 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGenST-Bench: A Benchmark for Spatio-Temporal Reasoning via Active Video Synthesis
May 21, 2026Spatio-temporal reasoning is a core capability for Multimodal Large Language Models (MLLMs) operating in the real world. As such, evaluating it precisely has become an essential challenge. However, existing spatio-temporal reasoning benchmark datasets primarily rely on static image sets or passively curated video data, which limits the evaluation of fine-grained reasoning capabilities. In this paper, we introduce VGenST-Bench, a video benchmark that employs generative models to actively synthesize highly controlled and diverse evaluation scenarios. To construct VGenST-Bench, we propose a multi-agent pipeline incorporating a human quality control stage, ensuring the quality of all generated videos and QA pairs. We establish a comprehensive 3x2x2 video taxonomy, encompassing Spatial Scale, Perspective, and Scene Dynamics to span diverse scenarios. Furthermore, we design a hierarchical task suite that decouples low-level visual perception from high-level spatio-temporal reasoning. By shifting the paradigm from passive curation to active synthesis, VGenST-Bench enables fine-grained diagnosis of spatio-temporal understanding in MLLMs.
2Xplat: Two Experts Are Better Than One Generalist
Mar 24, 2026Pose-free feed-forward 3D Gaussian Splatting (3DGS) has opened a new frontier for rapid 3D modeling, enabling high-quality Gaussian representations to be generated from uncalibrated multi-view images in a single forward pass. The dominant approach in this space adopts unified monolithic architectures, often built on geometry-centric 3D foundation models, to jointly estimate camera poses and synthesize 3DGS representations within a single network. While architecturally streamlined, such "all-in-one" designs may be suboptimal for high-fidelity 3DGS generation, as they entangle geometric reasoning and appearance modeling within a shared representation. In this work, we introduce 2Xplat, a pose-free feed-forward 3DGS framework based on a two-expert design that explicitly separates geometry estimation from Gaussian generation. A dedicated geometry expert first predicts camera poses, which are then explicitly passed to a powerful appearance expert that synthesizes 3D Gaussians. Despite its conceptual simplicity, being largely underexplored in prior works, the proposed approach proves highly effective. In fewer than 5K training iterations, the proposed two-experts pipeline substantially outperforms prior pose-free feed-forward 3DGS approaches and achieves performance on par with state-of-the-art posed methods. These results challenge the prevailing unified paradigm and suggest the potential advantages of modular design principles for complex 3D geometric estimation and appearance synthesis tasks.
Group3D: MLLM-Driven Semantic Grouping for Open-Vocabulary 3D Object Detection
Mar 23, 2026Open-vocabulary 3D object detection aims to localize and recognize objects beyond a fixed training taxonomy. In multi-view RGB settings, recent approaches often decouple geometry-based instance construction from semantic labeling, generating class-agnostic fragments and assigning open-vocabulary categories post hoc. While flexible, such decoupling leaves instance construction governed primarily by geometric consistency, without semantic constraints during merging. When geometric evidence is view-dependent and incomplete, this geometry-only merging can lead to irreversible association errors, including over-merging of distinct objects or fragmentation of a single instance. We propose Group3D, a multi-view open-vocabulary 3D detection framework that integrates semantic constraints directly into the instance construction process. Group3D maintains a scene-adaptive vocabulary derived from a multimodal large language model (MLLM) and organizes it into semantic compatibility groups that encode plausible cross-view category equivalence. These groups act as merge-time constraints: 3D fragments are associated only when they satisfy both semantic compatibility and geometric consistency. This semantically gated merging mitigates geometry-driven over-merging while absorbing multi-view category variability. Group3D supports both pose-known and pose-free settings, relying only on RGB observations. Experiments on ScanNet and ARKitScenes demonstrate that Group3D achieves state-of-the-art performance in multi-view open-vocabulary 3D detection, while exhibiting strong generalization in zero-shot scenarios. The project page is available at https://ubin108.github.io/Group3D/.
Two Experts Are Better Than One Generalist: Decoupling Geometry and Appearance for Feed-Forward 3D Gaussian Splatting
Mar 22, 2026Pose-free feed-forward 3D Gaussian Splatting (3DGS) has opened a new frontier for rapid 3D modeling, enabling high-quality Gaussian representations to be generated from uncalibrated multi-view images in a single forward pass. The dominant approach in this space adopts unified monolithic architectures, often built on geometry-centric 3D foundation models, to jointly estimate camera poses and synthesize 3DGS representations within a single network. While architecturally streamlined, such "all-in-one" designs may be suboptimal for high-fidelity 3DGS generation, as they entangle geometric reasoning and appearance modeling within a shared representation. In this work, we introduce 2Xplat, a pose-free feed-forward 3DGS framework based on a two-expert design that explicitly separates geometry estimation from Gaussian generation. A dedicated geometry expert first predicts camera poses, which are then explicitly passed to a powerful appearance expert that synthesizes 3D Gaussians. Despite its conceptual simplicity, being largely underexplored in prior works, the proposed approach proves highly effective. In fewer than 5K training iterations, the proposed two-experts pipeline substantially outperforms prior pose-free feed-forward 3DGS approaches and achieves performance on par with state-of-the-art posed methods. These results challenge the prevailing unified paradigm and suggest the potential advantages of modular design principles for complex 3D geometric estimation and appearance synthesis tasks.
3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
Mar 19, 2026Creating dynamic, view-consistent videos of customized subjects is highly sought after for a wide range of emerging applications, including immersive VR/AR, virtual production, and next-generation e-commerce. However, despite rapid progress in subject-driven video generation, existing methods predominantly treat subjects as 2D entities, focusing on transferring identity through single-view visual features or textual prompts. Because real-world subjects are inherently 3D, applying these 2D-centric approaches to 3D object customization reveals a fundamental limitation: they lack the comprehensive spatial priors necessary to reconstruct the 3D geometry. Consequently, when synthesizing novel views, they must rely on generating plausible but arbitrary details for unseen regions, rather than preserving the true 3D identity. Achieving genuine 3D-aware customization remains challenging due to the scarcity of multi-view video datasets. While one might attempt to fine-tune models on limited video sequences, this often leads to temporal overfitting. To resolve these issues, we introduce a novel framework for 3D-aware video customization, comprising 3DreamBooth and 3Dapter. 3DreamBooth decouples spatial geometry from temporal motion through a 1-frame optimization paradigm. By restricting updates to spatial representations, it effectively bakes a robust 3D prior into the model without the need for exhaustive video-based training. To enhance fine-grained textures and accelerate convergence, we incorporate 3Dapter, a visual conditioning module. Following single-view pre-training, 3Dapter undergoes multi-view joint optimization with the main generation branch via an asymmetrical conditioning strategy. This design allows the module to act as a dynamic selective router, querying view-specific geometric hints from a minimal reference set. Project page: https://ko-lani.github.io/3DreamBooth/
ILV: Iterative Latent Volumes for Fast and Accurate Sparse-View CT Reconstruction
Mar 16, 2026A long-term goal in CT imaging is to achieve fast and accurate 3D reconstruction from sparse-view projections, thereby reducing radiation exposure, lowering system cost, and enabling timely imaging in clinical workflows. Recent feed-forward approaches have shown strong potential toward this overarching goal, yet their results still suffer from artifacts and loss of fine details. In this work, we introduce Iterative Latent Volumes (ILV), a feed-forward framework that integrates data-driven priors with classical iterative reconstruction principles to overcome key limitations of prior feed-forward models in sparse-view CBCT reconstruction. At its core, ILV constructs an explicit 3D latent volume that is repeatedly updated by conditioning on multi-view X-ray features and the learned anatomical prior, enabling the recovery of fine structural details beyond the reach of prior feed-forward models. In addition, we develop and incorporate several key architectural components, including an X-ray feature volume, group cross-attention, efficient self-attention, and view-wise feature aggregation, that efficiently realize its core latent volume refinement concept. Extensive experiments on a large-scale dataset of approximately 14,000 CT volumes demonstrate that ILV significantly outperforms existing feed-forward and optimization-based methods in both reconstruction quality and speed. These results show that ILV enables fast and accurate sparse-view CBCT reconstruction suitable for clinical use. The project page is available at: https://sngryonglee.github.io/ILV/.
OpenMonoGS-SLAM: Monocular Gaussian Splatting SLAM with Open-set Semantics
Dec 09, 2025Simultaneous Localization and Mapping (SLAM) is a foundational component in robotics, AR/VR, and autonomous systems. With the rising focus on spatial AI in recent years, combining SLAM with semantic understanding has become increasingly important for enabling intelligent perception and interaction. Recent efforts have explored this integration, but they often rely on depth sensors or closed-set semantic models, limiting their scalability and adaptability in open-world environments. In this work, we present OpenMonoGS-SLAM, the first monocular SLAM framework that unifies 3D Gaussian Splatting (3DGS) with open-set semantic understanding. To achieve our goal, we leverage recent advances in Visual Foundation Models (VFMs), including MASt3R for visual geometry and SAM and CLIP for open-vocabulary semantics. These models provide robust generalization across diverse tasks, enabling accurate monocular camera tracking and mapping, as well as a rich understanding of semantics in open-world environments. Our method operates without any depth input or 3D semantic ground truth, relying solely on self-supervised learning objectives. Furthermore, we propose a memory mechanism specifically designed to manage high-dimensional semantic features, which effectively constructs Gaussian semantic feature maps, leading to strong overall performance. Experimental results demonstrate that our approach achieves performance comparable to or surpassing existing baselines in both closed-set and open-set segmentation tasks, all without relying on supplementary sensors such as depth maps or semantic annotations.
Multi-view Pyramid Transformer: Look Coarser to See Broader
Dec 08, 2025



We propose Multi-view Pyramid Transformer (MVP), a scalable multi-view transformer architecture that directly reconstructs large 3D scenes from tens to hundreds of images in a single forward pass. Drawing on the idea of ``looking broader to see the whole, looking finer to see the details," MVP is built on two core design principles: 1) a local-to-global inter-view hierarchy that gradually broadens the model's perspective from local views to groups and ultimately the full scene, and 2) a fine-to-coarse intra-view hierarchy that starts from detailed spatial representations and progressively aggregates them into compact, information-dense tokens. This dual hierarchy achieves both computational efficiency and representational richness, enabling fast reconstruction of large and complex scenes. We validate MVP on diverse datasets and show that, when coupled with 3D Gaussian Splatting as the underlying 3D representation, it achieves state-of-the-art generalizable reconstruction quality while maintaining high efficiency and scalability across a wide range of view configurations.
Gather-Scatter Mamba: Accelerating Propagation with Efficient State Space Model
Oct 01, 2025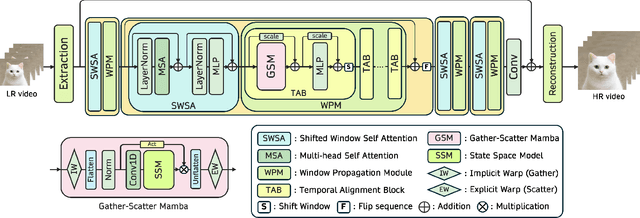
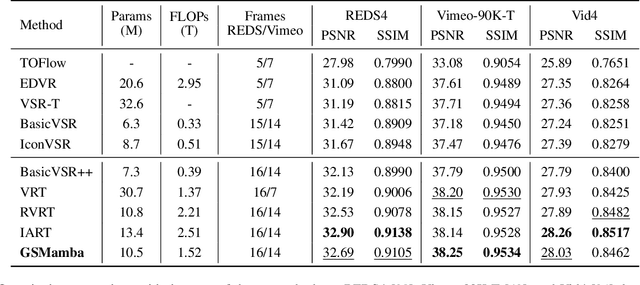
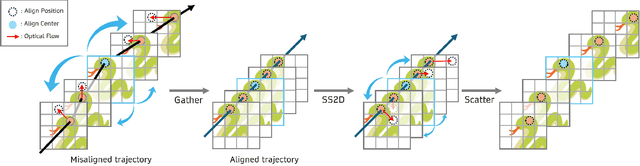
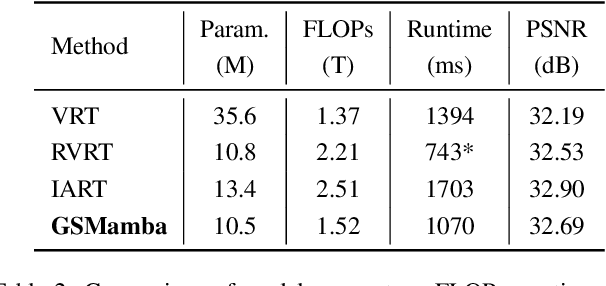
State Space Models (SSMs)-most notably RNNs-have historically played a central role in sequential modeling. Although attention mechanisms such as Transformers have since dominated due to their ability to model global context, their quadratic complexity and limited scalability make them less suited for long sequences. Video super-resolution (VSR) methods have traditionally relied on recurrent architectures to propagate features across frames. However, such approaches suffer from well-known issues including vanishing gradients, lack of parallelism, and slow inference speed. Recent advances in selective SSMs like Mamba offer a compelling alternative: by enabling input-dependent state transitions with linear-time complexity, Mamba mitigates these issues while maintaining strong long-range modeling capabilities. Despite this potential, Mamba alone struggles to capture fine-grained spatial dependencies due to its causal nature and lack of explicit context aggregation. To address this, we propose a hybrid architecture that combines shifted window self-attention for spatial context aggregation with Mamba-based selective scanning for efficient temporal propagation. Furthermore, we introduce Gather-Scatter Mamba (GSM), an alignment-aware mechanism that warps features toward a center anchor frame within the temporal window before Mamba propagation and scatters them back afterward, effectively reducing occlusion artifacts and ensuring effective redistribution of aggregated information across all frames. The official implementation is provided at: https://github.com/Ko-Lani/GSMamba.
Moiré Zero: An Efficient and High-Performance Neural Architecture for Moiré Removal
Jul 30, 2025Moir\'e patterns, caused by frequency aliasing between fine repetitive structures and a camera sensor's sampling process, have been a significant obstacle in various real-world applications, such as consumer photography and industrial defect inspection. With the advancements in deep learning algorithms, numerous studies-predominantly based on convolutional neural networks-have suggested various solutions to address this issue. Despite these efforts, existing approaches still struggle to effectively eliminate artifacts due to the diverse scales, orientations, and color shifts of moir\'e patterns, primarily because the constrained receptive field of CNN-based architectures limits their ability to capture the complex characteristics of moir\'e patterns. In this paper, we propose MZNet, a U-shaped network designed to bring images closer to a 'Moire-Zero' state by effectively removing moir\'e patterns. It integrates three specialized components: Multi-Scale Dual Attention Block (MSDAB) for extracting and refining multi-scale features, Multi-Shape Large Kernel Convolution Block (MSLKB) for capturing diverse moir\'e structures, and Feature Fusion-Based Skip Connection for enhancing information flow. Together, these components enhance local texture restoration and large-scale artifact suppression. Experiments on benchmark datasets demonstrate that MZNet achieves state-of-the-art performance on high-resolution datasets and delivers competitive results on lower-resolution dataset, while maintaining a low computational cost, suggesting that it is an efficient and practical solution for real-world applications. Project page: https://sngryonglee.github.io/MoireZero