 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPLE: Latent Multi-Agent Play for End-to-End Autonomous Driving
May 13, 2026Vision-language-action (VLA) models are effective as end-to-end motion planners, but can be brittle when evaluated in closed-loop settings due to being trained under traditional imitation learning framework. Existing closed-loop supervision approaches lack scalability and fail to completely model a reactive environment. We propose MAPLE, a novel framework for reactive, multi-agent rollout of a dynamic driving scenario in the latent space of the VLA model. The ego vehicle and nearby traffic agents are independently controlled over multi-step horizons, while being reactive to other agents in the scene, enabling closed-loop training. MAPLE consists of two training stages: (1) supervised fine-tuning on the latent rollouts based on ground-truth trajectories, followed by (2) reinforcement learning with global and agent -specific rewards that encourage safety, progress, and interaction realism. We further propose diversity rewards that encourage the model to generate planning behaviors that may not be present in logged driving data. Notably, our closed-loop training framework is scalable and does not require external simulators, which can be computationally expensive to run and have limited visual fidelity to the real-world. MAPLE achieves state-of-the-art driving performance on Bench2Drive and demonstrates scalable, closed-loop multi-agent play for robust E2E autonomous driving systems.
CoReDiT: Spatial Coherence-Guided Token Pruning and Reconstruction for Efficient Diffusion Transformers
May 13, 2026Diffusion Transformers (DiTs) deliver remarkable image and video generation quality but incur high computational cost, limiting scalability and on-device deployment. We introduce CoReDiT, a structured token pruning framework for DiTs across vision tasks. CoReDiT uses a linear-time spatial coherence score to estimate local redundancy in the latent token lattice and skips high coherence (redundant) tokens in self-attention. To maintain a dense representation and avoid visual discontinuities, we reconstruct skipped attention outputs via coherence-guided aggregation of spatially neighboring retained tokens. We further introduce a progressive, block-adaptive pruning schedule that increases pruning gradually and allocates larger budgets to blocks and denoising steps with higher redundancy. Across state-of-the-art diffusion backbones including PixArt-α and MagicDrive-V2, CoReDiT achieves up to 55% self-attention FLOPs reduction and inference speedups of 1.33x on cloud GPUs and 1.72x on mobile NPUs, while maintaining high visual quality. Notably, CoReDiT also increases on-device memory head-room, enabling higher-resolution generation.
* 8 pages, 8 figures, CVPR workshop
Generative Scenario Rollouts for End-to-End Autonomous Driving
Jan 16, 2026Vision-Language-Action (VLA) models are emerging as highly effective planning models for end-to-end autonomous driving systems. However, current works mostly rely on imitation learning from sparse trajectory annotations and under-utilize their potential as generative models. We propose Generative Scenario Rollouts (GeRo), a plug-and-play framework for VLA models that jointly performs planning and generation of language-grounded future traffic scenes through an autoregressive rollout strategy. First, a VLA model is trained to encode ego vehicle and agent dynamics into latent tokens under supervision from planning, motion, and language tasks, facilitating text-aligned generation. Next, GeRo performs language-conditioned autoregressive generation. Given multi-view images, a scenario description, and ego-action questions, it generates future latent tokens and textual responses to guide long-horizon rollouts. A rollout-consistency loss stabilizes predictions using ground truth or pseudo-labels, mitigating drift and preserving text-action alignment. This design enables GeRo to perform temporally consistent, language-grounded rollouts that support long-horizon reasoning and multi-agent planning. On Bench2Drive, GeRo improves driving score and success rate by +15.7 and +26.2, respectively. By integrating reinforcement learning with generative rollouts, GeRo achieves state-of-the-art closed-loop and open-loop performance, demonstrating strong zero-shot robustness. These results highlight the promise of generative, language-conditioned reasoning as a foundation for safer and more interpretable end-to-end autonomous driving.
RoCA: Robust Cross-Domain End-to-End Autonomous Driving
Jun 11, 2025End-to-end (E2E) autonomous driving has recently emerged as a new paradigm, offering significant potential. However, few studies have looked into the practical challenge of deployment across domains (e.g., cities). Although several works have incorporated Large Language Models (LLMs) to leverage their open-world knowledge, LLMs do not guarantee cross-domain driving performance and may incur prohibitive retraining costs during domain adaptation. In this paper, we propose RoCA, a novel framework for robust cross-domain E2E autonomous driving. RoCA formulates the joint probabilistic distribution over the tokens that encode ego and surrounding vehicle information in the E2E pipeline. Instantiating with a Gaussian process (GP), RoCA learns a set of basis tokens with corresponding trajectories, which span diverse driving scenarios. Then, given any driving scene, it is able to probabilistically infer the future trajectory. By using RoCA together with a base E2E model in source-domain training, we improve the generalizability of the base model, without requiring extra inference computation. In addition, RoCA enables robust adaptation on new target domains, significantly outperforming direct finetuning. We extensively evaluate RoCA on various cross-domain scenarios and show that it achieves strong domain generalization and adaptation performance.
FALO: Fast and Accurate LiDAR 3D Object Detection on Resource-Constrained Devices
Jun 04, 2025



Existing LiDAR 3D object detection methods predominantely rely on sparse convolutions and/or transformers, which can be challenging to run on resource-constrained edge devices, due to irregular memory access patterns and high computational costs. In this paper, we propose FALO, a hardware-friendly approach to LiDAR 3D detection, which offers both state-of-the-art (SOTA) detection accuracy and fast inference speed. More specifically, given the 3D point cloud and after voxelization, FALO first arranges sparse 3D voxels into a 1D sequence based on their coordinates and proximity. The sequence is then processed by our proposed ConvDotMix blocks, consisting of large-kernel convolutions, Hadamard products, and linear layers. ConvDotMix provides sufficient mixing capability in both spatial and embedding dimensions, and introduces higher-order nonlinear interaction among spatial features. Furthermore, when going through the ConvDotMix layers, we introduce implicit grouping, which balances the tensor dimensions for more efficient inference and takes into account the growing receptive field. All these operations are friendly to run on resource-constrained platforms and proposed FALO can readily deploy on compact, embedded devices. Our extensive evaluation on LiDAR 3D detection benchmarks such as nuScenes and Waymo shows that FALO achieves competitive performance. Meanwhile, FALO is 1.6~9.8x faster than the latest SOTA on mobile Graphics Processing Unit (GPU) and mobile Neural Processing Unit (NPU).
PADRe: A Unifying Polynomial Attention Drop-in Replacement for Efficient Vision Transformer
Jul 16, 2024



We present Polynomial Attention Drop-in Replacement (PADRe), a novel and unifying framework designed to replace the conventional self-attention mechanism in transformer models. Notably, several recent alternative attention mechanisms, including Hyena, Mamba, SimA, Conv2Former, and Castling-ViT, can be viewed as specific instances of our PADRe framework. PADRe leverages polynomial functions and draws upon established results from approximation theory, enhancing computational efficiency without compromising accuracy. PADRe's key components include multiplicative nonlinearities, which we implement using straightforward, hardware-friendly operations such as Hadamard products, incurring only linear computational and memory costs. PADRe further avoids the need for using complex functions such as Softmax, yet it maintains comparable or superior accuracy compared to traditional self-attention. We assess the effectiveness of PADRe as a drop-in replacement for self-attention across diverse computer vision tasks. These tasks include image classification, image-based 2D object detection, and 3D point cloud object detection. Empirical results demonstrate that PADRe runs significantly faster than the conventional self-attention (11x ~ 43x faster on server GPU and mobile NPU) while maintaining similar accuracy when substituting self-attention in the transformer models.
CSCO: Connectivity Search of Convolutional Operators
Apr 26, 2024



Exploring dense connectivity of convolutional operators establishes critical "synapses" to communicate feature vectors from different levels and enriches the set of transformations on Computer Vision applications. Yet, even with heavy-machinery approaches such as Neural Architecture Search (NAS), discovering effective connectivity patterns requires tremendous efforts due to either constrained connectivity design space or a sub-optimal exploration process induced by an unconstrained search space. In this paper, we propose CSCO, a novel paradigm that fabricates effective connectivity of convolutional operators with minimal utilization of existing design motifs and further utilizes the discovered wiring to construct high-performing ConvNets. CSCO guides the exploration via a neural predictor as a surrogate of the ground-truth performance. We introduce Graph Isomorphism as data augmentation to improve sample efficiency and propose a Metropolis-Hastings Evolutionary Search (MH-ES) to evade locally optimal architectures and advance search quality. Results on ImageNet show ~0.6% performance improvement over hand-crafted and NAS-crafted dense connectivity. Our code is publicly available.
ZiCo-BC: A Bias Corrected Zero-Shot NAS for Vision Tasks
Sep 26, 2023Zero-Shot Neural Architecture Search (NAS) approaches propose novel training-free metrics called zero-shot proxies to substantially reduce the search time compared to the traditional training-based NAS. Despite the success on image classification, the effectiveness of zero-shot proxies is rarely evaluated on complex vision tasks such as semantic segmentation and object detection. Moreover, existing zero-shot proxies are shown to be biased towards certain model characteristics which restricts their broad applicability. In this paper, we empirically study the bias of state-of-the-art (SOTA) zero-shot proxy ZiCo across multiple vision tasks and observe that ZiCo is biased towards thinner and deeper networks, leading to sub-optimal architectures. To solve the problem, we propose a novel bias correction on ZiCo, called ZiCo-BC. Our extensive experiments across various vision tasks (image classification, object detection and semantic segmentation) show that our approach can successfully search for architectures with higher accuracy and significantly lower latency on Samsung Galaxy S10 devices.
DONNAv2 -- Lightweight Neural Architecture Search for Vision tasks
Sep 26, 2023



With the growing demand for vision applications and deployment across edge devices, the development of hardware-friendly architectures that maintain performance during device deployment becomes crucial. Neural architecture search (NAS) techniques explore various approaches to discover efficient architectures for diverse learning tasks in a computationally efficient manner. In this paper, we present the next-generation neural architecture design for computationally efficient neural architecture distillation - DONNAv2 . Conventional NAS algorithms rely on a computationally extensive stage where an accuracy predictor is learned to estimate model performance within search space. This building of accuracy predictors helps them predict the performance of models that are not being finetuned. Here, we have developed an elegant approach to eliminate building the accuracy predictor and extend DONNA to a computationally efficient setting. The loss metric of individual blocks forming the network serves as the surrogate performance measure for the sampled models in the NAS search stage. To validate the performance of DONNAv2 we have performed extensive experiments involving a range of diverse vision tasks including classification, object detection, image denoising, super-resolution, and panoptic perception network (YOLOP). The hardware-in-the-loop experiments were carried out using the Samsung Galaxy S10 mobile platform. Notably, DONNAv2 reduces the computational cost of DONNA by 10x for the larger datasets. Furthermore, to improve the quality of NAS search space, DONNAv2 leverages a block knowledge distillation filter to remove blocks with high inference costs.
ScaleNAS: One-Shot Learning of Scale-Aware Representations for Visual Recognition
Nov 30, 2020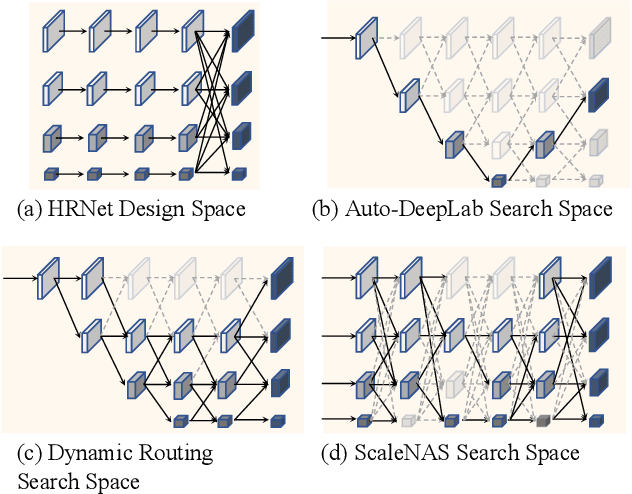
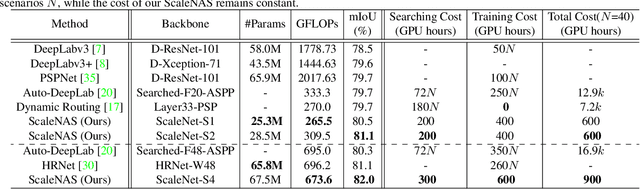
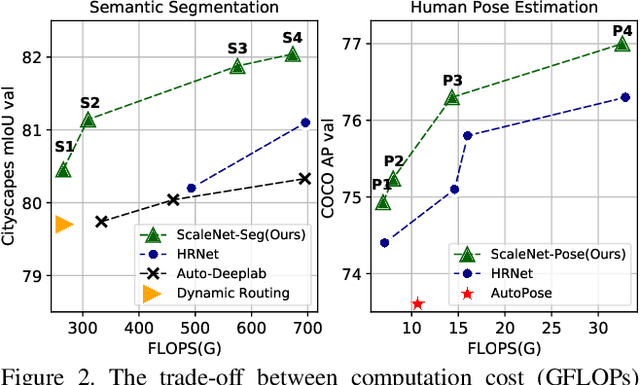
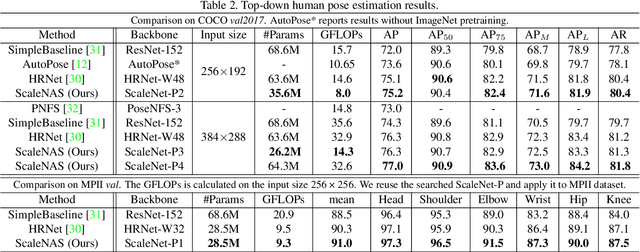
Scale variance among different sizes of body parts and objects is a challenging problem for visual recognition tasks. Existing works usually design dedicated backbone or apply Neural architecture Search(NAS) for each task to tackle this challenge. However, existing works impose significant limitations on the design or search space. To solve these problems, we present ScaleNAS, a one-shot learning method for exploring scale-aware representations. ScaleNAS solves multiple tasks at a time by searching multi-scale feature aggregation. ScaleNAS adopts a flexible search space that allows an arbitrary number of blocks and cross-scale feature fusions. To cope with the high search cost incurred by the flexible space, ScaleNAS employs one-shot learning for multi-scale supernet driven by grouped sampling and evolutionary search. Without further retraining, ScaleNet can be directly deployed for different visual recognition tasks with superior performance. We use ScaleNAS to create high-resolution models for two different tasks, ScaleNet-P for human pose estimation and ScaleNet-S for semantic segmentation. ScaleNet-P and ScaleNet-S outperform existing manually crafted and NAS-based methods in both tasks. When applying ScaleNet-P to bottom-up human pose estimation, it surpasses the state-of-the-art HigherHRNet. In particular, ScaleNet-P4 achieves 71.6% AP on COCO test-dev, achieving new state-of-the-art result.