 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LISA: Learning Implicit Shape and Appearance of Hands
Apr 04, 2022
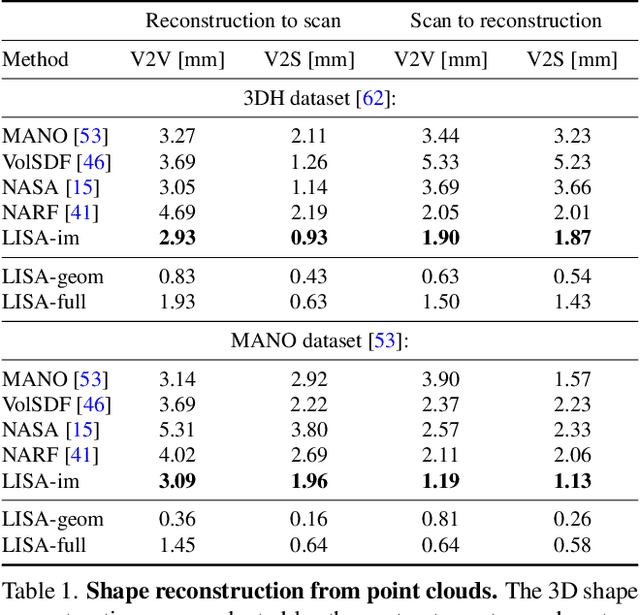
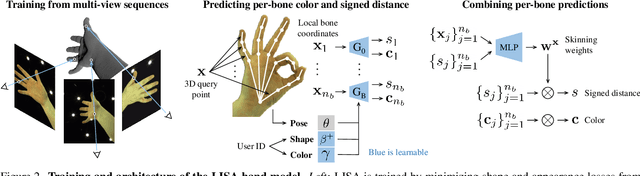
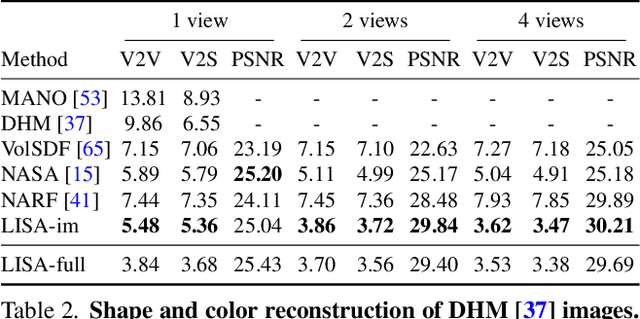
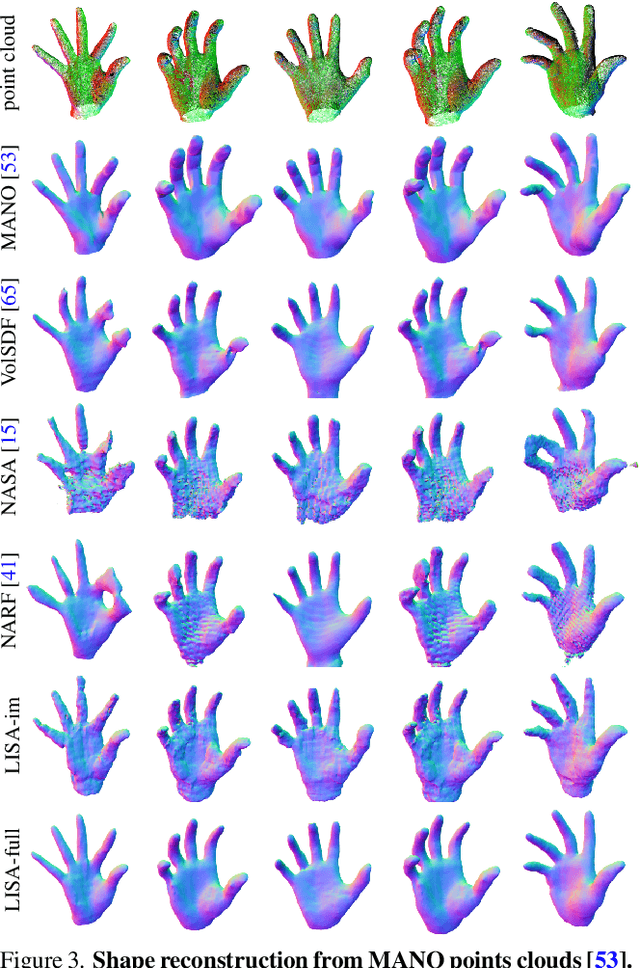
This paper proposes a do-it-all neural model of human hands, named LISA. The model can capture accurate hand shape and appearance, generalize to arbitrary hand subjects, provide dense surface correspondences, be reconstructed from images in the wild and easily animated. We train LISA by minimizing the shape and appearance losses on a large set of multi-view RGB image sequences annotated with coarse 3D poses of the hand skeleton. For a 3D point in the hand local coordinate, our model predicts the color and the signed distance with respect to each hand bone independently, and then combines the per-bone predictions using predicted skinning weights. The shape, color and pose representations are disentangled by design, allowing to estimate or animate only selected parameters. We experimentally demonstrate that LISA can accurately reconstruct a dynamic hand from monocular or multi-view sequences, achieving a noticeably higher quality of reconstructed hand shapes compared to baseline approaches. Project page: https://www.iri.upc.edu/people/ecorona/lisa/.
DualNorm-UNet: Incorporating Global and Local Statistics for Robust Medical Image Segmentation
Mar 29, 2021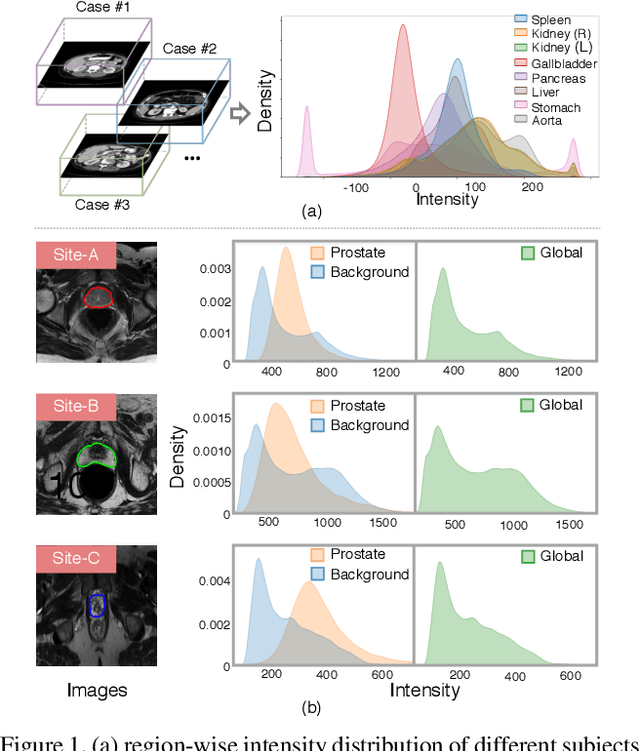
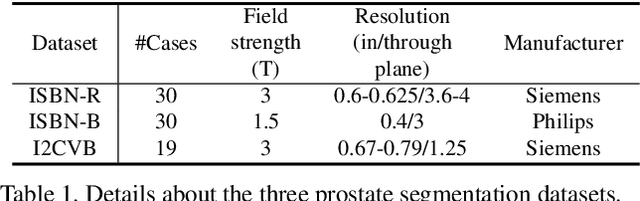
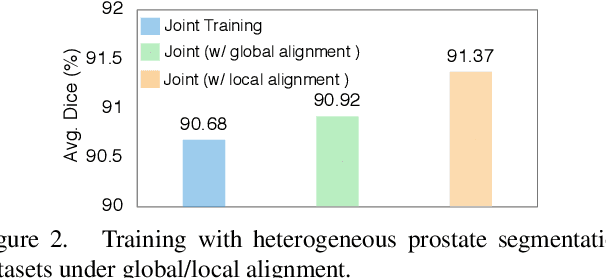
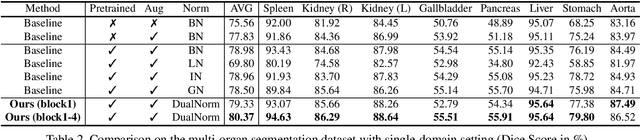
Batch Normalization (BN) is one of the key components for accelerating network training, and has been widely adopted in the medical image analysis field. However, BN only calculates the global statistics at the batch level, and applies the same affine transformation uniformly across all spatial coordinates, which would suppress the image contrast of different semantic structures. In this paper, we propose to incorporate the semantic class information into normalization layers, so that the activations corresponding to different regions (i.e., classes) can be modulated differently. We thus develop a novel DualNorm-UNet, to concurrently incorporate both global image-level statistics and local region-wise statistics for network normalization. Specifically, the local statistics are integrated by adaptively modulating the activations along different class regions via the learned semantic masks in the normalization layer. Compared with existing methods, our approach exploits semantic knowledge at normalization and yields more discriminative features for robust segmentation results. More importantly, our network demonstrates superior abilities in capturing domain-invariant information from multiple domains (institutions) of medical data. Extensive experiments show that our proposed DualNorm-UNet consistently improves the performance on various segmentation tasks, even in the face of more complex and variable data distributions. Code is available at https://github.com/lambert-x/DualNorm-Unet.
Similarity Reasoning and Filtration for Image-Text Matching
Jan 05, 2021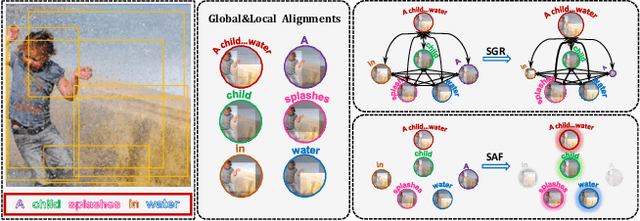
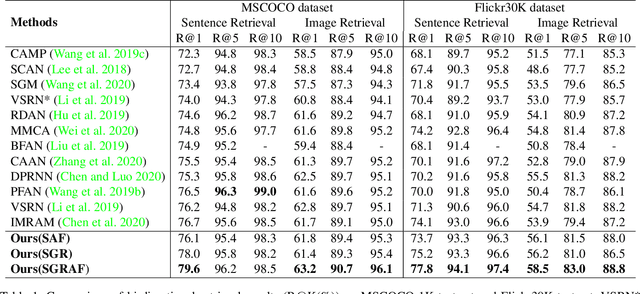
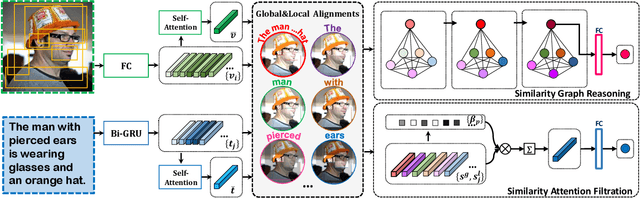
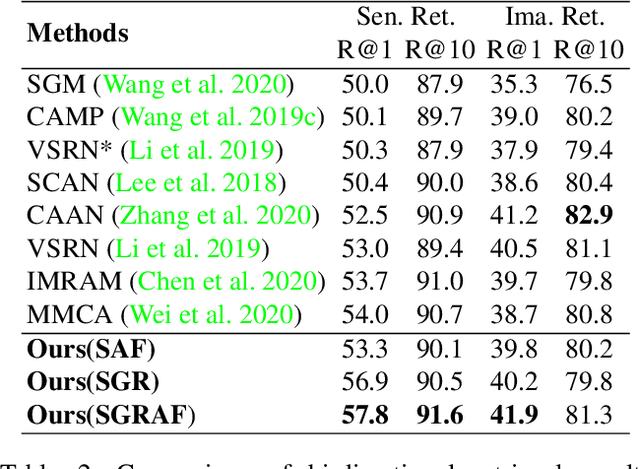
Image-text matching plays a critical role in bridging the vision and language, and great progress has been made by exploiting the global alignment between image and sentence, or local alignments between regions and words. However, how to make the most of these alignments to infer more accurate matching scores is still underexplored. In this paper, we propose a novel Similarity Graph Reasoning and Attention Filtration (SGRAF) network for image-text matching. Specifically, the vector-based similarity representations are firstly learned to characterize the local and global alignments in a more comprehensive manner, and then the Similarity Graph Reasoning (SGR) module relying on one graph convolutional neural network is introduced to infer relation-aware similarities with both the local and global alignments. The Similarity Attention Filtration (SAF) module is further developed to integrate these alignments effectively by selectively attending on the significant and representative alignments and meanwhile casting aside the interferences of non-meaningful alignments. We demonstrate the superiority of the proposed method with achieving state-of-the-art performances on the Flickr30K and MSCOCO datasets, and the good interpretability of SGR and SAF modules with extensive qualitative experiments and analyses.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Jan 24, 2022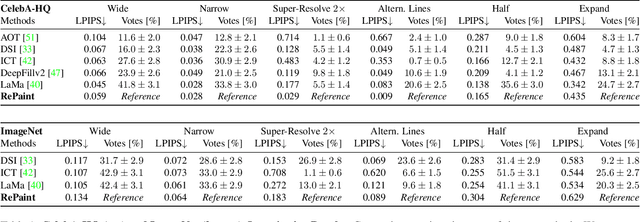
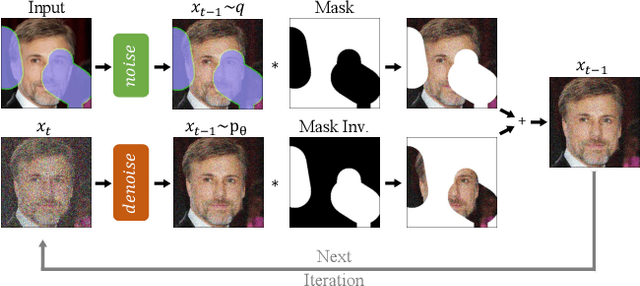


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
Two-Stream Appearance Transfer Network for Person Image Generation
Nov 09, 2020
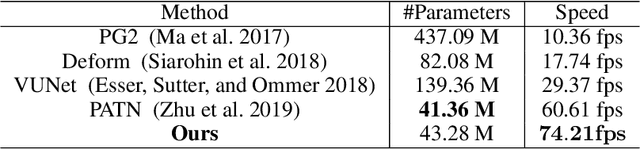
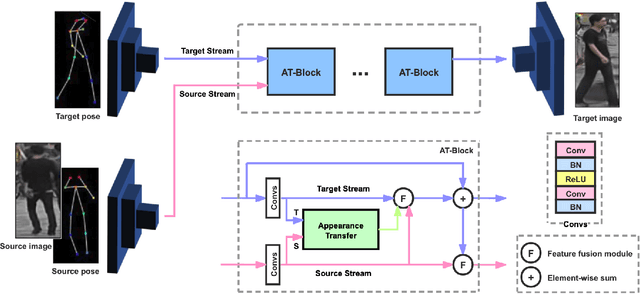

Pose guided person image generation means to generate a photo-realistic person image conditioned on an input person image and a desired pose. This task requires spatial manipulation of the source image according to the target pose. However, the generative adversarial networks (GANs) widely used for image generation and translation rely on spatially local and translation equivariant operators, i.e., convolution, pooling and unpooling, which cannot handle large image deformation. This paper introduces a novel two-stream appearance transfer network (2s-ATN) to address this challenge. It is a multi-stage architecture consisting of a source stream and a target stream. Each stage features an appearance transfer module and several two-stream feature fusion modules. The former finds the dense correspondence between the two-stream feature maps and then transfers the appearance information from the source stream to the target stream. The latter exchange local information between the two streams and supplement the non-local appearance transfer. Both quantitative and qualitative results indicate the proposed 2s-ATN can effectively handle large spatial deformation and occlusion while retaining the appearance details. It outperforms prior states of the art on two widely used benchmarks.
Differentiated Relevances Embedding for Group-based Referring Expression Comprehension
Mar 12, 2022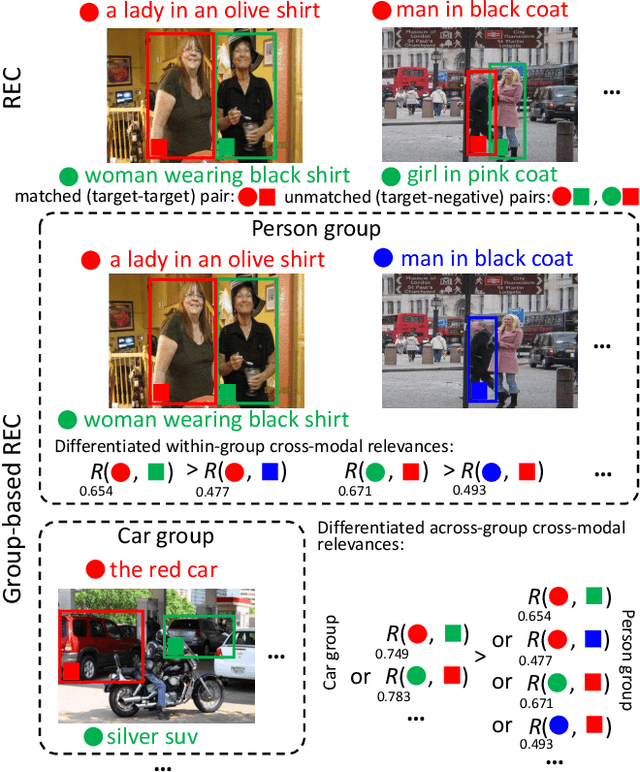
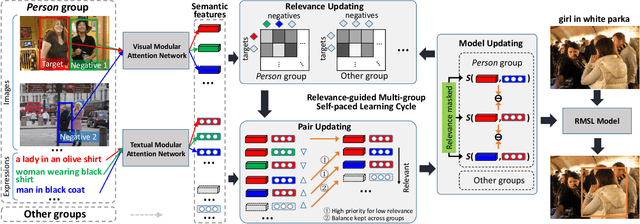

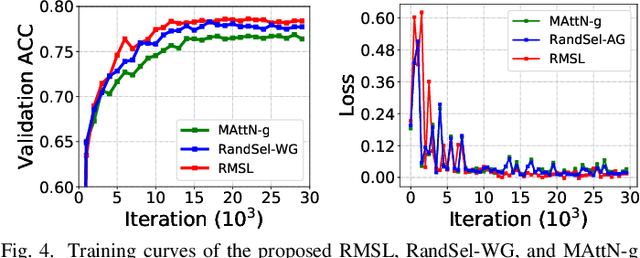
Referring expression comprehension (REC) aims to locate a certain object in an image referred by a natural language expression. For joint understanding of regions and expressions, existing REC works typically target on modeling the cross-modal relevance in each region-expression pair within each single image. In this paper, we explore a new but general REC-related problem, named Group-based REC, where the regions and expressions can come from different subject-related images (images in the same group), e.g., sets of photo albums or video frames. Different from REC, Group-based REC involves differentiated cross-modal relevances within each group and across different groups, which, however, are neglected in the existing one-line paradigm. To this end, we propose a novel relevance-guided multi-group self-paced learning schema (termed RMSL), where the within-group region-expression pairs are adaptively assigned with different priorities according to their cross-modal relevances, and the bias of the group priority is balanced via an across-group relevance constraint simultaneously. In particular, based on the visual and textual semantic features, RMSL conducts an adaptive learning cycle upon triplet ranking, where (1) the target-negative region-expression pairs with low within-group relevances are used preferentially in model training to distinguish the primary semantics of the target objects, and (2) an across-group relevance regularization is integrated into model training to balance the bias of group priority. The relevances, the pairs, and the model parameters are alternatively updated upon a unified self-paced hinge loss.
Language Matters: A Weakly Supervised Pre-training Approach for Scene Text Detection and Spotting
Mar 08, 2022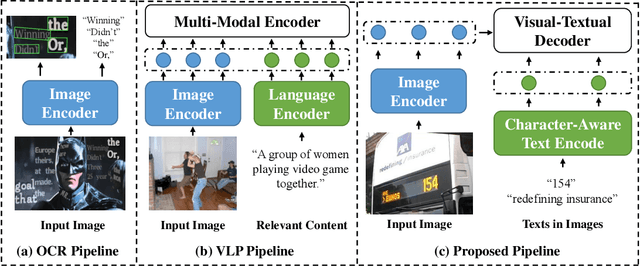
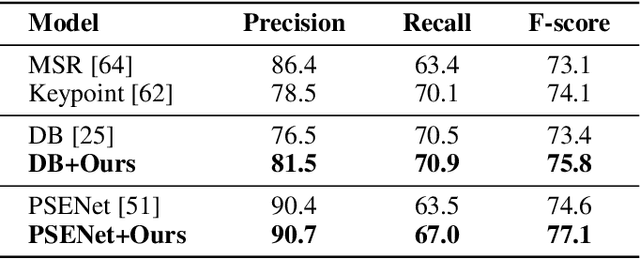
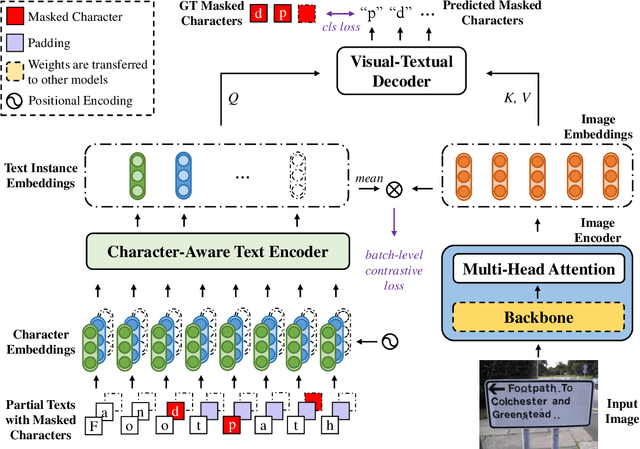

Recently, Vision-Language Pre-training (VLP) techniques have greatly benefited various vision-language tasks by jointly learning visual and textual representations, which intuitively helps in Optical Character Recognition (OCR) tasks due to the rich visual and textual information in scene text images. However, these methods cannot well cope with OCR tasks because of the difficulty in both instance-level text encoding and image-text pair acquisition (i.e. images and captured texts in them). This paper presents a weakly supervised pre-training method that can acquire effective scene text representations by jointly learning and aligning visual and textual information. Our network consists of an image encoder and a character-aware text encoder that extract visual and textual features, respectively, as well as a visual-textual decoder that models the interaction among textual and visual features for learning effective scene text representations. With the learning of textual features, the pre-trained model can attend texts in images well with character awareness. Besides, these designs enable the learning from weakly annotated texts (i.e. partial texts in images without text bounding boxes) which mitigates the data annotation constraint greatly. Experiments over the weakly annotated images in ICDAR2019-LSVT show that our pre-trained model improves F-score by +2.5% and +4.8% while transferring its weights to other text detection and spotting networks, respectively. In addition, the proposed method outperforms existing pre-training techniques consistently across multiple public datasets (e.g., +3.2% and +1.3% for Total-Text and CTW1500).
Multi-Modal Hypergraph Diffusion Network with Dual Prior for Alzheimer Classification
Apr 04, 2022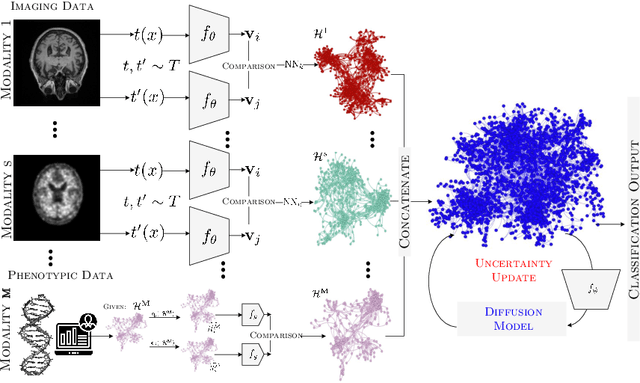
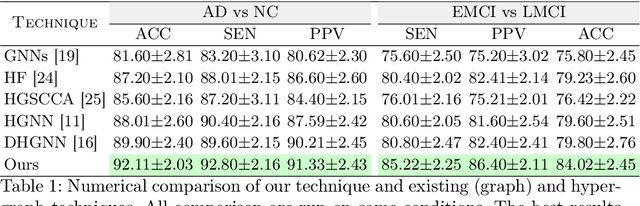
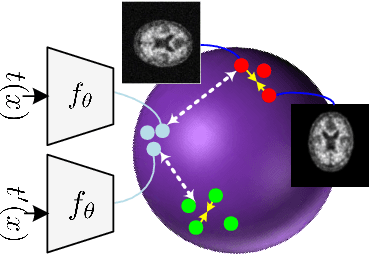
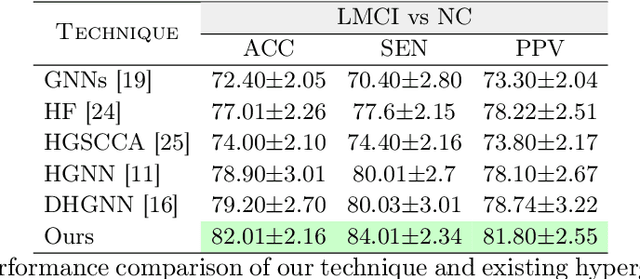
The automatic early diagnosis of prodromal stages of Alzheimer's disease is of great relevance for patient treatment to improve quality of life. We address this problem as a multi-modal classification task. Multi-modal data provides richer and complementary information. However, existing techniques only consider either lower order relations between the data and single/multi-modal imaging data. In this work, we introduce a novel semi-supervised hypergraph learning framework for Alzheimer's disease diagnosis. Our framework allows for higher-order relations among multi-modal imaging and non-imaging data whilst requiring a tiny labelled set. Firstly, we introduce a dual embedding strategy for constructing a robust hypergraph that preserves the data semantics. We achieve this by enforcing perturbation invariance at the image and graph levels using a contrastive based mechanism. Secondly, we present a dynamically adjusted hypergraph diffusion model, via a semi-explicit flow, to improve the predictive uncertainty. We demonstrate, through our experiments, that our framework is able to outperform current techniques for Alzheimer's disease diagnosis.
DFNet: Enhance Absolute Pose Regression with Direct Feature Matching
Apr 04, 2022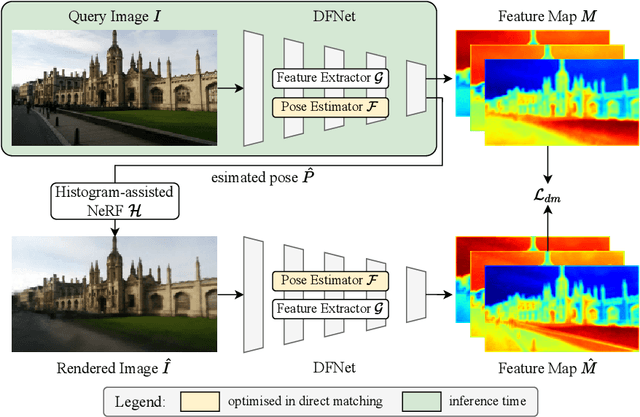
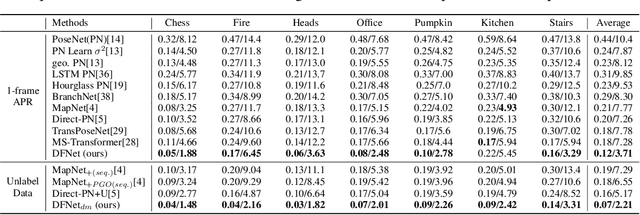
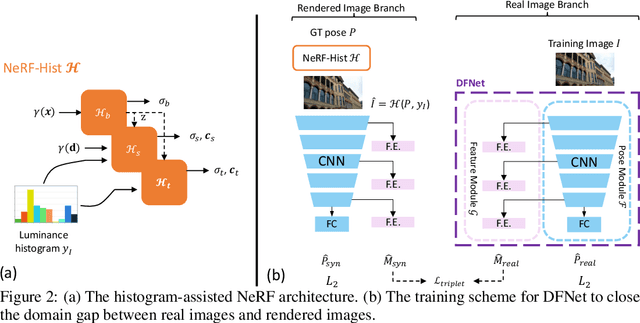
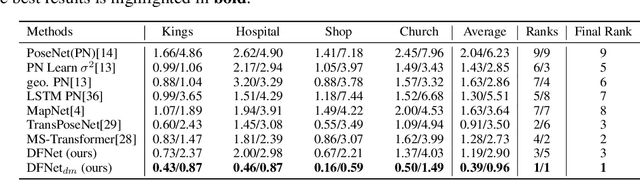
We introduce a camera relocalization pipeline that combines absolute pose regression (APR) and direct feature matching. Existing photometric-based methods have trouble on scenes with large photometric distortions, e.g. outdoor environments. By incorporating an exposure-adaptive novel view synthesis, our methods can successfully address the challenges. Moreover, by introducing domain-invariant feature matching, our solution can improve pose regression accuracy while using semi-supervised learning on unlabeled data. In particular, the pipeline consists of two components, Novel View Synthesizer and FeatureNet (DFNet). The former synthesizes novel views compensating for changes in exposure and the latter regresses camera poses and extracts robust features that bridge the domain gap between real images and synthetic ones. We show that domain invariant feature matching effectively enhances camera pose estimation both in indoor and outdoor scenes. Hence, our method achieves a state-of-the-art accuracy by outperforming existing single-image APR methods by as much as 56%, comparable to 3D structure-based methods.
Learning to Reconstruct 3D Non-Cuboid Room Layout from a Single RGB Image
Apr 16, 2021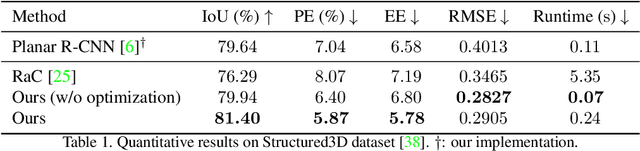
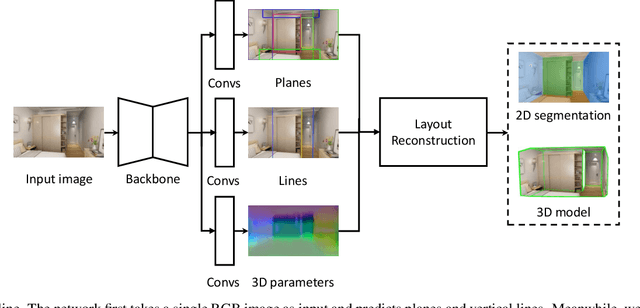
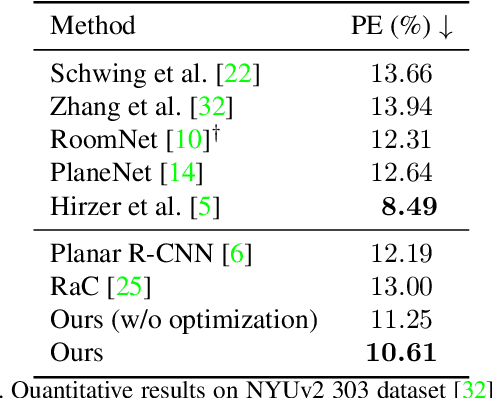

Single-image room layout reconstruction aims to reconstruct the enclosed 3D structure of a room from a single image. Most previous work relies on the cuboid-shape prior. This paper considers a more general indoor assumption, i.e., the room layout consists of a single ceiling, a single floor, and several vertical walls. To this end, we first employ Convolutional Neural Networks to detect planes and vertical lines between adjacent walls. Meanwhile, estimating the 3D parameters for each plane. Then, a simple yet effective geometric reasoning method is adopted to achieve room layout reconstruction. Furthermore, we optimize the 3D plane parameters to reconstruct a geometrically consistent room layout between planes and lines. The experimental results on public datasets validate the effectiveness and efficiency of our method.