 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Humor, Art, or Misinformation?": A Multimodal Dataset for Intent-Aware Synthetic Image Detection
Aug 28, 2025Recent advances in multimodal AI have enabled progress in detecting synthetic and out-of-context content. However, existing efforts largely overlook the intent behind AI-generated images. To fill this gap, we introduce S-HArM, a multimodal dataset for intent-aware classification, comprising 9,576 "in the wild" image-text pairs from Twitter/X and Reddit, labeled as Humor/Satire, Art, or Misinformation. Additionally, we explore three prompting strategies (image-guided, description-guided, and multimodally-guided) to construct a large-scale synthetic training dataset with Stable Diffusion. We conduct an extensive comparative study including modality fusion, contrastive learning, reconstruction networks, attention mechanisms, and large vision-language models. Our results show that models trained on image- and multimodally-guided data generalize better to "in the wild" content, due to preserved visual context. However, overall performance remains limited, highlighting the complexity of inferring intent and the need for specialized architectures.
Latent Multimodal Reconstruction for Misinformation Detection
Apr 08, 2025Multimodal misinformation, such as miscaptioned images, where captions misrepresent an image's origin, context, or meaning, poses a growing challenge in the digital age. To support fact-checkers, researchers have been focusing on creating datasets and developing methods for multimodal misinformation detection (MMD). Due to the scarcity of large-scale annotated MMD datasets, recent studies leverage synthetic training data via out-of-context image-caption pairs or named entity manipulations; altering names, dates, and locations. However, these approaches often produce simplistic misinformation that fails to reflect real-world complexity, limiting the robustness of detection models trained on them. Meanwhile, despite recent advancements, Large Vision-Language Models (LVLMs) remain underutilized for generating diverse, realistic synthetic training data for MMD. To address this gap, we introduce "MisCaption This!", a training dataset comprising LVLM-generated miscaptioned images. Additionally, we introduce "Latent Multimodal Reconstruction" (LAMAR), a network trained to reconstruct the embeddings of truthful captions, providing a strong auxiliary signal to the detection process. To optimize LAMAR, we explore different training strategies (end-to-end training and large-scale pre-training) and integration approaches (direct, mask, gate, and attention). Extensive experiments show that models trained on "MisCaption This!" generalize better on real-world misinformation, while LAMAR sets new state-of-the-art on both NewsCLIPpings and VERITE benchmarks; highlighting the potential of LVLM-generated data and reconstruction-based approaches for advancing MMD. We release our code at: https://github.com/stevejpapad/miscaptioned-image-reconstruction
Similarity over Factuality: Are we making progress on multimodal out-of-context misinformation detection?
Jul 18, 2024



Out-of-context (OOC) misinformation poses a significant challenge in multimodal fact-checking, where images are paired with texts that misrepresent their original context to support false narratives. Recent research in evidence-based OOC detection has seen a trend towards increasingly complex architectures, incorporating Transformers, foundation models, and large language models. In this study, we introduce a simple yet robust baseline, which assesses MUltimodal SimilaritiEs (MUSE), specifically the similarity between image-text pairs and external image and text evidence. Our results demonstrate that MUSE, when used with conventional classifiers like Decision Tree, Random Forest, and Multilayer Perceptron, can compete with and even surpass the state-of-the-art on the NewsCLIPpings and VERITE datasets. Furthermore, integrating MUSE in our proposed "Attentive Intermediate Transformer Representations" (AITR) significantly improved performance, by 3.3% and 7.5% on NewsCLIPpings and VERITE, respectively. Nevertheless, the success of MUSE, relying on surface-level patterns and shortcuts, without examining factuality and logical inconsistencies, raises critical questions about how we define the task, construct datasets, collect external evidence and overall, how we assess progress in the field. We release our code at: https://github.com/stevejpapad/outcontext-misinfo-progress
Credible, Unreliable or Leaked?: Evidence Verification for Enhanced Automated Fact-checking
Apr 29, 2024



Automated fact-checking (AFC) is garnering increasing attention by researchers aiming to help fact-checkers combat the increasing spread of misinformation online. While many existing AFC methods incorporate external information from the Web to help examine the veracity of claims, they often overlook the importance of verifying the source and quality of collected "evidence". One overlooked challenge involves the reliance on "leaked evidence", information gathered directly from fact-checking websites and used to train AFC systems, resulting in an unrealistic setting for early misinformation detection. Similarly, the inclusion of information from unreliable sources can undermine the effectiveness of AFC systems. To address these challenges, we present a comprehensive approach to evidence verification and filtering. We create the "CREDible, Unreliable or LEaked" (CREDULE) dataset, which consists of 91,632 articles classified as Credible, Unreliable and Fact checked (Leaked). Additionally, we introduce the EVidence VERification Network (EVVER-Net), trained on CREDULE to detect leaked and unreliable evidence in both short and long texts. EVVER-Net can be used to filter evidence collected from the Web, thus enhancing the robustness of end-to-end AFC systems. We experiment with various language models and show that EVVER-Net can demonstrate impressive performance of up to 91.5% and 94.4% accuracy, while leveraging domain credibility scores along with short or long texts, respectively. Finally, we assess the evidence provided by widely-used fact-checking datasets including LIAR-PLUS, MOCHEG, FACTIFY, NewsCLIPpings+ and VERITE, some of which exhibit concerning rates of leaked and unreliable evidence.
RED-DOT: Multimodal Fact-checking via Relevant Evidence Detection
Nov 16, 2023



Online misinformation is often multimodal in nature, i.e., it is caused by misleading associations between texts and accompanying images. To support the fact-checking process, researchers have been recently developing automatic multimodal methods that gather and analyze external information, evidence, related to the image-text pairs under examination. However, prior works assumed all collected evidence to be relevant. In this study, we introduce a "Relevant Evidence Detection" (RED) module to discern whether each piece of evidence is relevant, to support or refute the claim. Specifically, we develop the "Relevant Evidence Detection Directed Transformer" (RED-DOT) and explore multiple architectural variants (e.g., single or dual-stage) and mechanisms (e.g., "guided attention"). Extensive ablation and comparative experiments demonstrate that RED-DOT achieves significant improvements over the state-of-the-art on the VERITE benchmark by up to 28.5%. Furthermore, our evidence re-ranking and element-wise modality fusion led to RED-DOT achieving competitive and even improved performance on NewsCLIPings+, without the need for numerous evidence or multiple backbone encoders. Finally, our qualitative analysis demonstrates that the proposed "guided attention" module has the potential to enhance the architecture's interpretability. We release our code at: https://github.com/stevejpapad/relevant-evidence-detection
Figments and Misalignments: A Framework for Fine-grained Crossmodal Misinformation Detection
Apr 27, 2023Multimedia content has become ubiquitous on social media platforms, leading to the rise of multimodal misinformation and the urgent need for effective strategies to detect and prevent its spread. This study focuses on CrossModal Misinformation (CMM) where image-caption pairs work together to spread falsehoods. We contrast CMM with Asymmetric Multimodal Misinformation (AMM), where one dominant modality propagates falsehoods while other modalities have little or no influence. We show that AMM adds noise to the training and evaluation process while exacerbating the unimodal bias, where text-only or image-only detectors can seemingly outperform their multimodal counterparts on an inherently multimodal task. To address this issue, we collect and curate FIGMENTS, a robust evaluation benchmark for CMM, which consists of real world cases of misinformation, excludes AMM and utilizes modality balancing to successfully alleviate unimodal bias. FIGMENTS also provides a first step towards fine-grained CMM detection by including three classes: truthful, out-of-context, and miscaptioned image-caption pairs. Furthermore, we introduce a method for generating realistic synthetic training data that maintains crossmodal relations between legitimate images and false human-written captions that we term Crossmodal HArd Synthetic MisAlignment (CHASMA). We conduct extensive comparative study using a Transformer-based architecture. Our results show that incorporating CHASMA in conjunction with other generated datasets consistently improved the overall performance on FIGMENTS in both binary (+6.26%) and multiclass settings (+15.8%).We release our code at: https://github.com/stevejpapad/figments-and-misalignments
Synthetic Misinformers: Generating and Combating Multimodal Misinformation
Mar 02, 2023



With the expansion of social media and the increasing dissemination of multimedia content, the spread of misinformation has become a major concern. This necessitates effective strategies for multimodal misinformation detection (MMD) that detect whether the combination of an image and its accompanying text could mislead or misinform. Due to the data-intensive nature of deep neural networks and the labor-intensive process of manual annotation, researchers have been exploring various methods for automatically generating synthetic multimodal misinformation - which we refer to as Synthetic Misinformers - in order to train MMD models. However, limited evaluation on real-world misinformation and a lack of comparisons with other Synthetic Misinformers makes difficult to assess progress in the field. To address this, we perform a comparative study on existing and new Synthetic Misinformers that involves (1) out-of-context (OOC) image-caption pairs, (2) cross-modal named entity inconsistency (NEI) as well as (3) hybrid approaches and we evaluate them against real-world misinformation; using the COSMOS benchmark. The comparative study showed that our proposed CLIP-based Named Entity Swapping can lead to MMD models that surpass other OOC and NEI Misinformers in terms of multimodal accuracy and that hybrid approaches can lead to even higher detection accuracy. Nevertheless, after alleviating information leakage from the COSMOS evaluation protocol, low Sensitivity scores indicate that the task is significantly more challenging than previous studies suggested. Finally, our findings showed that NEI-based Synthetic Misinformers tend to suffer from a unimodal bias, where text-only MMDs can outperform multimodal ones.
Design-time Fashion Popularity Forecasting in VR Environments
Dec 14, 2022



Being able to forecast the popularity of new garment designs is very important in an industry as fast paced as fashion, both in terms of profitability and reducing the problem of unsold inventory. Here, we attempt to address this task in order to provide informative forecasts to fashion designers within a virtual reality designer application that will allow them to fine tune their creations based on current consumer preferences within an interactive and immersive environment. To achieve this we have to deal with the following central challenges: (1) the proposed method should not hinder the creative process and thus it has to rely only on the garment's visual characteristics, (2) the new garment lacks historical data from which to extrapolate their future popularity and (3) fashion trends in general are highly dynamical. To this end, we develop a computer vision pipeline fine tuned on fashion imagery in order to extract relevant visual features along with the category and attributes of the garment. We propose a hierarchical label sharing (HLS) pipeline for automatically capturing hierarchical relations among fashion categories and attributes. Moreover, we propose MuQAR, a Multimodal Quasi-AutoRegressive neural network that forecasts the popularity of new garments by combining their visual features and categorical features while an autoregressive neural network is modelling the popularity time series of the garment's category and attributes. Both the proposed HLS and MuQAR prove capable of surpassing the current state-of-the-art in key benchmark datasets, DeepFashion for image classification and VISUELLE for new garment sales forecasting.
VICTOR: Visual Incompatibility Detection with Transformers and Fashion-specific contrastive pre-training
Jul 27, 2022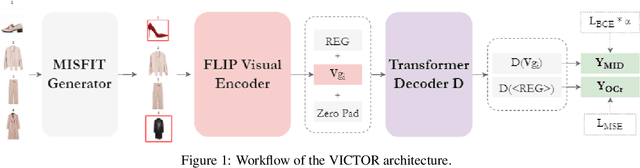
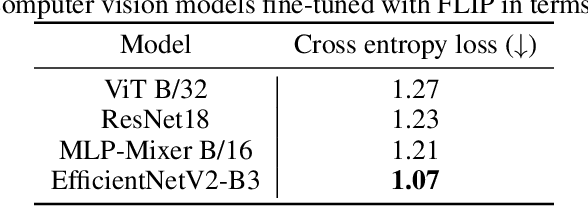
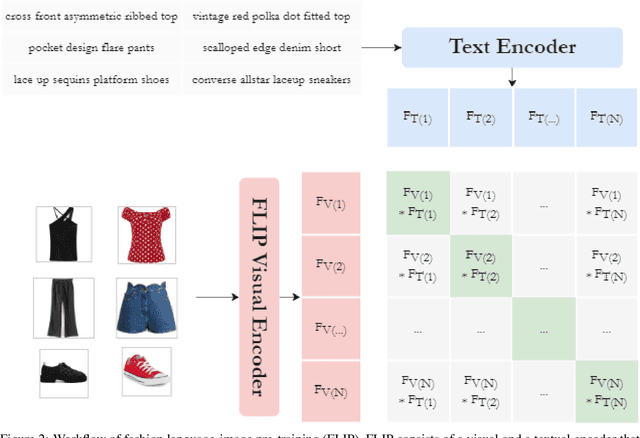

In order to consider fashion outfits as aesthetically pleasing, the garments that constitute them need to be compatible in terms of visual aspects, such as style, category and color. With the advent and omnipresence of computer vision deep learning models, increased interest has also emerged for the task of visual compatibility detection with the aim to develop quality fashion outfit recommendation systems. Previous works have defined visual compatibility as a binary classification task with items in a garment being considered as fully compatible or fully incompatible. However, this is not applicable to Outfit Maker applications where users create their own outfits and need to know which specific items may be incompatible with the rest of the outfit. To address this, we propose the Visual InCompatibility TransfORmer (VICTOR) that is optimized for two tasks: 1) overall compatibility as regression and 2) the detection of mismatching items. Unlike previous works that either rely on feature extraction from ImageNet-pretrained models or by end-to-end fine tuning, we utilize fashion-specific contrastive language-image pre-training for fine tuning computer vision neural networks on fashion imagery. Moreover, we build upon the Polyvore outfit benchmark to generate partially mismatching outfits, creating a new dataset termed Polyvore-MISFITs, that is used to train VICTOR. A series of ablation and comparative analyses show that the proposed architecture can compete and even surpass the current state-of-the-art on Polyvore datasets while reducing the instance-wise floating operations by 88%, striking a balance between high performance and efficiency.