 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Recognition using 3D CNNs
Feb 02, 2021

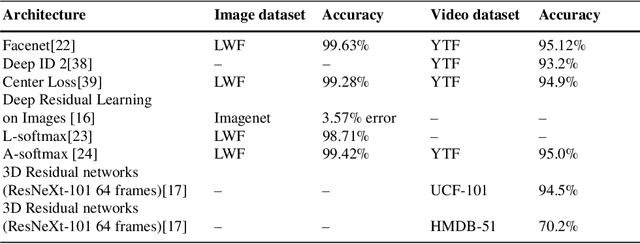
The area of face recognition is one of the most widely researched areas in the domain of computer vision and biometric. This is because, the non-intrusive nature of face biometric makes it comparatively more suitable for application in area of surveillance at public places such as airports. The application of primitive methods in face recognition could not give very satisfactory performance. However, with the advent of machine and deep learning methods and their application in face recognition, several major breakthroughs were obtained. The use of 2D Convolution Neural networks(2D CNN) in face recognition crossed the human face recognition accuracy and reached to 99%. Still, robust face recognition in the presence of real world conditions such as variation in resolution, illumination and pose is a major challenge for researchers in face recognition. In this work, we used video as input to the 3D CNN architectures for capturing both spatial and time domain information from the video for face recognition in real world environment. For the purpose of experimentation, we have developed our own video dataset called CVBL video dataset. The use of 3D CNN for face recognition in videos shows promising results with DenseNets performing the best with an accuracy of 97% on CVBL dataset.
Face Recognition Using $Sf_{3}CNN$ With Higher Feature Discrimination
Feb 02, 2021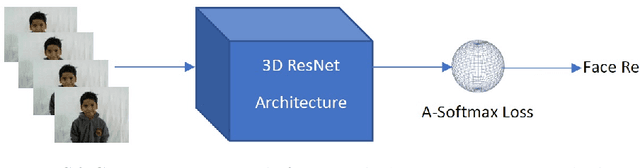
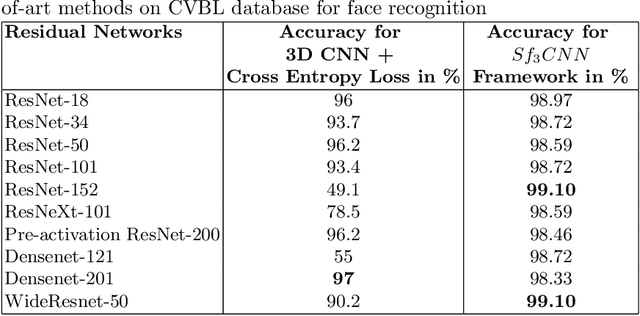
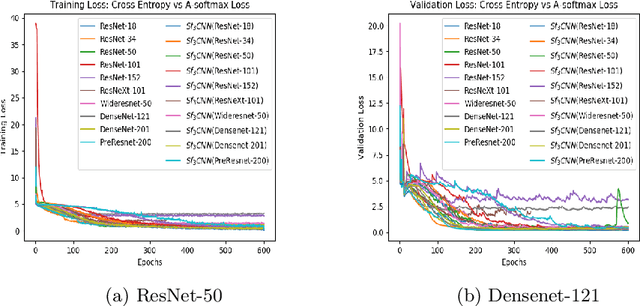
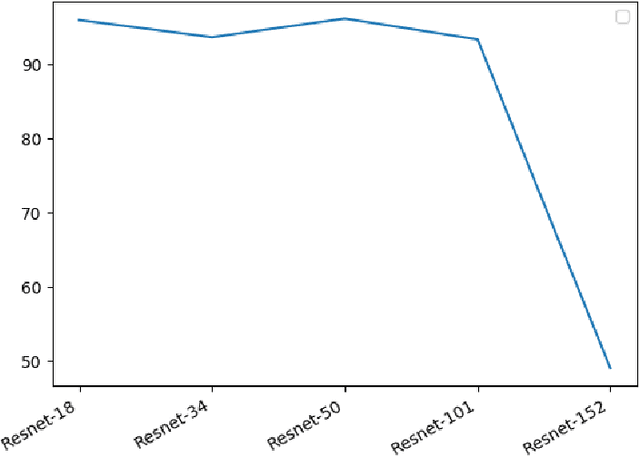
With the advent of 2-dimensional Convolution Neural Networks (2D CNNs), the face recognition accuracy has reached above 99%. However, face recognition is still a challenge in real world conditions. A video, instead of an image, as an input can be more useful to solve the challenges of face recognition in real world conditions. This is because a video provides more features than an image. However, 2D CNNs cannot take advantage of the temporal features present in the video. We therefore, propose a framework called $Sf_{3}CNN$ for face recognition in videos. The $Sf_{3}CNN$ framework uses 3-dimensional Residual Network (3D Resnet) and A-Softmax loss for face recognition in videos. The use of 3D ResNet helps to capture both spatial and temporal features into one compact feature map. However, the 3D CNN features must be highly discriminative for efficient face recognition. The use of A-Softmax loss helps to extract highly discriminative features from the video for face recognition. $Sf_{3}CNN$ framework gives an increased accuracy of 99.10% on CVBL video database in comparison to the previous 97% on the same database using 3D ResNets.