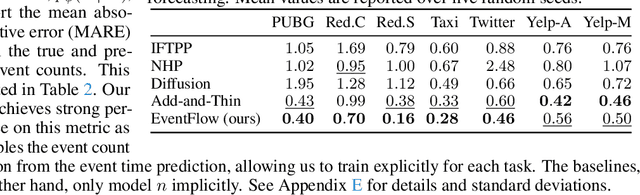
Continuous-time event sequences, in which events occur at irregular intervals, are ubiquitous across a wide range of industrial and scientific domains. The contemporary modeling paradigm is to treat such data as realizations of a temporal point process, and in machine learning it is common to model temporal point processes in an autoregressive fashion using a neural network. While autoregressive models are successful in predicting the time of a single subsequent event, their performance can be unsatisfactory in forecasting longer horizons due to cascading errors. We propose EventFlow, a non-autoregressive generative model for temporal point processes. Our model builds on the flow matching framework in order to directly learn joint distributions over event times, side-stepping the autoregressive process. EventFlow is likelihood-free, easy to implement and sample from, and either matches or surpasses the performance of state-of-the-art models in both unconditional and conditional generation tasks on a set of standard benchmarks
Perceptions of Linguistic Uncertainty by Language Models and Humans
Jul 22, 2024Uncertainty expressions such as ``probably'' or ``highly unlikely'' are pervasive in human language. While prior work has established that there is population-level agreement in terms of how humans interpret these expressions, there has been little inquiry into the abilities of language models to interpret such expressions. In this paper, we investigate how language models map linguistic expressions of uncertainty to numerical responses. Our approach assesses whether language models can employ theory of mind in this setting: understanding the uncertainty of another agent about a particular statement, independently of the model's own certainty about that statement. We evaluate both humans and 10 popular language models on a task created to assess these abilities. Unexpectedly, we find that 8 out of 10 models are able to map uncertainty expressions to probabilistic responses in a human-like manner. However, we observe systematically different behavior depending on whether a statement is actually true or false. This sensitivity indicates that language models are substantially more susceptible to bias based on their prior knowledge (as compared to humans). These findings raise important questions and have broad implications for human-AI alignment and AI-AI communication.