 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes a Good Generated Image? Investigating Human and Multimodal LLM Image Preference Alignment
Sep 16, 2025



Automated evaluation of generative text-to-image models remains a challenging problem. Recent works have proposed using multimodal LLMs to judge the quality of images, but these works offer little insight into how multimodal LLMs make use of concepts relevant to humans, such as image style or composition, to generate their overall assessment. In this work, we study what attributes of an image--specifically aesthetics, lack of artifacts, anatomical accuracy, compositional correctness, object adherence, and style--are important for both LLMs and humans to make judgments on image quality. We first curate a dataset of human preferences using synthetically generated image pairs. We use inter-task correlation between each pair of image quality attributes to understand which attributes are related in making human judgments. Repeating the same analysis with LLMs, we find that the relationships between image quality attributes are much weaker. Finally, we study individual image quality attributes by generating synthetic datasets with a high degree of control for each axis. Humans are able to easily judge the quality of an image with respect to all of the specific image quality attributes (e.g. high vs. low aesthetic image), however we find that some attributes, such as anatomical accuracy, are much more difficult for multimodal LLMs to learn to judge. Taken together, these findings reveal interesting differences between how humans and multimodal LLMs perceive images.
A Novel Recurrent Neural Network Framework for Prediction and Treatment of Oncogenic Mutation Progression
Sep 16, 2025Despite significant medical advancements, cancer remains the second leading cause of death, with over 600,000 deaths per year in the US. One emerging field, pathway analysis, is promising but still relies on manually derived wet lab data, which is time-consuming to acquire. This work proposes an efficient, effective end-to-end framework for Artificial Intelligence (AI) based pathway analysis that predicts both cancer severity and mutation progression, thus recommending possible treatments. The proposed technique involves a novel combination of time-series machine learning models and pathway analysis. First, mutation sequences were isolated from The Cancer Genome Atlas (TCGA) Database. Then, a novel preprocessing algorithm was used to filter key mutations by mutation frequency. This data was fed into a Recurrent Neural Network (RNN) that predicted cancer severity. Then, the model probabilistically used the RNN predictions, information from the preprocessing algorithm, and multiple drug-target databases to predict future mutations and recommend possible treatments. This framework achieved robust results and Receiver Operating Characteristic (ROC) curves (a key statistical metric) with accuracies greater than 60%, similar to existing cancer diagnostics. In addition, preprocessing played an instrumental role in isolating important mutations, demonstrating that each cancer stage studied may contain on the order of a few-hundred key driver mutations, consistent with current research. Heatmaps based on predicted gene frequency were also generated, highlighting key mutations in each cancer. Overall, this work is the first to propose an efficient, cost-effective end-to-end framework for projecting cancer progression and providing possible treatments without relying on expensive, time-consuming wet lab work.
Vid3D: Synthesis of Dynamic 3D Scenes using 2D Video Diffusion
Jun 17, 2024A recent frontier in computer vision has been the task of 3D video generation, which consists of generating a time-varying 3D representation of a scene. To generate dynamic 3D scenes, current methods explicitly model 3D temporal dynamics by jointly optimizing for consistency across both time and views of the scene. In this paper, we instead investigate whether it is necessary to explicitly enforce multiview consistency over time, as current approaches do, or if it is sufficient for a model to generate 3D representations of each timestep independently. We hence propose a model, Vid3D, that leverages 2D video diffusion to generate 3D videos by first generating a 2D "seed" of the video's temporal dynamics and then independently generating a 3D representation for each timestep in the seed video. We evaluate Vid3D against two state-of-the-art 3D video generation methods and find that Vid3D is achieves comparable results despite not explicitly modeling 3D temporal dynamics. We further ablate how the quality of Vid3D depends on the number of views generated per frame. While we observe some degradation with fewer views, performance degradation remains minor. Our results thus suggest that 3D temporal knowledge may not be necessary to generate high-quality dynamic 3D scenes, potentially enabling simpler generative algorithms for this task.
Hydra: Sequentially-Dependent Draft Heads for Medusa Decoding
Feb 07, 2024To combat the memory bandwidth-bound nature of autoregressive LLM inference, previous research has proposed the speculative decoding framework. To perform speculative decoding, a small draft model proposes candidate continuations of the input sequence, that are then verified in parallel by the base model. One way to specify the draft model, as used in the recent Medusa decoding framework, is as a collection of light-weight heads, called draft heads, that operate on the base model's hidden states. To date, all existing draft heads have been sequentially independent, meaning that they speculate tokens in the candidate continuation independently of any preceding tokens in the candidate continuation. In this work, we propose Hydra heads, a sequentially dependent, drop-in replacement for standard draft heads that significantly improves speculation accuracy. Decoding with Hydra heads improves throughput compared to Medusa decoding with standard draft heads. We further explore the design space of Hydra head training objectives and architectures, and propose a carefully-tuned Hydra head recipe, which we call Hydra++, that improves decoding throughput by 1.31x and 2.71x compared to Medusa decoding and autoregressive decoding, respectively. Overall, Hydra heads are a simple intervention on standard draft heads that significantly improve the end-to-end speed of draft head based speculative decoding.
Quantum Optical Convolutional Neural Network: A Novel Image Recognition Framework for Quantum Computing
Dec 19, 2020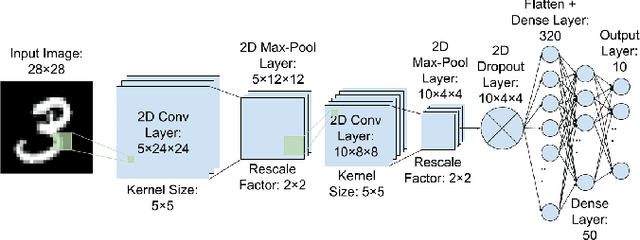
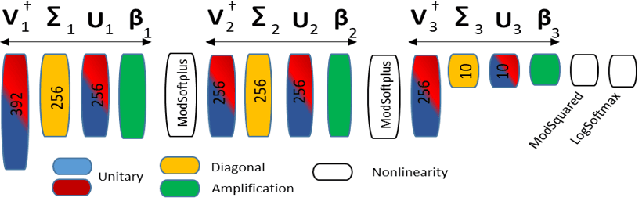
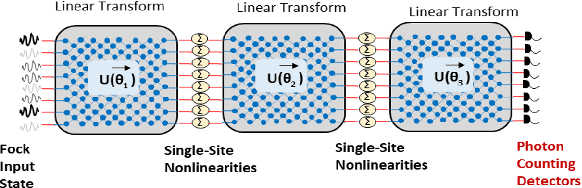
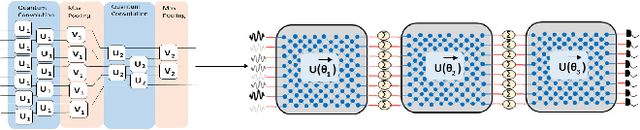
Large machine learning models based on Convolutional Neural Networks (CNNs) with rapidly increasing number of parameters, trained with massive amounts of data, are being deployed in a wide array of computer vision tasks from self-driving cars to medical imaging. The insatiable demand for computing resources required to train these models is fast outpacing the advancement of classical computing hardware, and new frameworks including Optical Neural Networks (ONNs) and quantum computing are being explored as future alternatives. In this work, we report a novel quantum computing based deep learning model, the Quantum Optical Convolutional Neural Network (QOCNN), to alleviate the computational bottleneck in future computer vision applications. Using the popular MNIST dataset, we have benchmarked this new architecture against a traditional CNN based on the seminal LeNet model. We have also compared the performance with previously reported ONNs, namely the GridNet and ComplexNet, as well as a Quantum Optical Neural Network (QONN) that we built by combining the ComplexNet with quantum based sinusoidal nonlinearities. In essence, our work extends the prior research on QONN by adding quantum convolution and pooling layers preceding it. We have evaluated all the models by determining their accuracies, confusion matrices, Receiver Operating Characteristic (ROC) curves, and Matthews Correlation Coefficients. The performance of the models were similar overall, and the ROC curves indicated that the new QOCNN model is robust. Finally, we estimated the gains in computational efficiencies from executing this novel framework on a quantum computer. We conclude that switching to a quantum computing based approach to deep learning may result in comparable accuracies to classical models, while achieving unprecedented boosts in computational performances and drastic reduction in power consumption.