 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTool-Aware Optimization with Entropy Guidance for Efficient Agentic Reinforcement Learning
Jun 02, 2026Agentic reinforcement learning (RL) equips large language models (LLMs) with tool-use capabilities that substantially improve reasoning on complex tasks. However, integrating external tools often destabilizes training: over-reliance on tools can induce input distribution shift, while overly conservative tool use limits effective exploration. To address this issue, we propose a unified framework TAO-RL that couples tool-aware trajectory filtering with entropy-guided exploration for efficient policy optimization. Specifically, at the data level, TAO-RL filters rollout trajectories along two criteria: discarding those where all tool invocations fail to execute, and removing those where all rollouts are either correct or incorrect, as both cases yield degenerate advantage estimates that contribute no discriminative learning signal. This joint filtering retains data that are both tool-capable and informative, establishing a high-quality training distribution. At the algorithmic level, we introduce a tool-aware entropy-guided bonus that reshapes the advantage function at post-tool-call tokens, encouraging the policy to explore more diverse reasoning paths at critical decision points. These two components are mutually reinforcing: trajectory filtering establishes a clean and informative training foundation, while entropy-guided exploration drives stronger reasoning behaviors at critical tool-interaction junctures. Extensive experiments on 7 challenging reasoning benchmarks across 3 model scales demonstrate the superiority of TAO-RL over existing methods.
JT-SAFE-V2: Safety-by-Design Foundation Model with World-Context Data
May 23, 2026We introduce JT-Safe-V2, a large language model designed to advance the safety and trustworthiness of foundation models, extending our previous JT-Safe model toward a more comprehensive safety-by-design paradigm. JT-Safe-V2 emphasizes the joint optimization of general intelligence and safety-by-design through several key innovations: enriching pre-training data with contextual world knowledge, high-certainty pre-training procedures, and safety strengthening post-training mechanisms for enterprise-oriented agentic capabilities. Building on these safety-enhanced foundation models, we propose Safe-MoMA (Safe Mixture of Models and Agents), a framework that enables traceable and efficient inference through the orchestrated deployment of multiple models and agents. Extensive evaluations demonstrate that JT-Safe-V2 achieves state-of-the-art performance across both general intelligence and safety benchmarks. Moreover, Safe-MoMA reduces inference costs by more than 30\% compared to using the largest standalone model baseline while maintaining comparable performance. To facilitate future research on safety-by-design foundation models, we publicly release the post-trained JT-Safe-V2-35B model checkpoint.
Disentangled Learning Improves Implicit Neural Representations for Medical Reconstruction
May 05, 2026Implicit neural representations (INRs) have emerged as a powerful paradigm for medical imaging via physics-informed unsupervised learning. Classical INRs optimize an entire network from scratch for each subject, leading to inefficient training and suboptimal imaging quality. Recent initialization-based approaches attempt to inject population priors into pre-trained networks, yet they rely on high-quality images and often suffer from catastrophic forgetting during fine-tuning. We present DisINR, a novel INR framework that explicitly disentangles shared and subject-specific representations. DisINR introduces a shared encoder-decoder pair and subject-specific encoders, whose features are jointly decoded for image reconstruction. By integrating differentiable forward models, it pre-trains the shared modules directly from limited raw measurements, removing the need for pre-acquired high-quality images. During test-time adaptation, only the subject-specific encoder is optimized, while the shared pair remains frozen, effectively preserving learned priors. Extensive evaluations on three representative medical imaging tasks show that DisINR significantly outperforms state-of-the-art INRs in both reconstruction accuracy and efficiency.
Zero-shot Low-Field MRI Enhancement via Diffusion-Based Adaptive Contrast Transport
Mar 02, 2026Low-field (LF) magnetic resonance imaging (MRI) democratizes access to diagnostic imaging but is fundamentally limited by low signal-to-noise ratio and significant tissue contrast distortion due to field-dependent relaxation dynamics. Reconstructing high-field (HF) quality images from LF data is a blind inverse problem, severely challenged by the scarcity of paired training data and the unknown, non-linear contrast transformation operator. Existing zero-shot methods, which assume simplified linear degradation, often fail to recover authentic tissue contrast. In this paper, we propose DACT(Diffusion-Based Adaptive Contrast Transport), a novel zero-shot framework that restores HF-quality images without paired supervision. DACT synergizes a pre-trained HF diffusion prior to ensure anatomical fidelity with a physically-informed adaptive forward model. Specifically, we introduce a differentiable Sinkhorn optimal transport module that explicitly models and corrects the intensity distribution shift between LF and HF domains during the reverse diffusion process. This allows the framework to dynamically learn the intractable contrast mapping while preserving topological consistency. Extensive experiments on simulated and real clinical LF datasets demonstrate that DACT achieves state-of-the-art performance, yielding reconstructions with superior structural detail and correct tissue contrast.
Resolving Blind Inverse Problems under Dynamic Range Compression via Structured Forward Operator Modeling
Mar 02, 2026Recovering radiometric fidelity from unknown dynamic range compression (UDRC), such as low-light enhancement and HDR reconstruction, is a challenging blind inverse problem, due to the unknown forward model and irreversible information loss introduced by compression. To address this challenge, we first identify monotonicity as the fundamental physical invariant shared across UDRC tasks. Leveraging this insight, we introduce the \textbf{cascaded monotonic Bernstein} (CaMB) operator to parameterize the unknown forward model. CaMB enforces monotonicity as a hard architectural inductive bias, constraining optimization to physically consistent mappings and enabling robust and stable operator estimation. We further integrate CaMB with a plug-and-play diffusion framework, proposing \textbf{CaMB-Diff}. Within this framework, the diffusion model serves as a powerful geometric prior for structural and semantic recovery, while CaMB explicitly models and corrects radiometric distortions through a physically grounded forward operator. Extensive experiments on a variety of zero-shot UDRC tasks, including low-light enhancement, low-field MRI enhancement, and HDR reconstruction, demonstrate that CaMB-Diff significantly outperforms state-of-the-art zero-shot baselines in terms of both signal fidelity and physical consistency. Moreover, we empirically validate the effectiveness of the proposed CaMB parameterization in accurately modeling the unknown forward operator.
Plug-and-Play Diffusion Meets ADMM: Dual-Variable Coupling for Robust Medical Image Reconstruction
Feb 26, 2026Plug-and-Play diffusion prior (PnPDP) frameworks have emerged as a powerful paradigm for solving imaging inverse problems by treating pretrained generative models as modular priors. However, we identify a critical flaw in prevailing PnP solvers (e.g., based on HQS or Proximal Gradient): they function as memoryless operators, updating estimates solely based on instantaneous gradients. This lack of historical tracking inevitably leads to non-vanishing steady-state bias, where the reconstruction fails to strictly satisfy physical measurements under heavy corruption. To resolve this, we propose Dual-Coupled PnP Diffusion, which restores the classical dual variable to provide integral feedback, theoretically guaranteeing asymptotic convergence to the exact data manifold. However, this rigorous geometric coupling introduces a secondary challenge: the accumulated dual residuals exhibit spectrally colored, structured artifacts that violate the Additive White Gaussian Noise (AWGN) assumption of diffusion priors, causing severe hallucinations. To bridge this gap, we introduce Spectral Homogenization (SH), a frequency-domain adaptation mechanism that modulates these structured residuals into statistically compliant pseudo-AWGN inputs. This effectively aligns the solver's rigorous optimization trajectory with the denoiser's valid statistical manifold. Extensive experiments on CT and MRI reconstruction demonstrate that our approach resolves the bias-hallucination trade-off, achieving state-of-the-art fidelity with significantly accelerated convergence.
Improving 2D Diffusion Models for 3D Medical Imaging with Inter-Slice Consistent Stochasticity
Feb 04, 20263D medical imaging is in high demand and essential for clinical diagnosis and scientific research. Currently, diffusion models (DMs) have become an effective tool for medical imaging reconstruction thanks to their ability to learn rich, high-quality data priors. However, learning the 3D data distribution with DMs in medical imaging is challenging, not only due to the difficulties in data collection but also because of the significant computational burden during model training. A common compromise is to train the DMs on 2D data priors and reconstruct stacked 2D slices to address 3D medical inverse problems. However, the intrinsic randomness of diffusion sampling causes severe inter-slice discontinuities of reconstructed 3D volumes. Existing methods often enforce continuity regularizations along the z-axis, which introduces sensitive hyper-parameters and may lead to over-smoothing results. In this work, we revisit the origin of stochasticity in diffusion sampling and introduce Inter-Slice Consistent Stochasticity (ISCS), a simple yet effective strategy that encourages interslice consistency during diffusion sampling. Our key idea is to control the consistency of stochastic noise components during diffusion sampling, thereby aligning their sampling trajectories without adding any new loss terms or optimization steps. Importantly, the proposed ISCS is plug-and-play and can be dropped into any 2D trained diffusion based 3D reconstruction pipeline without additional computational cost. Experiments on several medical imaging problems show that our method can effectively improve the performance of medical 3D imaging problems based on 2D diffusion models. Our findings suggest that controlling inter-slice stochasticity is a principled and practically attractive route toward high-fidelity 3D medical imaging with 2D diffusion priors. The code is available at: https://github.com/duchenhe/ISCS
Thinking-Based Non-Thinking: Solving the Reward Hacking Problem in Training Hybrid Reasoning Models via Reinforcement Learning
Jan 08, 2026Large reasoning models (LRMs) have attracted much attention due to their exceptional performance. However, their performance mainly stems from thinking, a long Chain of Thought (CoT), which significantly increase computational overhead. To address this overthinking problem, existing work focuses on using reinforcement learning (RL) to train hybrid reasoning models that automatically decide whether to engage in thinking or not based on the complexity of the query. Unfortunately, using RL will suffer the the reward hacking problem, e.g., the model engages in thinking but is judged as not doing so, resulting in incorrect rewards. To mitigate this problem, existing works either employ supervised fine-tuning (SFT), which incurs high computational costs, or enforce uniform token limits on non-thinking responses, which yields limited mitigation of the problem. In this paper, we propose Thinking-Based Non-Thinking (TNT). It does not employ SFT, and sets different maximum token usage for responses not using thinking across various queries by leveraging information from the solution component of the responses using thinking. Experiments on five mathematical benchmarks demonstrate that TNT reduces token usage by around 50% compared to DeepSeek-R1-Distill-Qwen-1.5B/7B and DeepScaleR-1.5B, while significantly improving accuracy. In fact, TNT achieves the optimal trade-off between accuracy and efficiency among all tested methods. Additionally, the probability of reward hacking problem in TNT's responses, which are classified as not using thinking, remains below 10% across all tested datasets.
XDen-1K: A Density Field Dataset of Real-World Objects
Dec 11, 2025A deep understanding of the physical world is a central goal for embodied AI and realistic simulation. While current models excel at capturing an object's surface geometry and appearance, they largely neglect its internal physical properties. This omission is critical, as properties like volumetric density are fundamental for predicting an object's center of mass, stability, and interaction dynamics in applications ranging from robotic manipulation to physical simulation. The primary bottleneck has been the absence of large-scale, real-world data. To bridge this gap, we introduce XDen-1K, the first large-scale, multi-modal dataset designed for real-world physical property estimation, with a particular focus on volumetric density. The core of this dataset consists of 1,000 real-world objects across 148 categories, for which we provide comprehensive multi-modal data, including a high-resolution 3D geometric model with part-level annotations and a corresponding set of real-world biplanar X-ray scans. Building upon this data, we introduce a novel optimization framework that recovers a high-fidelity volumetric density field of each object from its sparse X-ray views. To demonstrate its practical value, we add X-ray images as a conditioning signal to an existing segmentation network and perform volumetric segmentation. Furthermore, we conduct experiments on downstream robotics tasks. The results show that leveraging the dataset can effectively improve the accuracy of center-of-mass estimation and the success rate of robotic manipulation. We believe XDen-1K will serve as a foundational resource and a challenging new benchmark, catalyzing future research in physically grounded visual inference and embodied AI.
Diffusion Model Regularized Implicit Neural Representation for CT Metal Artifact Reduction
Dec 09, 2025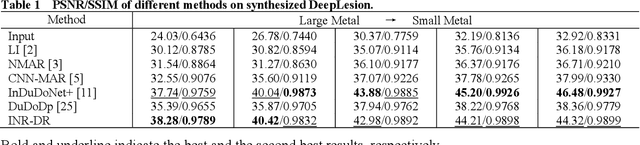
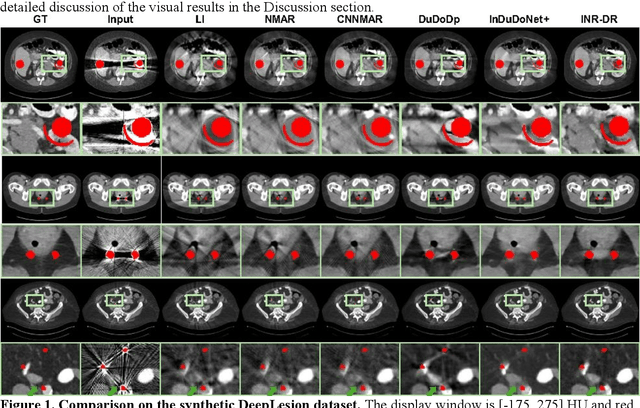
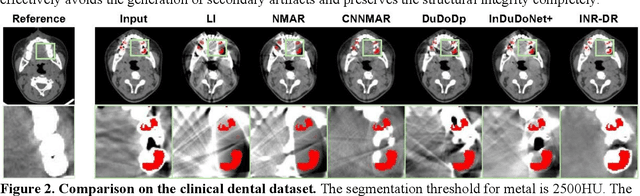

Computed tomography (CT) images are often severely corrupted by artifacts in the presence of metals. Existing supervised metal artifact reduction (MAR) approaches suffer from performance instability on known data due to their reliance on limited paired metal-clean data, which limits their clinical applicability. Moreover, existing unsupervised methods face two main challenges: 1) the CT physical geometry is not effectively incorporated into the MAR process to ensure data fidelity; 2) traditional heuristics regularization terms cannot fully capture the abundant prior knowledge available. To overcome these shortcomings, we propose diffusion model regularized implicit neural representation framework for MAR. The implicit neural representation integrates physical constraints and imposes data fidelity, while the pre-trained diffusion model provides prior knowledge to regularize the solution. Experimental results on both simulated and clinical data demonstrate the effectiveness and generalization ability of our method, highlighting its potential to be applied to clinical settings.