 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModularized Reinforcement Learning on LLMs: From MDP Creation to Exploration and Learning
Jun 20, 2026Reinforcement learning (RL) has become central to LLM post-training, yet the methods that dominate current pipelines, PPO and GRPO, represent only a narrow slice of what RL offers. Understanding why these methods prevail, and what alternatives exist, requires a principled examination of the design decisions that underlie any RL algorithm. This survey organizes that examination around three stages of algorithm construction. We begin with MDP creation: how the reward function, state space, action space, termination condition, and discount factor are, or could be, defined for LLM training. We then turn to exploration, covering temperature sampling, entropy regularization, intrinsic motivation, tree search, and curriculum learning. Finally, we address learning along four classical RL dimensions: model-free versus model-based, value-based versus policy-based versus actor-critic, on-policy versus off-policy, and credit assignment, including both Monte Carlo methods, which rely on full return estimates, and bootstrapping methods, which update estimates using other learned predictions. Mapping the LLM literature onto this taxonomy reveals a strikingly non-uniform distribution of research effort. Critic-free policy gradients and Monte Carlo credit assignment are densely populated, while value-based methods, off-policy actor-critic training, and bootstrapping-based credit assignment remain largely unexplored despite well-established counterparts in classical RL. These gaps represent concrete opportunities for transferring proven RL techniques to LLM training. By making these gaps explicit alongside the methods that have proven effective, this survey offers researchers in both RL and LLMs a shared framework for understanding current practice and identifying promising directions for future work.
Learning to Prompt: Improving Student Engagement with Adaptive LLM-based High-School Tutoring
Jun 18, 2026LLMs can personalize education, although current static-prompt tutoring systems struggle to adapt to diverse academic disciplines. We develop and test a system with subject-aware prompting, based on 14 pedagogical features (e.g., tutor scaffolding, student understanding) extracted from raw transcripts. We first train a prompt routing model in a simulation environment, and then deploy it for online adaptation with actual high-school students. The simulation benchmark shows the router outperforming two static baselines ($0.694$ vs. $0.647$ and $0.64$, $p<0.001$). A/B testing ($N=656$ conversations from 359 students) shows sim-to-real transfer where the model switches from analytical to scaffolding learning strategies. Our adaptive prompt selection mechanism improves instructional efficiency, maintains pedagogical quality and reduces interactions by around 3 turns ($p=0.007$). While a greedy router achieves a comparable exercise conversion rate with the baseline ($19.1\%$ vs. $19.6\%$), a stochastic router that samples strategies leads to a higher conversion rate ($28.1\%$).
Every Component is a Lookup: Token Attribution and Composition from a Single Decomposition
May 22, 2026Mechanistic interpretability of transformers requires identifying not just which components matter but how they compose into the computational route that produced a prediction. Both attention and MLP follow a shared key-value template $φ(S)U$. We exploit this structure to develop Unpack, a backward recursion that decomposes credit through both sublayers, producing interaction strengths between any two components, named end-to-end paths with K/Q/V composition labels, and per-token attribution from a single forward pass, without intervention, gradients, or auxiliary training. We evaluate on the indirect object identification task. On GPT-2 small, the method recovers all three composition connections described by Wang et al. (2023), including the mode-specific routing of each connection (K, Q, or V). To test token-level attribution beyond trivial copying, we compare two occurrences of the same name in the same decomposition: the first mention retains strong credit while the duplicate-detection position is suppressed, a pattern absent in matched control prompts. Across the Pythia family from 160M to 6.9B parameters, this suppression pattern is consistently recovered at every scale, demonstrating that the method tracks mechanistic structure without ground-truth circuit labels. Code is available at https://github.com/Fun-Cry/unpacklm.
Assessing Reproducibility in Evolutionary Computation: A Case Study using Human- and LLM-based Assessment
Feb 05, 2026Reproducibility is an important requirement in evolutionary computation, where results largely depend on computational experiments. In practice, reproducibility relies on how algorithms, experimental protocols, and artifacts are documented and shared. Despite growing awareness, there is still limited empirical evidence on the actual reproducibility levels of published work in the field. In this paper, we study the reproducibility practices in papers published in the Evolutionary Combinatorial Optimization and Metaheuristics track of the Genetic and Evolutionary Computation Conference over a ten-year period. We introduce a structured reproducibility checklist and apply it through a systematic manual assessment of the selected corpus. In addition, we propose RECAP (REproducibility Checklist Automation Pipeline), an LLM-based system that automatically evaluates reproducibility signals from paper text and associated code repositories. Our analysis shows that papers achieve an average completeness score of 0.62, and that 36.90% of them provide additional material beyond the manuscript itself. We demonstrate that automated assessment is feasible: RECAP achieves substantial agreement with human evaluators (Cohen's k of 0.67). Together, these results highlight persistent gaps in reproducibility reporting and suggest that automated tools can effectively support large-scale, systematic monitoring of reproducibility practices.
Mirror Mode in Fire Emblem: Beating Players at their own Game with Imitation and Reinforcement Learning
Dec 10, 2025Enemy strategies in turn-based games should be surprising and unpredictable. This study introduces Mirror Mode, a new game mode where the enemy AI mimics the personal strategy of a player to challenge them to keep changing their gameplay. A simplified version of the Nintendo strategy video game Fire Emblem Heroes has been built in Unity, with a Standard Mode and a Mirror Mode. Our first set of experiments find a suitable model for the task to imitate player demonstrations, using Reinforcement Learning and Imitation Learning: combining Generative Adversarial Imitation Learning, Behavioral Cloning, and Proximal Policy Optimization. The second set of experiments evaluates the constructed model with player tests, where models are trained on demonstrations provided by participants. The gameplay of the participants indicates good imitation in defensive behavior, but not in offensive strategies. Participant's surveys indicated that they recognized their own retreating tactics, and resulted in an overall higher player-satisfaction for Mirror Mode. Refining the model further may improve imitation quality and increase player's satisfaction, especially when players face their own strategies. The full code and survey results are stored at: https://github.com/YannaSmid/MirrorMode
A Unified Framework for Zero-Shot Reinforcement Learning
Oct 23, 2025Zero-shot reinforcement learning (RL) has emerged as a setting for developing general agents in an unsupervised manner, capable of solving downstream tasks without additional training or planning at test-time. Unlike conventional RL, which optimizes policies for a fixed reward, zero-shot RL requires agents to encode representations rich enough to support immediate adaptation to any objective, drawing parallels to vision and language foundation models. Despite growing interest, the field lacks a common analytical lens. We present the first unified framework for zero-shot RL. Our formulation introduces a consistent notation and taxonomy that organizes existing approaches and allows direct comparison between them. Central to our framework is the classification of algorithms into two families: direct representations, which learn end-to-end mappings from rewards to policies, and compositional representations, which decompose the representation leveraging the substructure of the value function. Within this framework, we highlight shared principles and key differences across methods, and we derive an extended bound for successor-feature methods, offering a new perspective on their performance in the zero-shot regime. By consolidating existing work under a common lens, our framework provides a principled foundation for future research in zero-shot RL and outlines a clear path toward developing more general agents.
Analysis of Bluffing by DQN and CFR in Leduc Hold'em Poker
Sep 04, 2025
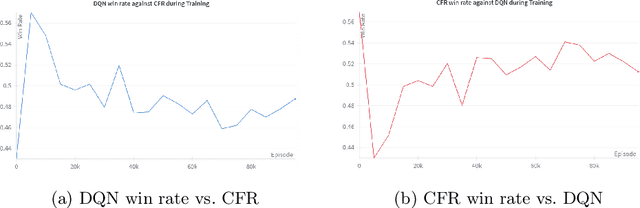
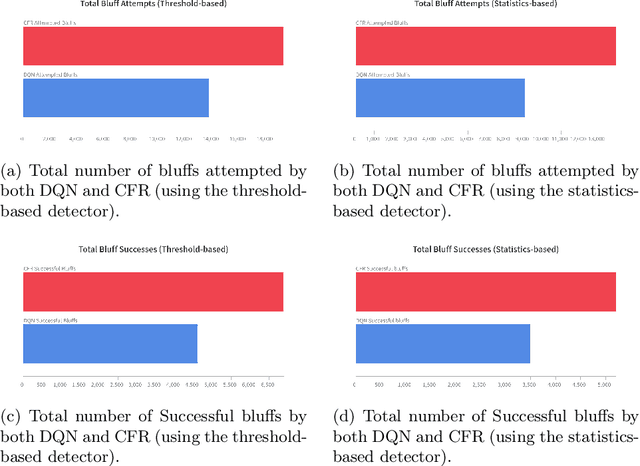
In the game of poker, being unpredictable, or bluffing, is an essential skill. When humans play poker, they bluff. However, most works on computer-poker focus on performance metrics such as win rates, while bluffing is overlooked. In this paper we study whether two popular algorithms, DQN (based on reinforcement learning) and CFR (based on game theory), exhibit bluffing behavior in Leduc Hold'em, a simplified version of poker. We designed an experiment where we let the DQN and CFR agent play against each other while we log their actions. We find that both DQN and CFR exhibit bluffing behavior, but they do so in different ways. Although both attempt to perform bluffs at different rates, the percentage of successful bluffs (where the opponent folds) is roughly the same. This suggests that bluffing is an essential aspect of the game, not of the algorithm. Future work should look at different bluffing styles and at the full game of poker. Code at https://github.com/TarikZ03/Bluffing-by-DQN-and-CFR-in-Leduc-Hold-em-Poker-Codebase.
Pluri-perspectivism in Human-robot Co-creativity with Older Adults
Jul 10, 2025



This position paper explores pluriperspectivism as a core element of human creative experience and its relevance to humanrobot cocreativity We propose a layered fivedimensional model to guide the design of cocreative behaviors and the analysis of interaction dynamics This model is based on literature and results from an interview study we conducted with 10 visual artists and 8 arts educators examining how pluriperspectivism supports creative practice The findings of this study provide insight in how robots could enhance human creativity through adaptive contextsensitive behavior demonstrating the potential of pluriperspectivism This paper outlines future directions for integrating pluriperspectivism with visionlanguage models VLMs to support context sensitivity in cocreative robots
Chargax: A JAX Accelerated EV Charging Simulator
Jul 02, 2025Deep Reinforcement Learning can play a key role in addressing sustainable energy challenges. For instance, many grid systems are heavily congested, highlighting the urgent need to enhance operational efficiency. However, reinforcement learning approaches have traditionally been slow due to the high sample complexity and expensive simulation requirements. While recent works have effectively used GPUs to accelerate data generation by converting environments to JAX, these works have largely focussed on classical toy problems. This paper introduces Chargax, a JAX-based environment for realistic simulation of electric vehicle charging stations designed for accelerated training of RL agents. We validate our environment in a variety of scenarios based on real data, comparing reinforcement learning agents against baselines. Chargax delivers substantial computational performance improvements of over 100x-1000x over existing environments. Additionally, Chargax' modular architecture enables the representation of diverse real-world charging station configurations.
Baba is LLM: Reasoning in a Game with Dynamic Rules
Jun 23, 2025



Large language models (LLMs) are known to perform well on language tasks, but struggle with reasoning tasks. This paper explores the ability of LLMs to play the 2D puzzle game Baba is You, in which players manipulate rules by rearranging text blocks that define object properties. Given that this rule-manipulation relies on language abilities and reasoning, it is a compelling challenge for LLMs. Six LLMs are evaluated using different prompt types, including (1) simple, (2) rule-extended and (3) action-extended prompts. In addition, two models (Mistral, OLMo) are finetuned using textual and structural data from the game. Results show that while larger models (particularly GPT-4o) perform better in reasoning and puzzle solving, smaller unadapted models struggle to recognize game mechanics or apply rule changes. Finetuning improves the ability to analyze the game levels, but does not significantly improve solution formulation. We conclude that even for state-of-the-art and finetuned LLMs, reasoning about dynamic rule changes is difficult (specifically, understanding the use-mention distinction). The results provide insights into the applicability of LLMs to complex problem-solving tasks and highlight the suitability of games with dynamically changing rules for testing reasoning and reflection by LLMs.