 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VICTOR: Visual Incompatibility Detection with Transformers and Fashion-specific contrastive pre-training
Jul 27, 2022
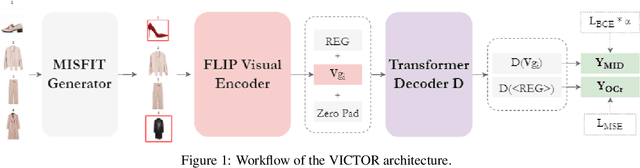
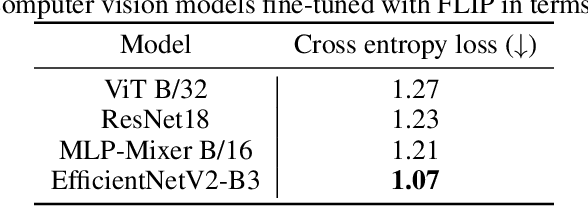
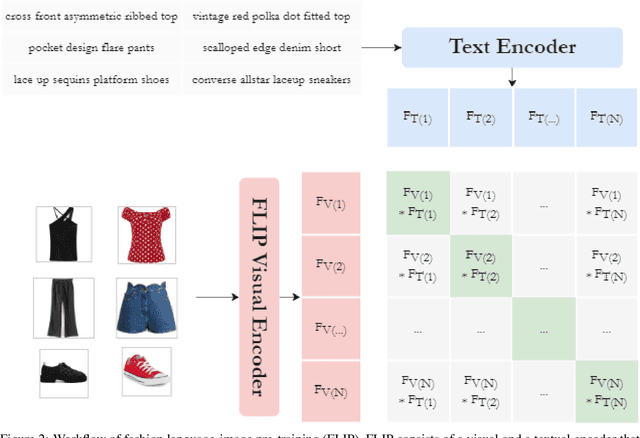

In order to consider fashion outfits as aesthetically pleasing, the garments that constitute them need to be compatible in terms of visual aspects, such as style, category and color. With the advent and omnipresence of computer vision deep learning models, increased interest has also emerged for the task of visual compatibility detection with the aim to develop quality fashion outfit recommendation systems. Previous works have defined visual compatibility as a binary classification task with items in a garment being considered as fully compatible or fully incompatible. However, this is not applicable to Outfit Maker applications where users create their own outfits and need to know which specific items may be incompatible with the rest of the outfit. To address this, we propose the Visual InCompatibility TransfORmer (VICTOR) that is optimized for two tasks: 1) overall compatibility as regression and 2) the detection of mismatching items. Unlike previous works that either rely on feature extraction from ImageNet-pretrained models or by end-to-end fine tuning, we utilize fashion-specific contrastive language-image pre-training for fine tuning computer vision neural networks on fashion imagery. Moreover, we build upon the Polyvore outfit benchmark to generate partially mismatching outfits, creating a new dataset termed Polyvore-MISFITs, that is used to train VICTOR. A series of ablation and comparative analyses show that the proposed architecture can compete and even surpass the current state-of-the-art on Polyvore datasets while reducing the instance-wise floating operations by 88%, striking a balance between high performance and efficiency.
Factorized and Controllable Neural Re-Rendering of Outdoor Scene for Photo Extrapolation
Jul 14, 2022
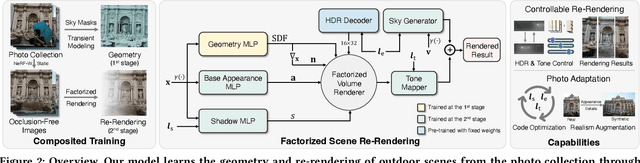
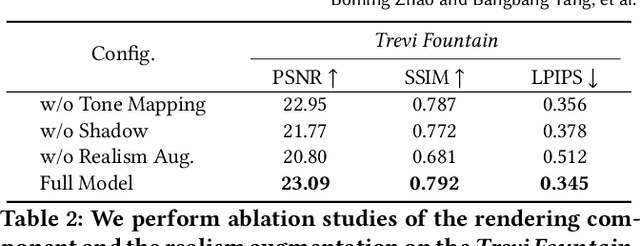
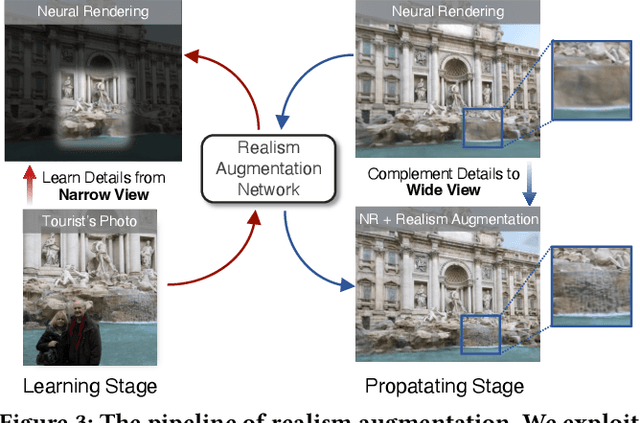
Expanding an existing tourist photo from a partially captured scene to a full scene is one of the desired experiences for photography applications. Although photo extrapolation has been well studied, it is much more challenging to extrapolate a photo (i.e., selfie) from a narrow field of view to a wider one while maintaining a similar visual style. In this paper, we propose a factorized neural re-rendering model to produce photorealistic novel views from cluttered outdoor Internet photo collections, which enables the applications including controllable scene re-rendering, photo extrapolation and even extrapolated 3D photo generation. Specifically, we first develop a novel factorized re-rendering pipeline to handle the ambiguity in the decomposition of geometry, appearance and illumination. We also propose a composited training strategy to tackle the unexpected occlusion in Internet images. Moreover, to enhance photo-realism when extrapolating tourist photographs, we propose a novel realism augmentation process to complement appearance details, which automatically propagates the texture details from a narrow captured photo to the extrapolated neural rendered image. The experiments and photo editing examples on outdoor scenes demonstrate the superior performance of our proposed method in both photo-realism and downstream applications.
The Open Kidney Ultrasound Data Set
Jun 14, 2022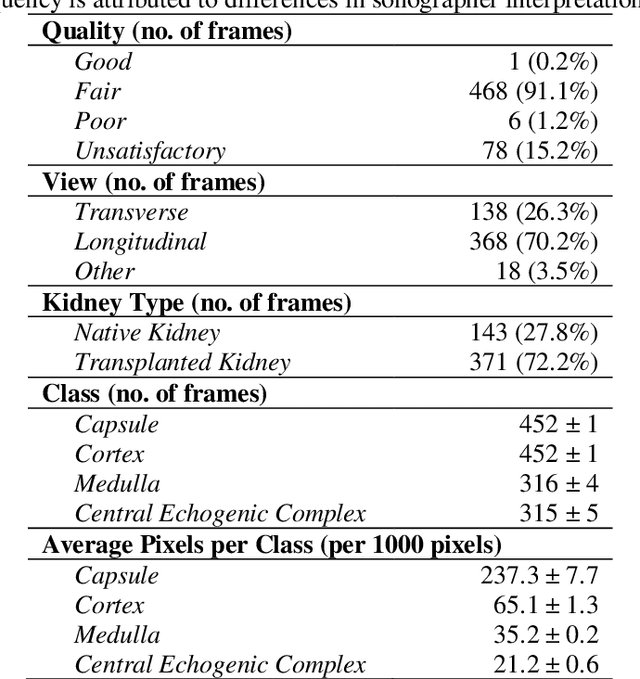
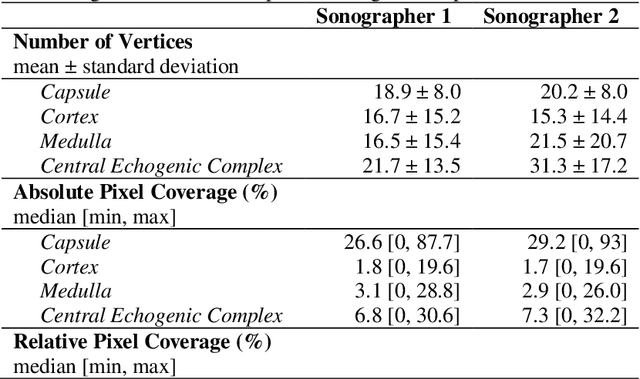

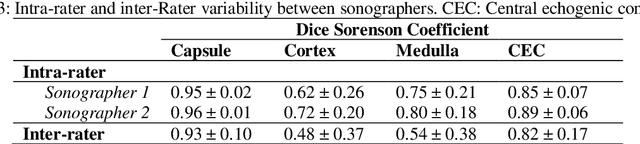
Ultrasound use is because of its low cost, non-ionizing, and non-invasive characteristics, and has established itself as a cornerstone radiological examination. Research on ultrasound applications has also expanded, especially with image analysis with machine learning. However, ultrasound data are frequently restricted to closed data sets, with only a few openly available. Despite being a frequently examined organ, the kidney lacks a publicly available ultrasonography data set. The proposed Open Kidney Ultrasound Data Set is the first publicly available set of kidney B-mode ultrasound data that includes annotations for multi-class semantic segmentation. It is based on data retrospectively collected in a 5-year period from over 500 patients with a mean age of 53.2 +/- 14.7 years, body mass index of 27.0 +/- 5.4 kg/m2, and most common primary diseases being diabetes mellitus, IgA nephropathy, and hypertension. There are labels for the view and fine-grained manual annotations from two expert sonographers. Notably, this data includes native and transplanted kidneys. Initial benchmarking measurements are performed, demonstrating a state-of-the-art algorithm achieving a Dice Sorenson Coefficient of 0.74 for the kidney capsule. This data set is a high-quality data set, including two sets of expert annotations, with a larger breadth of images than previously available. In increasing access to kidney ultrasound data, future researchers may be able to create novel image analysis techniques for tissue characterization, disease detection, and prognostication.
Layered Depth Refinement with Mask Guidance
Jun 07, 2022
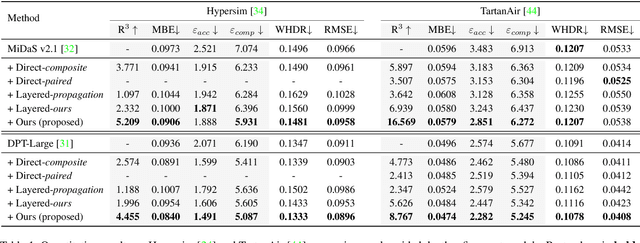
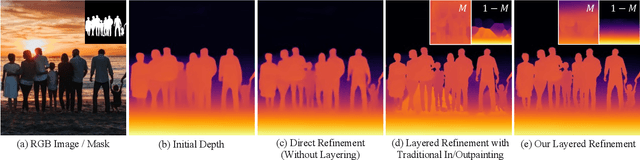
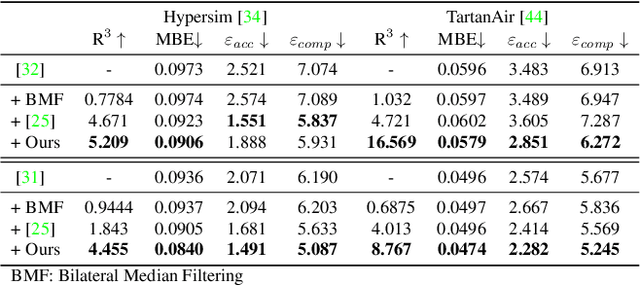
Depth maps are used in a wide range of applications from 3D rendering to 2D image effects such as Bokeh. However, those predicted by single image depth estimation (SIDE) models often fail to capture isolated holes in objects and/or have inaccurate boundary regions. Meanwhile, high-quality masks are much easier to obtain, using commercial auto-masking tools or off-the-shelf methods of segmentation and matting or even by manual editing. Hence, in this paper, we formulate a novel problem of mask-guided depth refinement that utilizes a generic mask to refine the depth prediction of SIDE models. Our framework performs layered refinement and inpainting/outpainting, decomposing the depth map into two separate layers signified by the mask and the inverse mask. As datasets with both depth and mask annotations are scarce, we propose a self-supervised learning scheme that uses arbitrary masks and RGB-D datasets. We empirically show that our method is robust to different types of masks and initial depth predictions, accurately refining depth values in inner and outer mask boundary regions. We further analyze our model with an ablation study and demonstrate results on real applications. More information can be found at https://sooyekim.github.io/MaskDepth/ .
DSNet: A Dual-Stream Framework for Weakly-Supervised Gigapixel Pathology Image Analysis
Sep 13, 2021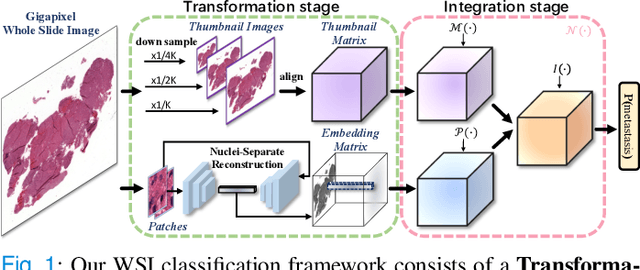
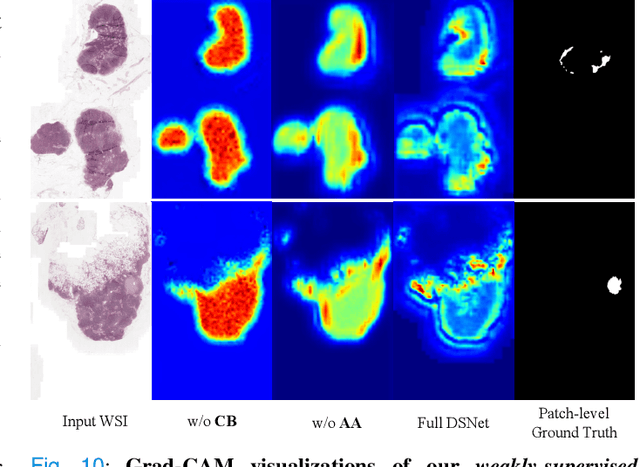
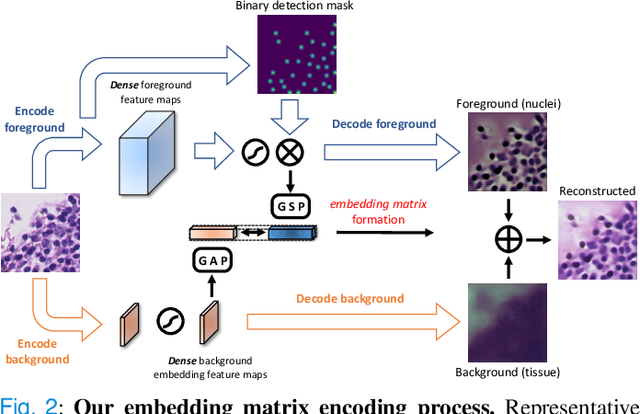
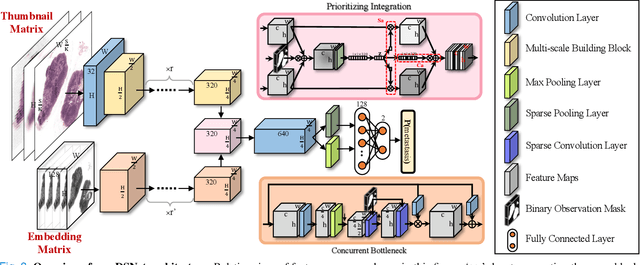
We present a novel weakly-supervised framework for classifying whole slide images (WSIs). WSIs, due to their gigapixel resolution, are commonly processed by patch-wise classification with patch-level labels. However, patch-level labels require precise annotations, which is expensive and usually unavailable on clinical data. With image-level labels only, patch-wise classification would be sub-optimal due to inconsistency between the patch appearance and image-level label. To address this issue, we posit that WSI analysis can be effectively conducted by integrating information at both high magnification (local) and low magnification (regional) levels. We auto-encode the visual signals in each patch into a latent embedding vector representing local information, and down-sample the raw WSI to hardware-acceptable thumbnails representing regional information. The WSI label is then predicted with a Dual-Stream Network (DSNet), which takes the transformed local patch embeddings and multi-scale thumbnail images as inputs and can be trained by the image-level label only. Experiments conducted on two large-scale public datasets demonstrate that our method outperforms all recent state-of-the-art weakly-supervised WSI classification methods.
FaceSigns: Semi-Fragile Neural Watermarks for Media Authentication and Countering Deepfakes
Apr 05, 2022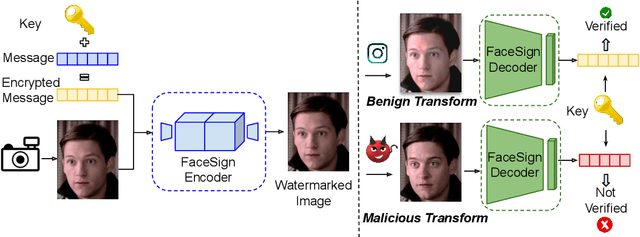
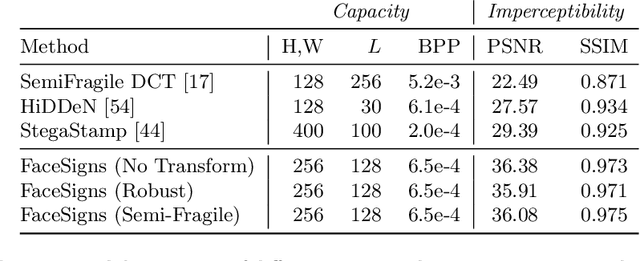
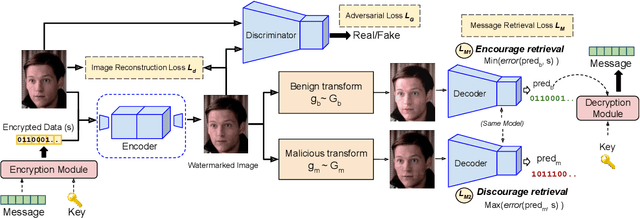
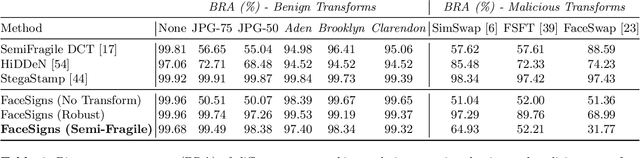
Deepfakes and manipulated media are becoming a prominent threat due to the recent advances in realistic image and video synthesis techniques. There have been several attempts at combating Deepfakes using machine learning classifiers. However, such classifiers do not generalize well to black-box image synthesis techniques and have been shown to be vulnerable to adversarial examples. To address these challenges, we introduce a deep learning based semi-fragile watermarking technique that allows media authentication by verifying an invisible secret message embedded in the image pixels. Instead of identifying and detecting fake media using visual artifacts, we propose to proactively embed a semi-fragile watermark into a real image so that we can prove its authenticity when needed. Our watermarking framework is designed to be fragile to facial manipulations or tampering while being robust to benign image-processing operations such as image compression, scaling, saturation, contrast adjustments etc. This allows images shared over the internet to retain the verifiable watermark as long as face-swapping or any other Deepfake modification technique is not applied. We demonstrate that FaceSigns can embed a 128 bit secret as an imperceptible image watermark that can be recovered with a high bit recovery accuracy at several compression levels, while being non-recoverable when unseen Deepfake manipulations are applied. For a set of unseen benign and Deepfake manipulations studied in our work, FaceSigns can reliably detect manipulated content with an AUC score of 0.996 which is significantly higher than prior image watermarking and steganography techniques.
Reverse image filtering using total derivative approximation and accelerated gradient descent
Dec 13, 2021
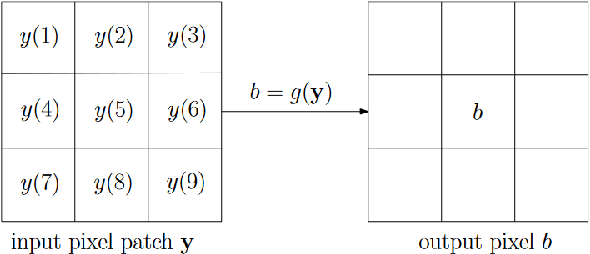
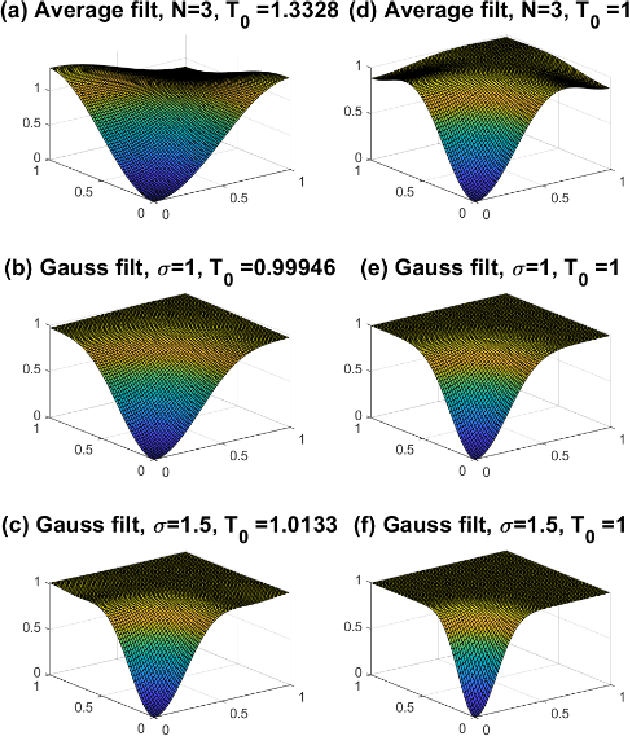

In this paper, we address a new problem of reversing the effect of an image filter, which can be linear or nonlinear. The assumption is that the algorithm of the filter is unknown and the filter is available as a black box. We formulate this inverse problem as minimizing a local patch-based cost function and use total derivative to approximate the gradient which is used in gradient descent to solve the problem. We analyze factors affecting the convergence and quality of the output in the Fourier domain. We also study the application of accelerated gradient descent algorithms in three gradient-free reverse filters, including the one proposed in this paper. We present results from extensive experiments to evaluate the complexity and effectiveness of the proposed algorithm. Results demonstrate that the proposed algorithm outperforms the state-of-the-art in that (1) it is at the same level of complexity as that of the fastest reverse filter, but it can reverse a larger number of filters, and (2) it can reverse the same list of filters as that of the very complex reverse filter, but its complexity is much smaller.
IREM: High-Resolution Magnetic Resonance (MR) Image Reconstruction via Implicit Neural Representation
Jun 29, 2021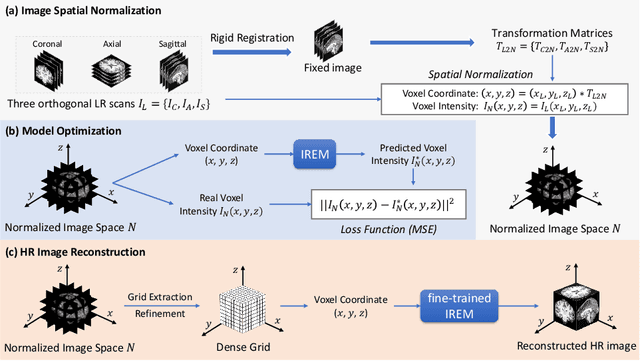
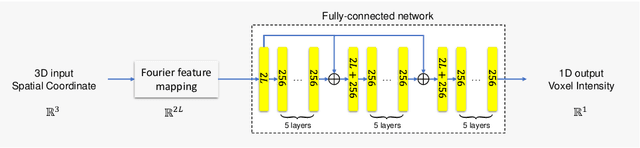
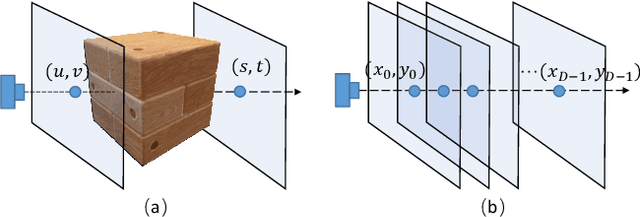
For collecting high-quality high-resolution (HR) MR image, we propose a novel image reconstruction network named IREM, which is trained on multiple low-resolution (LR) MR images and achieve an arbitrary up-sampling rate for HR image reconstruction. In this work, we suppose the desired HR image as an implicit continuous function of the 3D image spatial coordinate and the thick-slice LR images as several sparse discrete samplings of this function. Then the super-resolution (SR) task is to learn the continuous volumetric function from a limited observations using an fully-connected neural network combined with Fourier feature positional encoding. By simply minimizing the error between the network prediction and the acquired LR image intensity across each imaging plane, IREM is trained to represent a continuous model of the observed tissue anatomy. Experimental results indicate that IREM succeeds in representing high frequency image feature, and in real scene data collection, IREM reduces scan time and achieves high-quality high-resolution MR imaging in terms of SNR and local image detail.
Progressively-connected Light Field Network for Efficient View Synthesis
Jul 10, 2022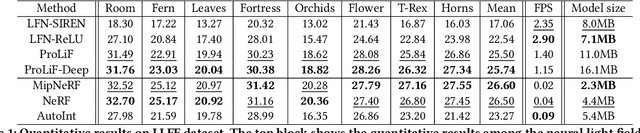


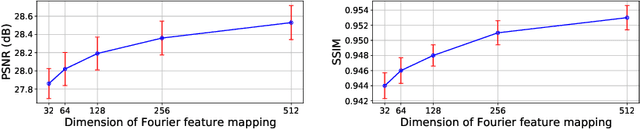
This paper presents a Progressively-connected Light Field network (ProLiF), for the novel view synthesis of complex forward-facing scenes. ProLiF encodes a 4D light field, which allows rendering a large batch of rays in one training step for image- or patch-level losses. Directly learning a neural light field from images has difficulty in rendering multi-view consistent images due to its unawareness of the underlying 3D geometry. To address this problem, we propose a progressive training scheme and regularization losses to infer the underlying geometry during training, both of which enforce the multi-view consistency and thus greatly improves the rendering quality. Experiments demonstrate that our method is able to achieve significantly better rendering quality than the vanilla neural light fields and comparable results to NeRF-like rendering methods on the challenging LLFF dataset and Shiny Object dataset. Moreover, we demonstrate better compatibility with LPIPS loss to achieve robustness to varying light conditions and CLIP loss to control the rendering style of the scene. Project page: https://totoro97.github.io/projects/prolif.
ACPL: Anti-curriculum Pseudo-labelling for Semi-supervised Medical Image Classification
Dec 19, 2021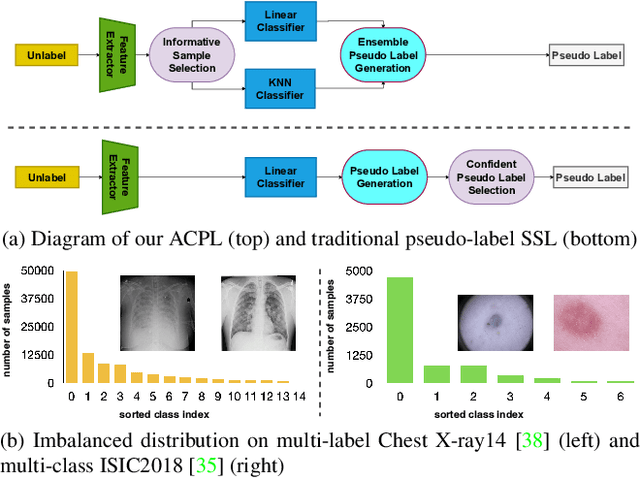
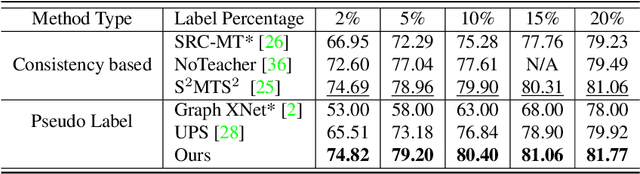
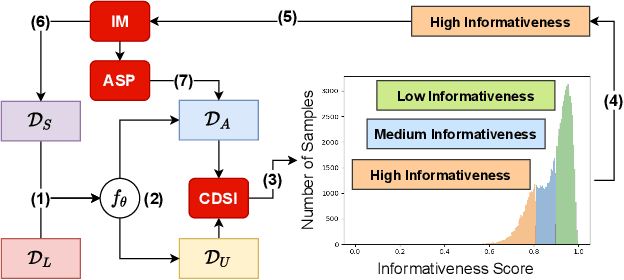
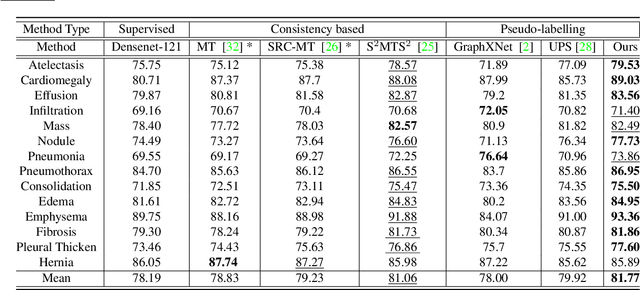
Effective semi-supervised learning (SSL) in medical im-age analysis (MIA) must address two challenges: 1) workeffectively on both multi-class (e.g., lesion classification)and multi-label (e.g., multiple-disease diagnosis) problems,and 2) handle imbalanced learning (because of the highvariance in disease prevalence). One strategy to explorein SSL MIA is based on the pseudo labelling strategy, butit has a few shortcomings. Pseudo-labelling has in generallower accuracy than consistency learning, it is not specifi-cally design for both multi-class and multi-label problems,and it can be challenged by imbalanced learning. In this paper, unlike traditional methods that select confident pseudo label by threshold, we propose a new SSL algorithm, called anti-curriculum pseudo-labelling (ACPL), which introduces novel techniques to select informative unlabelled samples, improving training balance and allowing the model to work for both multi-label and multi-class problems, and to estimate pseudo labels by an accurate ensemble of classifiers(improving pseudo label accuracy). We run extensive experiments to evaluate ACPL on two public medical image classification benchmarks: Chest X-Ray14 for thorax disease multi-label classification and ISIC2018 for skin lesion multi-class classification. Our method outperforms previous SOTA SSL methods on both datasets.