 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Feasibility of Inferring Dietary Behavior Change Receptivity from Egocentric Images of Eating Environment
May 27, 2026Accurately assessing dietary behavior change receptivity is essential for designing effective just-in-time adaptive interventions (JITAIs) that promote healthier eating habits. However, self-report-based assessment of behavior change receptivity is sparse and delayed, limiting its practical use in continuous monitoring. To explore whether passive sensing may help address this challenge, this study conducts a pilot investigation of inferring participants' self-reported behavior change receptivity from egocentric eating images collected by a wearable camera. We use pilot data obtained from free-living eating episodes using the Automatic Ingestion Monitor v2 (AIM-2). The data included egocentric image sequences captured during eating and paired with responses to questions assessing specific dimensions of behavior change receptivity (awareness, interaction capability, and motivation). To examine whether visual information contained any relevancy to these responses, we evaluated a transfer-learning-assisted framework that combines a pre-trained Contrastive Language-Image Pre-Training (CLIP) vision encoder with a lightweight transformer classifier. The model processes eating episode image sequences to extract potential semantic and temporal cues related to behavior change receptivity. Preliminary experimental results show promising improvements over simple baseline models for behavior change receptivity indicators. These early findings suggest that egocentric eating episode images may contain cues related to dietary behavior change receptivity, and warrant further investigation with larger and more comprehensive datasets.
Adaptive Greedy Frame Selection for Long Video Understanding
Mar 20, 2026Large vision--language models (VLMs) are increasingly applied to long-video question answering, yet inference is often bottlenecked by the number of input frames and resulting visual tokens. Naive sparse sampling can miss decisive moments, while purely relevance-driven selection frequently collapses onto near-duplicate frames and sacrifices coverage of temporally distant evidence. We propose a question-adaptive greedy frame selection method that jointly optimizes query relevance and semantic representativeness under a fixed frame budget. Our approach constructs a 1~FPS candidate pool (capped at 1000) with exact timestamp alignment, embeds candidates in two complementary spaces (SigLIP for question relevance and DINOv2 for semantic similarity), and selects frames by greedily maximizing a weighted sum of a modular relevance term and a facility-location coverage term. This objective is normalized, monotone, and submodular, yielding a standard (1-1/e) greedy approximation guarantee. To account for question-dependent trade-offs between relevance and coverage, we introduce four preset strategies and a lightweight text-only question-type classifier that routes each query to its best-performing preset. Experiments on MLVU show consistent accuracy gains over uniform sampling and a strong recent baseline across frame budgets, with the largest improvements under tight budgets.
EntropyGS: An Efficient Entropy Coding on 3D Gaussian Splatting
Aug 13, 2025
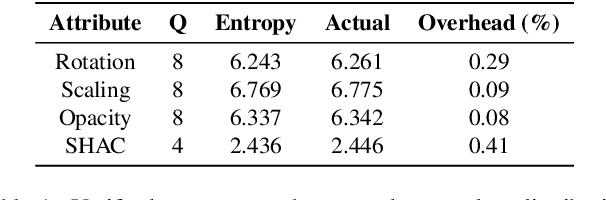
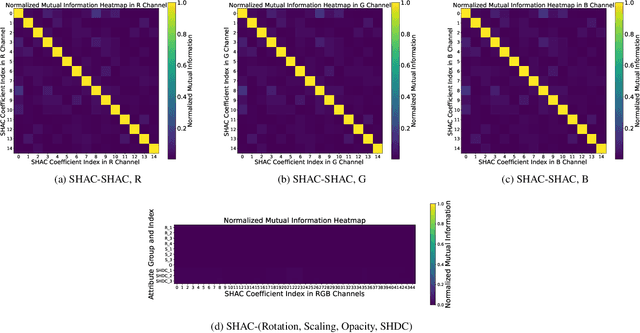
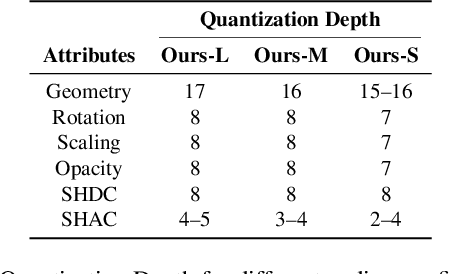
As an emerging novel view synthesis approach, 3D Gaussian Splatting (3DGS) demonstrates fast training/rendering with superior visual quality. The two tasks of 3DGS, Gaussian creation and view rendering, are typically separated over time or devices, and thus storage/transmission and finally compression of 3DGS Gaussians become necessary. We begin with a correlation and statistical analysis of 3DGS Gaussian attributes. An inspiring finding in this work reveals that spherical harmonic AC attributes precisely follow Laplace distributions, while mixtures of Gaussian distributions can approximate rotation, scaling, and opacity. Additionally, harmonic AC attributes manifest weak correlations with other attributes except for inherited correlations from a color space. A factorized and parameterized entropy coding method, EntropyGS, is hereinafter proposed. During encoding, distribution parameters of each Gaussian attribute are estimated to assist their entropy coding. The quantization for entropy coding is adaptively performed according to Gaussian attribute types. EntropyGS demonstrates about 30x rate reduction on benchmark datasets while maintaining similar rendering quality compared to input 3DGS data, with a fast encoding and decoding time.
Low-Rank Adaptation of Pre-trained Vision Backbones for Energy-Efficient Image Coding for Machine
May 23, 2025Image Coding for Machines (ICM) focuses on optimizing image compression for AI-driven analysis rather than human perception. Existing ICM frameworks often rely on separate codecs for specific tasks, leading to significant storage requirements, training overhead, and computational complexity. To address these challenges, we propose an energy-efficient framework that leverages pre-trained vision backbones to extract robust and versatile latent representations suitable for multiple tasks. We introduce a task-specific low-rank adaptation mechanism, which refines the pre-trained features to be both compressible and tailored to downstream applications. This design minimizes trainable parameters and reduces energy costs for multi-task scenarios. By jointly optimizing task performance and entropy minimization, our method enables efficient adaptation to diverse tasks and datasets without full fine-tuning, achieving high coding efficiency. Extensive experiments demonstrate that our framework significantly outperforms traditional codecs and pre-processors, offering an energy-efficient and effective solution for ICM applications. The code and the supplementary materials will be available at: https://gitlab.com/viper-purdue/efficient-compression.
Accelerating Learned Image Compression Through Modeling Neural Training Dynamics
May 23, 2025As learned image compression (LIC) methods become increasingly computationally demanding, enhancing their training efficiency is crucial. This paper takes a step forward in accelerating the training of LIC methods by modeling the neural training dynamics. We first propose a Sensitivity-aware True and Dummy Embedding Training mechanism (STDET) that clusters LIC model parameters into few separate modes where parameters are expressed as affine transformations of reference parameters within the same mode. By further utilizing the stable intra-mode correlations throughout training and parameter sensitivities, we gradually embed non-reference parameters, reducing the number of trainable parameters. Additionally, we incorporate a Sampling-then-Moving Average (SMA) technique, interpolating sampled weights from stochastic gradient descent (SGD) training to obtain the moving average weights, ensuring smooth temporal behavior and minimizing training state variances. Overall, our method significantly reduces training space dimensions and the number of trainable parameters without sacrificing model performance, thus accelerating model convergence. We also provide a theoretical analysis on the Noisy quadratic model, showing that the proposed method achieves a lower training variance than standard SGD. Our approach offers valuable insights for further developing efficient training methods for LICs.
Balanced Rate-Distortion Optimization in Learned Image Compression
Feb 27, 2025Learned image compression (LIC) using deep learning architectures has seen significant advancements, yet standard rate-distortion (R-D) optimization often encounters imbalanced updates due to diverse gradients of the rate and distortion objectives. This imbalance can lead to suboptimal optimization, where one objective dominates, thereby reducing overall compression efficiency. To address this challenge, we reformulate R-D optimization as a multi-objective optimization (MOO) problem and introduce two balanced R-D optimization strategies that adaptively adjust gradient updates to achieve more equitable improvements in both rate and distortion. The first proposed strategy utilizes a coarse-to-fine gradient descent approach along standard R-D optimization trajectories, making it particularly suitable for training LIC models from scratch. The second proposed strategy analytically addresses the reformulated optimization as a quadratic programming problem with an equality constraint, which is ideal for fine-tuning existing models. Experimental results demonstrate that both proposed methods enhance the R-D performance of LIC models, achieving around a 2\% BD-Rate reduction with acceptable additional training cost, leading to a more balanced and efficient optimization process. The code will be made publicly available.
Deep Learning-Based Feature Fusion for Emotion Analysis and Suicide Risk Differentiation in Chinese Psychological Support Hotlines
Jan 15, 2025



Mental health is a critical global public health issue, and psychological support hotlines play a pivotal role in providing mental health assistance and identifying suicide risks at an early stage. However, the emotional expressions conveyed during these calls remain underexplored in current research. This study introduces a method that combines pitch acoustic features with deep learning-based features to analyze and understand emotions expressed during hotline interactions. Using data from China's largest psychological support hotline, our method achieved an F1-score of 79.13% for negative binary emotion classification.Additionally, the proposed approach was validated on an open dataset for multi-class emotion classification,where it demonstrated better performance compared to the state-of-the-art methods. To explore its clinical relevance, we applied the model to analysis the frequency of negative emotions and the rate of emotional change in the conversation, comparing 46 subjects with suicidal behavior to those without. While the suicidal group exhibited more frequent emotional changes than the non-suicidal group, the difference was not statistically significant.Importantly, our findings suggest that emotional fluctuation intensity and frequency could serve as novel features for psychological assessment scales and suicide risk prediction.The proposed method provides valuable insights into emotional dynamics and has the potential to advance early intervention and improve suicide prevention strategies through integration with clinical tools and assessments The source code is publicly available at https://github.com/Sco-field/Speechemotionrecognition/tree/main.
Towards Reproducible Learning-based Compression
Oct 13, 2024



A deep learning system typically suffers from a lack of reproducibility that is partially rooted in hardware or software implementation details. The irreproducibility leads to skepticism in deep learning technologies and it can hinder them from being deployed in many applications. In this work, the irreproducibility issue is analyzed where deep learning is employed in compression systems while the encoding and decoding may be run on devices from different manufacturers. The decoding process can even crash due to a single bit difference, e.g., in a learning-based entropy coder. For a given deep learning-based module with limited resources for protection, we first suggest that reproducibility can only be assured when the mismatches are bounded. Then a safeguarding mechanism is proposed to tackle the challenges. The proposed method may be applied for different levels of protection either at the reconstruction level or at a selected decoding level. Furthermore, the overhead introduced for the protection can be scaled down accordingly when the error bound is being suppressed. Experiments demonstrate the effectiveness of the proposed approach for learning-based compression systems, e.g., in image compression and point cloud compression.
Automatic Recognition of Food Ingestion Environment from the AIM-2 Wearable Sensor
May 13, 2024



Detecting an ingestion environment is an important aspect of monitoring dietary intake. It provides insightful information for dietary assessment. However, it is a challenging problem where human-based reviewing can be tedious, and algorithm-based review suffers from data imbalance and perceptual aliasing problems. To address these issues, we propose a neural network-based method with a two-stage training framework that tactfully combines fine-tuning and transfer learning techniques. Our method is evaluated on a newly collected dataset called ``UA Free Living Study", which uses an egocentric wearable camera, AIM-2 sensor, to simulate food consumption in free-living conditions. The proposed training framework is applied to common neural network backbones, combined with approaches in the general imbalanced classification field. Experimental results on the collected dataset show that our proposed method for automatic ingestion environment recognition successfully addresses the challenging data imbalance problem in the dataset and achieves a promising overall classification accuracy of 96.63%.
Flexible Variable-Rate Image Feature Compression for Edge-Cloud Systems
Mar 30, 2024



Feature compression is a promising direction for coding for machines. Existing methods have made substantial progress, but they require designing and training separate neural network models to meet different specifications of compression rate, performance accuracy and computational complexity. In this paper, a flexible variable-rate feature compression method is presented that can operate on a range of rates by introducing a rate control parameter as an input to the neural network model. By compressing different intermediate features of a pre-trained vision task model, the proposed method can scale the encoding complexity without changing the overall size of the model. The proposed method is more flexible than existing baselines, at the same time outperforming them in terms of the three-way trade-off between feature compression rate, vision task accuracy, and encoding complexity. We have made the source code available at https://github.com/adnan-hossain/var_feat_comp.git.