 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Photo Cropper and Enhancer
Aug 03, 2020
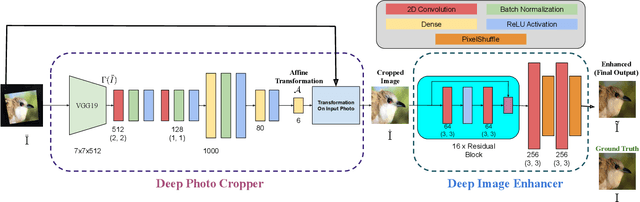


This paper introduces a new type of image enhancement problem. Compared to traditional image enhancement methods, which mostly deal with pixel-wise modifications of a given photo, our proposed task is to crop an image which is embedded within a photo and enhance the quality of the cropped image. We split our proposed approach into two deep networks: deep photo cropper and deep image enhancer. In the photo cropper network, we employ a spatial transformer to extract the embedded image. In the photo enhancer, we employ super-resolution to increase the number of pixels in the embedded image and reduce the effect of stretching and distortion of pixels. We use cosine distance loss between image features and ground truth for the cropper and the mean square loss for the enhancer. Furthermore, we propose a new dataset to train and test the proposed method. Finally, we analyze the proposed method with respect to qualitative and quantitative evaluations.
Wider Channel Attention Network for Remote Sensing Image Super-resolution
Jan 02, 2019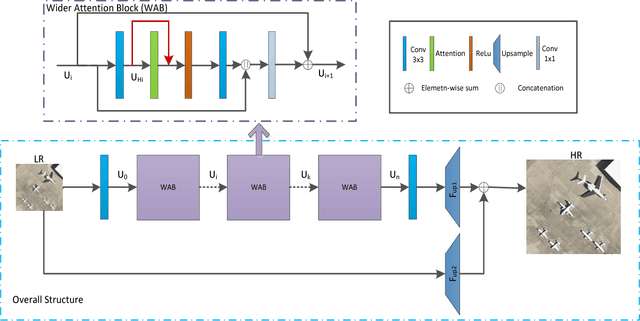



Recently, deep convolutional neural networks (CNNs) have obtained promising results in image processing tasks including super-resolution (SR). However, most CNN-based SR methods treat low-resolution (LR) inputs and features equally across channels, rarely notice the loss of information flow caused by the activation function and fail to leverage the representation ability of CNNs. In this letter, we propose a novel single-image super-resolution (SISR) algorithm named Wider Channel Attention Network (WCAN) for remote sensing images. Firstly, the channel attention mechanism is used to adaptively recalibrate the importance of each channel at the middle of the wider attention block (WAB). Secondly, we propose the Local Memory Connection (LMC) to enhance the information flow. Finally, the features within each WAB are fused to take advantage of the network's representation capability and further improve information and gradient flow. Analytic experiments on a public remote sensing data set (UC Merced) show that our WCAN achieves better accuracy and visual improvements against most state-of-the-art methods.
Evaluating ResNeXt Model Architecture for Image Classification
May 09, 2018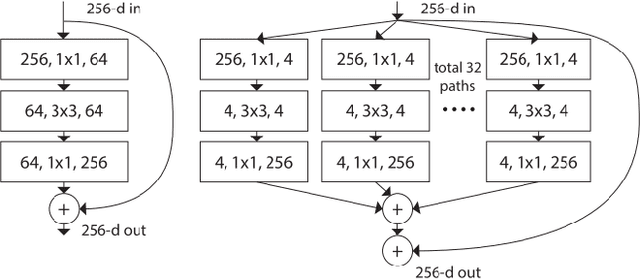
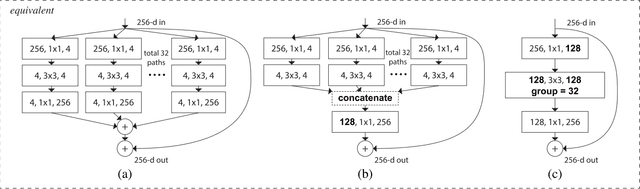
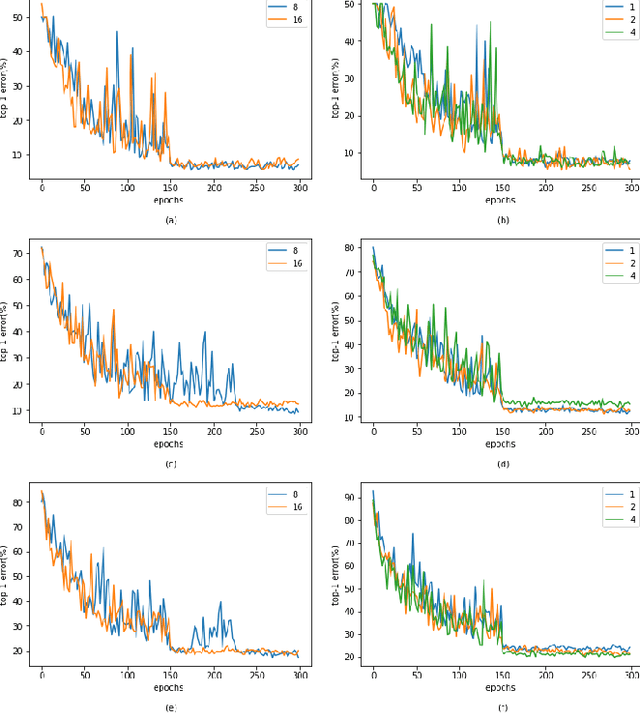
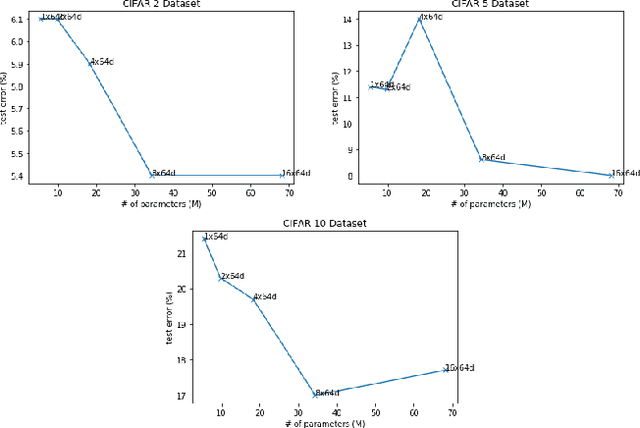
In recent years, deep learning methods have been successfully applied to image classification tasks. Many such deep neural networks exist today that can easily differentiate cats from dogs. One such model is the ResNeXt model that uses a homogeneous, multi-branch architecture for image classification. This paper aims at implementing and evaluating the ResNeXt model architecture on subsets of the CIFAR-10 dataset. It also tweaks the original ResNeXt hyper-parameters such as cardinality, depth and base-width and compares the performance of the modified model with the original. Analysis of the experiments performed in this paper show that a slight decrease in depth or base-width does not affect the performance of the model much leading to comparable results.
2018 Low-Power Image Recognition Challenge
Oct 03, 2018The Low-Power Image Recognition Challenge (LPIRC, https://rebootingcomputing.ieee.org/lpirc) is an annual competition started in 2015. The competition identifies the best technologies that can classify and detect objects in images efficiently (short execution time and low energy consumption) and accurately (high precision). Over the four years, the winners' scores have improved more than 24 times. As computer vision is widely used in many battery-powered systems (such as drones and mobile phones), the need for low-power computer vision will become increasingly important. This paper summarizes LPIRC 2018 by describing the three different tracks and the winners' solutions.
Stateless Neural Meta-Learning using Second-Order Gradients
Apr 21, 2021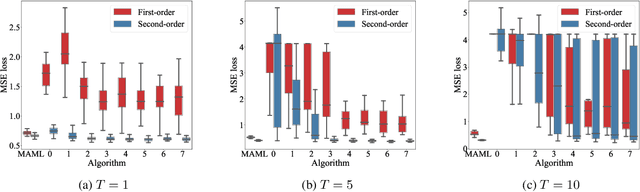
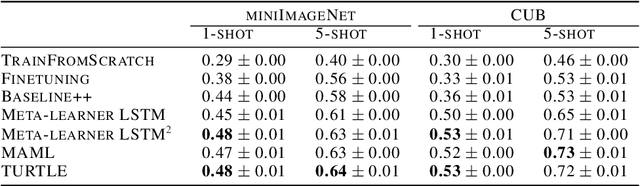
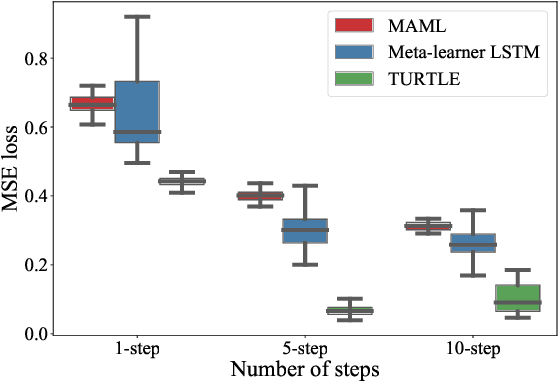
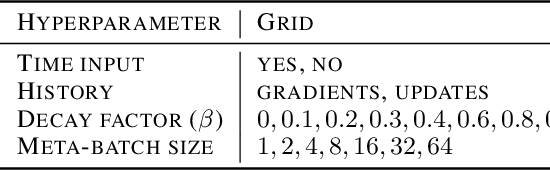
Deep learning typically requires large data sets and much compute power for each new problem that is learned. Meta-learning can be used to learn a good prior that facilitates quick learning, thereby relaxing these requirements so that new tasks can be learned quicker; two popular approaches are MAML and the meta-learner LSTM. In this work, we compare the two and formally show that the meta-learner LSTM subsumes MAML. Combining this insight with recent empirical findings, we construct a new algorithm (dubbed TURTLE) which is simpler than the meta-learner LSTM yet more expressive than MAML. TURTLE outperforms both techniques at few-shot sine wave regression and image classification on miniImageNet and CUB without any additional hyperparameter tuning, at a computational cost that is comparable with second-order MAML. The key to TURTLE's success lies in the use of second-order gradients, which also significantly increases the performance of the meta-learner LSTM by 1-6% accuracy.
Gated Fusion Network for Single Image Dehazing
Mar 31, 2018

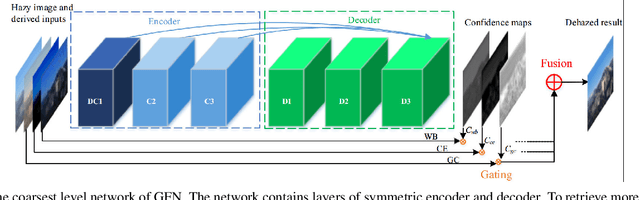

In this paper, we propose an efficient algorithm to directly restore a clear image from a hazy input. The proposed algorithm hinges on an end-to-end trainable neural network that consists of an encoder and a decoder. The encoder is exploited to capture the context of the derived input images, while the decoder is employed to estimate the contribution of each input to the final dehazed result using the learned representations attributed to the encoder. The constructed network adopts a novel fusion-based strategy which derives three inputs from an original hazy image by applying White Balance (WB), Contrast Enhancing (CE), and Gamma Correction (GC). We compute pixel-wise confidence maps based on the appearance differences between these different inputs to blend the information of the derived inputs and preserve the regions with pleasant visibility. The final dehazed image is yielded by gating the important features of the derived inputs. To train the network, we introduce a multi-scale approach such that the halo artifacts can be avoided. Extensive experimental results on both synthetic and real-world images demonstrate that the proposed algorithm performs favorably against the state-of-the-art algorithms.
An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery
May 10, 2021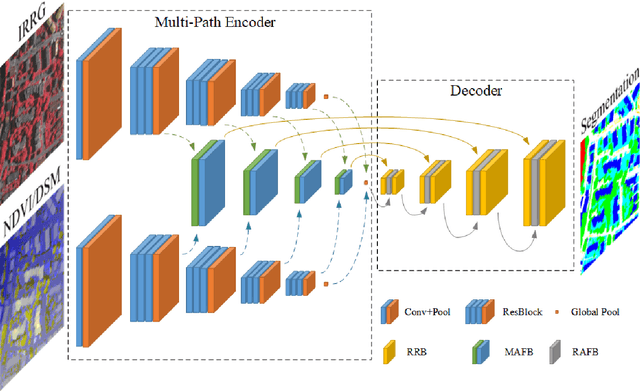
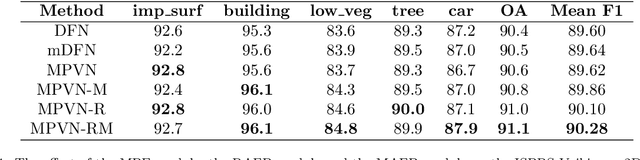
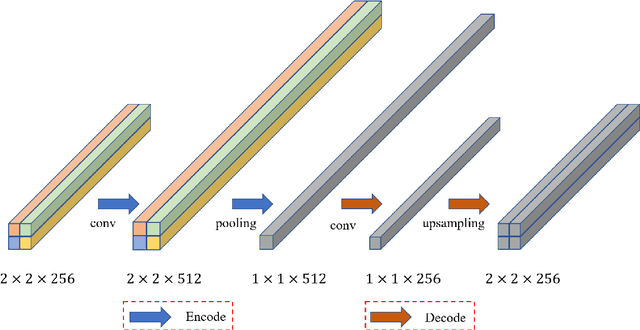
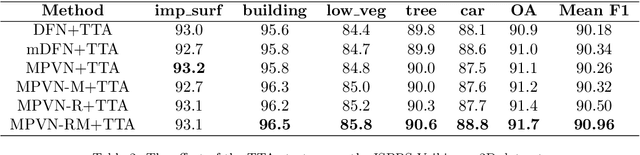
Semantic segmentation is an essential part of deep learning. In recent years, with the development of remote sensing big data, semantic segmentation has been increasingly used in remote sensing. Deep convolutional neural networks (DCNNs) face the challenge of feature fusion: very-high-resolution remote sensing image multisource data fusion can increase the network's learnable information, which is conducive to correctly classifying target objects by DCNNs; simultaneously, the fusion of high-level abstract features and low-level spatial features can improve the classification accuracy at the border between target objects. In this paper, we propose a multipath encoder structure to extract features of multipath inputs, a multipath attention-fused block module to fuse multipath features, and a refinement attention-fused block module to fuse high-level abstract features and low-level spatial features. Furthermore, we propose a novel convolutional neural network architecture, named attention-fused network (AFNet). Based on our AFNet, we achieve state-of-the-art performance with an overall accuracy of 91.7% and a mean F1 score of 90.96% on the ISPRS Vaihingen 2D dataset and an overall accuracy of 92.1% and a mean F1 score of 93.44% on the ISPRS Potsdam 2D dataset.
Face Recognition Using $Sf_{3}CNN$ With Higher Feature Discrimination
Feb 02, 2021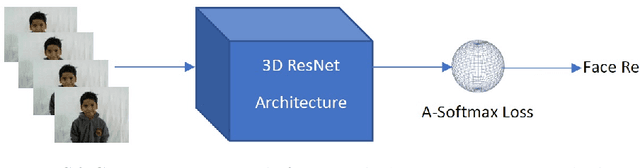
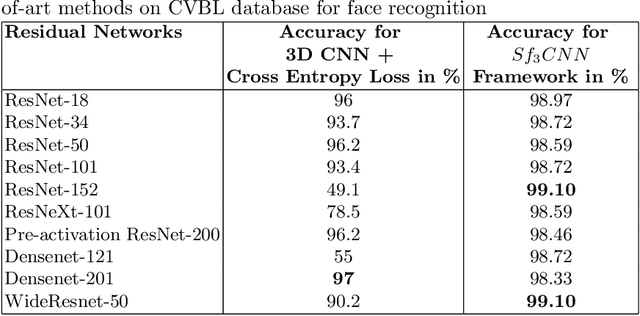
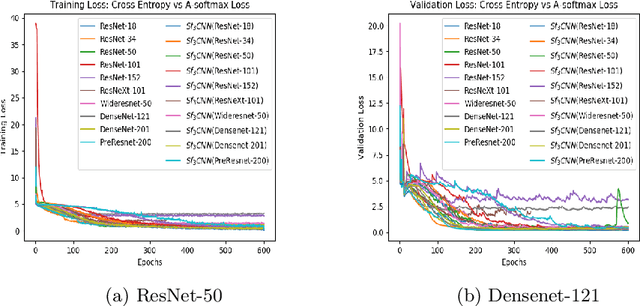
With the advent of 2-dimensional Convolution Neural Networks (2D CNNs), the face recognition accuracy has reached above 99%. However, face recognition is still a challenge in real world conditions. A video, instead of an image, as an input can be more useful to solve the challenges of face recognition in real world conditions. This is because a video provides more features than an image. However, 2D CNNs cannot take advantage of the temporal features present in the video. We therefore, propose a framework called $Sf_{3}CNN$ for face recognition in videos. The $Sf_{3}CNN$ framework uses 3-dimensional Residual Network (3D Resnet) and A-Softmax loss for face recognition in videos. The use of 3D ResNet helps to capture both spatial and temporal features into one compact feature map. However, the 3D CNN features must be highly discriminative for efficient face recognition. The use of A-Softmax loss helps to extract highly discriminative features from the video for face recognition. $Sf_{3}CNN$ framework gives an increased accuracy of 99.10% on CVBL video database in comparison to the previous 97% on the same database using 3D ResNets.
Proactive Pseudo-Intervention: Causally Informed Contrastive Learning For Interpretable Vision Models
Dec 06, 2020

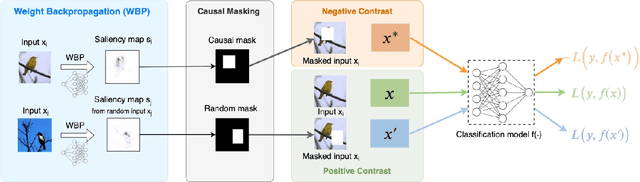
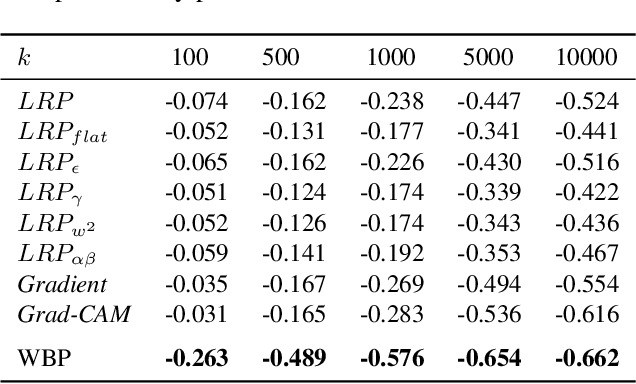
Deep neural networks have shown significant promise in comprehending complex visual signals, delivering performance on par or even superior to that of human experts. However, these models often lack a mechanism for interpreting their predictions, and in some cases, particularly when the sample size is small, existing deep learning solutions tend to capture spurious correlations that compromise model generalizability on unseen inputs. In this work, we propose a contrastive causal representation learning strategy that leverages proactive interventions to identify causally-relevant image features, called Proactive Pseudo-Intervention (PPI). This approach is complemented with a causal salience map visualization module, i.e., Weight Back Propagation (WBP), that identifies important pixels in the raw input image, which greatly facilitates the interpretability of predictions. To validate its utility, our model is benchmarked extensively on both standard natural images and challenging medical image datasets. We show this new contrastive causal representation learning model consistently improves model performance relative to competing solutions, particularly for out-of-domain predictions or when dealing with data integration from heterogeneous sources. Further, our causal saliency maps are more succinct and meaningful relative to their non-causal counterparts.
Quantum Optical Convolutional Neural Network: A Novel Image Recognition Framework for Quantum Computing
Dec 19, 2020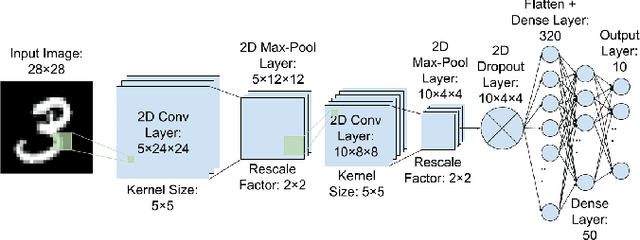
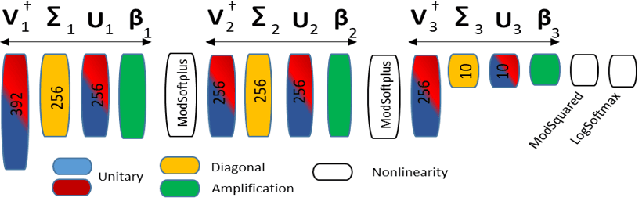
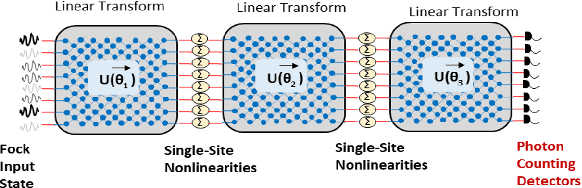
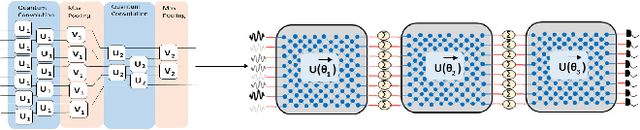
Large machine learning models based on Convolutional Neural Networks (CNNs) with rapidly increasing number of parameters, trained with massive amounts of data, are being deployed in a wide array of computer vision tasks from self-driving cars to medical imaging. The insatiable demand for computing resources required to train these models is fast outpacing the advancement of classical computing hardware, and new frameworks including Optical Neural Networks (ONNs) and quantum computing are being explored as future alternatives. In this work, we report a novel quantum computing based deep learning model, the Quantum Optical Convolutional Neural Network (QOCNN), to alleviate the computational bottleneck in future computer vision applications. Using the popular MNIST dataset, we have benchmarked this new architecture against a traditional CNN based on the seminal LeNet model. We have also compared the performance with previously reported ONNs, namely the GridNet and ComplexNet, as well as a Quantum Optical Neural Network (QONN) that we built by combining the ComplexNet with quantum based sinusoidal nonlinearities. In essence, our work extends the prior research on QONN by adding quantum convolution and pooling layers preceding it. We have evaluated all the models by determining their accuracies, confusion matrices, Receiver Operating Characteristic (ROC) curves, and Matthews Correlation Coefficients. The performance of the models were similar overall, and the ROC curves indicated that the new QOCNN model is robust. Finally, we estimated the gains in computational efficiencies from executing this novel framework on a quantum computer. We conclude that switching to a quantum computing based approach to deep learning may result in comparable accuracies to classical models, while achieving unprecedented boosts in computational performances and drastic reduction in power consumption.