 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi PILOT: Learned Feasible Multiple Acquisition Trajectories for Dynamic MRI
Mar 13, 2023
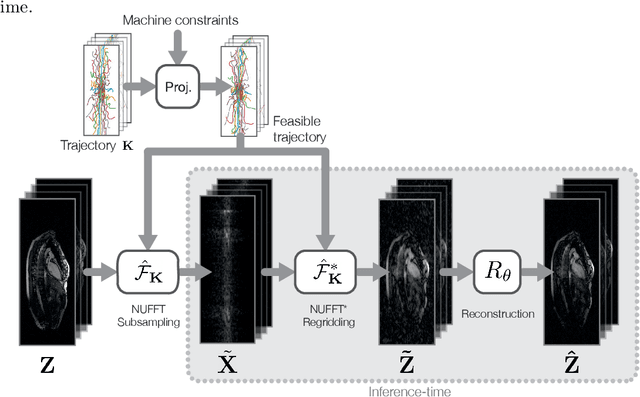
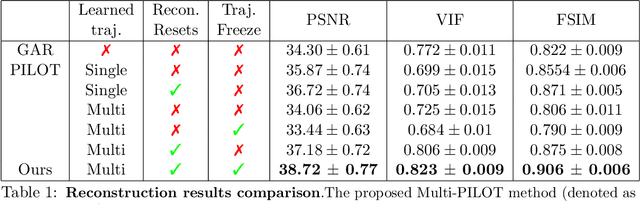
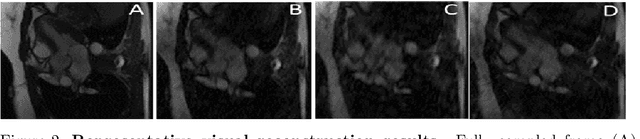
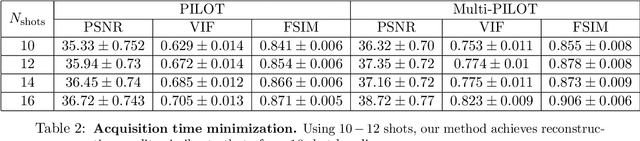
Dynamic Magnetic Resonance Imaging (MRI) is known to be a powerful and reliable technique for the dynamic imaging of internal organs and tissues, making it a leading diagnostic tool. A major difficulty in using MRI in this setting is the relatively long acquisition time (and, hence, increased cost) required for imaging in high spatio-temporal resolution, leading to the appearance of related motion artifacts and decrease in resolution. Compressed Sensing (CS) techniques have become a common tool to reduce MRI acquisition time by subsampling images in the k-space according to some acquisition trajectory. Several studies have particularly focused on applying deep learning techniques to learn these acquisition trajectories in order to attain better image reconstruction, rather than using some predefined set of trajectories. To the best of our knowledge, learning acquisition trajectories has been only explored in the context of static MRI. In this study, we consider acquisition trajectory learning in the dynamic imaging setting. We design an end-to-end pipeline for the joint optimization of multiple per-frame acquisition trajectories along with a reconstruction neural network, and demonstrate improved image reconstruction quality in shorter acquisition times. The code for reproducing all experiments is accessible at https://github.com/tamirshor7/MultiPILOT.
Text-driven Visual Synthesis with Latent Diffusion Prior
Feb 16, 2023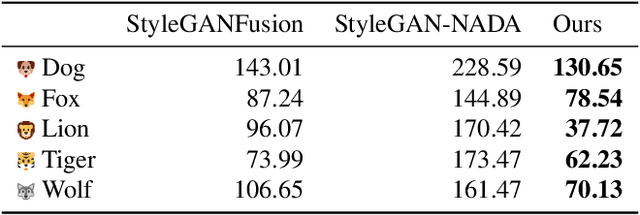
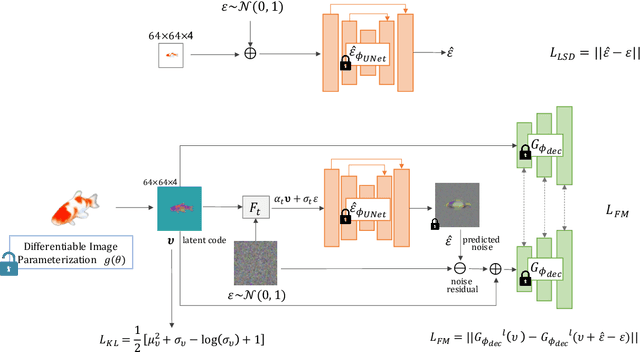
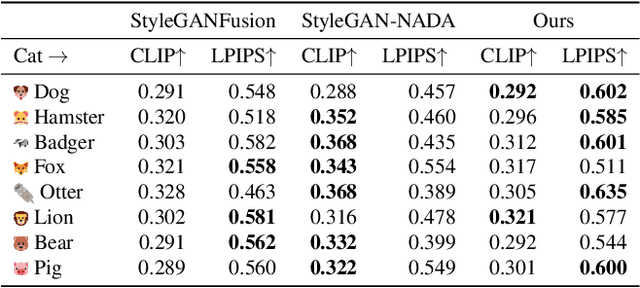

There has been tremendous progress in large-scale text-to-image synthesis driven by diffusion models enabling versatile downstream applications such as 3D object synthesis from texts, image editing, and customized generation. We present a generic approach using latent diffusion models as powerful image priors for various visual synthesis tasks. Existing methods that utilize such priors fail to use these models' full capabilities. To improve this, our core ideas are 1) a feature matching loss between features from different layers of the decoder to provide detailed guidance and 2) a KL divergence loss to regularize the predicted latent features and stabilize the training. We demonstrate the efficacy of our approach on three different applications, text-to-3D, StyleGAN adaptation, and layered image editing. Extensive results show our method compares favorably against baselines.
Surrogate Lagrangian Relaxation: A Path To Retrain-free Deep Neural Network Pruning
Apr 08, 2023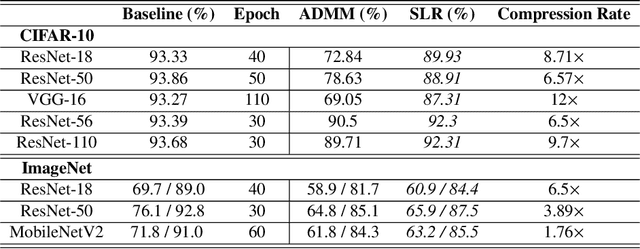
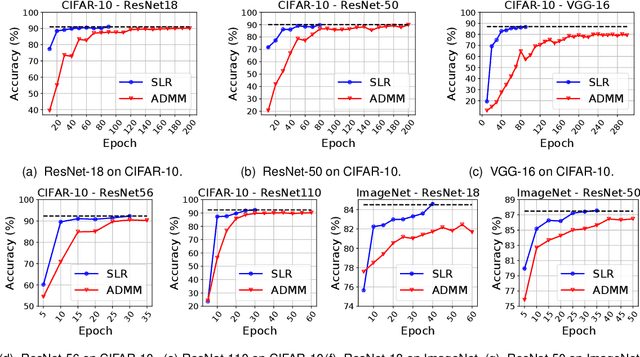
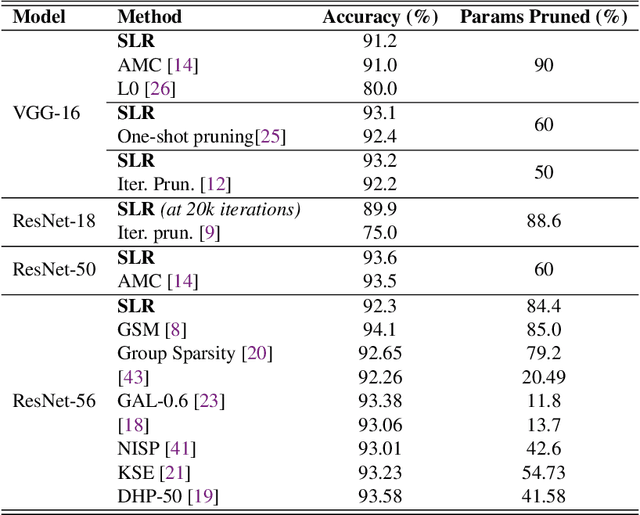
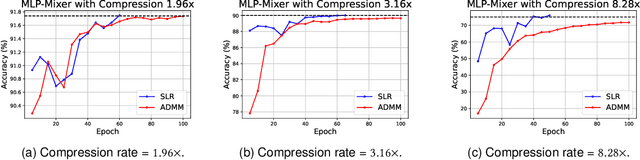
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline significantly increases the overall training time. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation, which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem. We prove that our method ensures fast convergence of the model compression problem, and the convergence of the SLR is accelerated by using quadratic penalties. Model parameters obtained by SLR during the training phase are much closer to their optimal values as compared to those obtained by other state-of-the-art methods. We evaluate our method on image classification tasks using CIFAR-10 and ImageNet with state-of-the-art MLP-Mixer, Swin Transformer, and VGG-16, ResNet-18, ResNet-50 and ResNet-110, MobileNetV2. We also evaluate object detection and segmentation tasks on COCO, KITTI benchmark, and TuSimple lane detection dataset using a variety of models. Experimental results demonstrate that our SLR-based weight-pruning optimization approach achieves a higher compression rate than state-of-the-art methods under the same accuracy requirement and also can achieve higher accuracy under the same compression rate requirement. Under classification tasks, our SLR approach converges to the desired accuracy $3\times$ faster on both of the datasets. Under object detection and segmentation tasks, SLR also converges $2\times$ faster to the desired accuracy. Further, our SLR achieves high model accuracy even at the hard-pruning stage without retraining, which reduces the traditional three-stage pruning into a two-stage process. Given a limited budget of retraining epochs, our approach quickly recovers the model's accuracy.
Validated respiratory drug deposition predictions from 2D and 3D medical images with statistical shape models and convolutional neural networks
Mar 02, 2023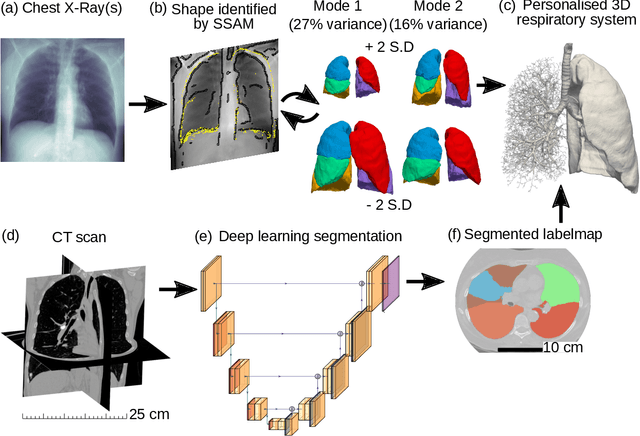
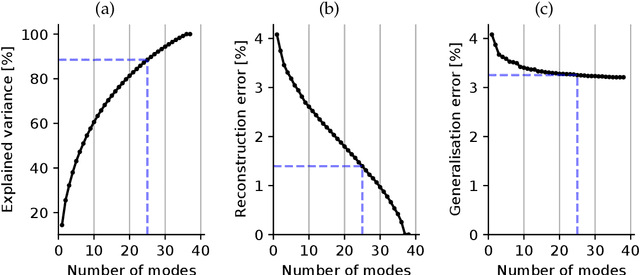
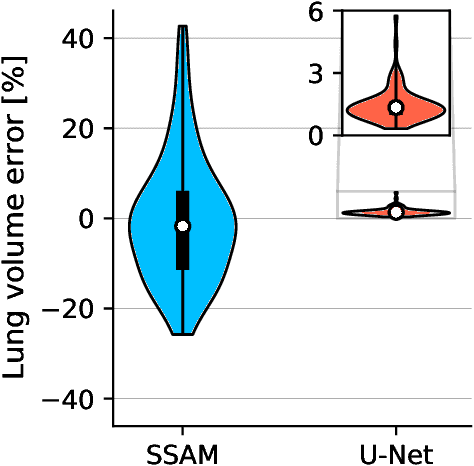
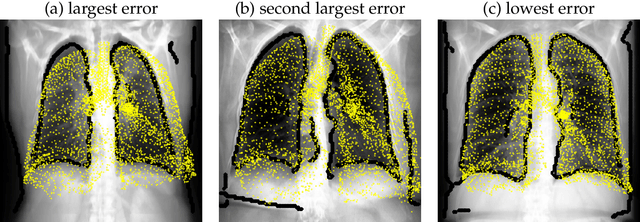
For the one billion sufferers of respiratory disease, managing their disease with inhalers crucially influences their quality of life. Generic treatment plans could be improved with the aid of computational models that account for patient-specific features such as breathing pattern, lung pathology and morphology. Therefore, we aim to develop and validate an automated computational framework for patient-specific deposition modelling. To that end, an image processing approach is proposed that could produce 3D patient respiratory geometries from 2D chest X-rays and 3D CT images. We evaluated the airway and lung morphology produced by our image processing framework, and assessed deposition compared to in vivo data. The 2D-to-3D image processing reproduces airway diameter to 9% median error compared to ground truth segmentations, but is sensitive to outliers of up to 33% due to lung outline noise. Predicted regional deposition gave 5% median error compared to in vivo measurements. The proposed framework is capable of providing patient-specific deposition measurements for varying treatments, to determine which treatment would best satisfy the needs imposed by each patient (such as disease and lung/airway morphology). Integration of patient-specific modelling into clinical practice as an additional decision-making tool could optimise treatment plans and lower the burden of respiratory diseases.
TransUPR: A Transformer-based Uncertain Point Refiner for LiDAR Point Cloud Semantic Segmentation
Feb 20, 2023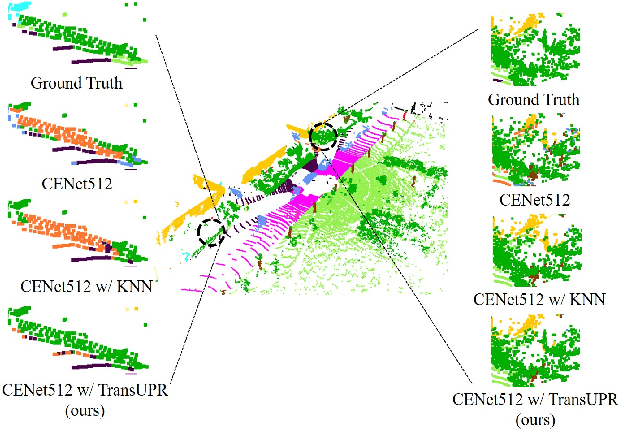
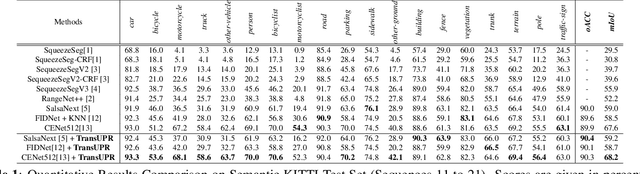
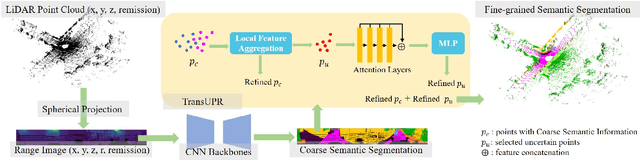

In this work, we target the problem of uncertain points refinement for image-based LiDAR point cloud semantic segmentation (LiDAR PCSS). This problem mainly results from the boundary-blurring problem of convolution neural networks (CNNs) and quantitation loss of spherical projection, which are often hard to avoid for common image-based LiDAR PCSS approaches. We propose a plug-and-play transformer-based uncertain point refiner (TransUPR) to address the problem. Through local feature aggregation, uncertain point localization, and self-attention-based transformer design, TransUPR, integrated into an existing range image-based LiDAR PCSS approach (e.g., CENet), achieves the state-of-the-art performance (68.2% mIoU) on Semantic-KITTI benchmark, which provides a performance improvement of 0.6% on the mIoU.
Uncertainty Driven Bottleneck Attention U-net for OAR Segmentation
Mar 19, 2023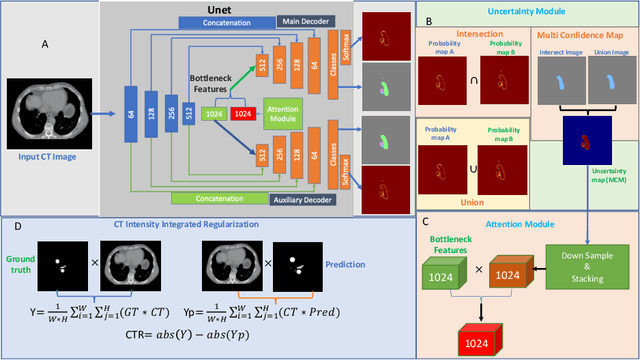
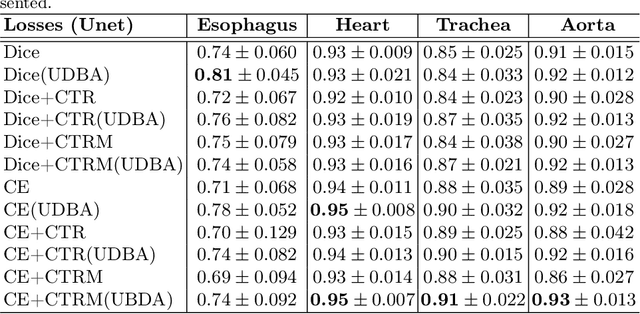

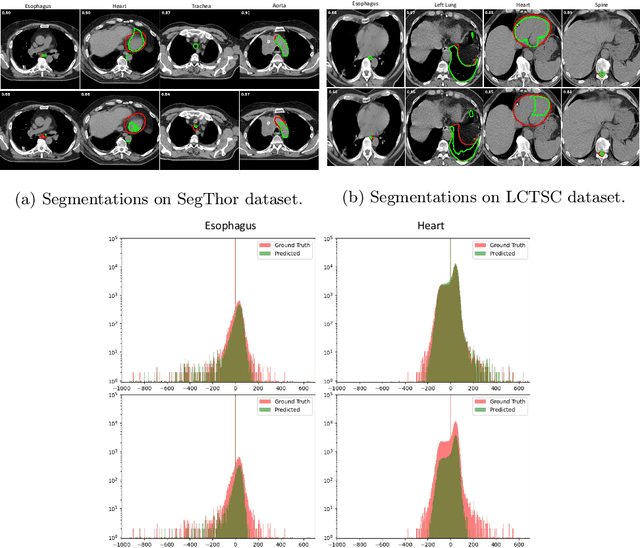
Organ at risk (OAR) segmentation in computed tomography (CT) imagery is a difficult task for automated segmentation methods and can be crucial for downstream radiation treatment planning. U-net has become a de-facto standard for medical image segmentation and is frequently used as a common baseline in medical image segmentation tasks. In this paper, we develop a multiple decoder U-net architecture where a noisy auxiliary decoder is used to generate noisy segmentation. The segmentation from the main branch and the noisy segmentation from the auxiliary branch are used together to estimate the attention. Our contribution is the development of a new attention module which derives the attention from the softmax probabilities of two decoder branches. The union and intersection of two segmentation masks from two branches carry the information where both decoders agree and disagree. The softmax probabilities from regions of agreement and disagreement are the indicators of low and high uncertainty. Thus, the probabilities of those selected regions are used as attention in the bottleneck layer of the encoder and passes only through the main decoder for segmentation. For accurate contour segmentation, we also developed a CT intensity integrated regularization loss. We tested our model on two publicly available OAR challenge datasets, Segthor and LCTSC respectively. We trained 12 models on each dataset with and without the proposed attention model and regularization loss to check the effectiveness of the attention module and the regularization loss. The experiments demonstrate a clear accuracy improvement (2\% to 5\% Dice) on both datasets. Code for the experiments will be made available upon the acceptance for publication.
Topologically faithful image segmentation via induced matching of persistence barcodes
Nov 28, 2022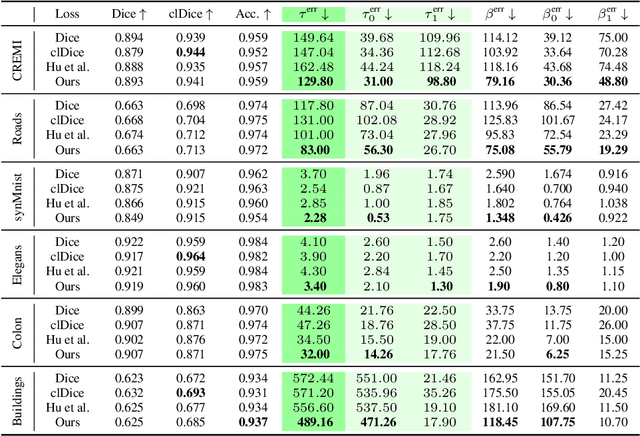


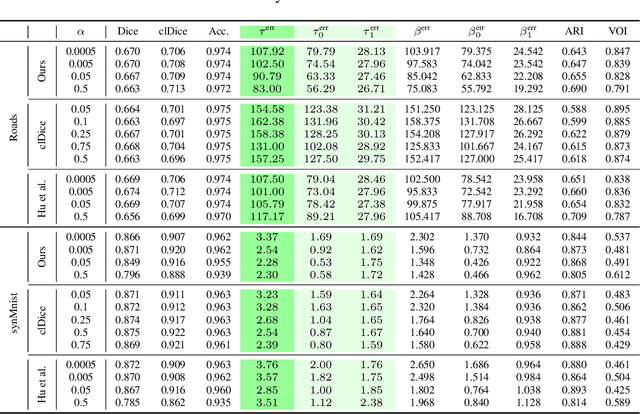
Image segmentation is a largely researched field where neural networks find vast applications in many facets of technology. Some of the most popular approaches to train segmentation networks employ loss functions optimizing pixel-overlap, an objective that is insufficient for many segmentation tasks. In recent years, their limitations fueled a growing interest in topology-aware methods, which aim to recover the correct topology of the segmented structures. However, so far, none of the existing approaches achieve a spatially correct matching between the topological features of ground truth and prediction. In this work, we propose the first topologically and feature-wise accurate metric and loss function for supervised image segmentation, which we term Betti matching. We show how induced matchings guarantee the spatially correct matching between barcodes in a segmentation setting. Furthermore, we propose an efficient algorithm to compute the Betti matching of images. We show that the Betti matching error is an interpretable metric to evaluate the topological correctness of segmentations, which is more sensitive than the well-established Betti number error. Moreover, the differentiability of the Betti matching loss enables its use as a loss function. It improves the topological performance of segmentation networks across six diverse datasets while preserving the volumetric performance. Our code is available in https://github.com/nstucki/Betti-matching.
KGNv2: Separating Scale and Pose Prediction for Keypoint-based 6-DoF Grasp Pose Synthesis on RGB-D input
Mar 09, 2023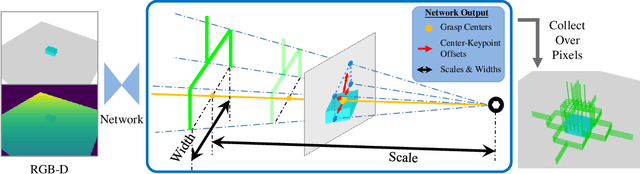
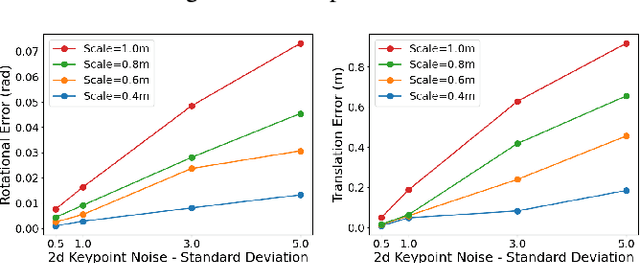
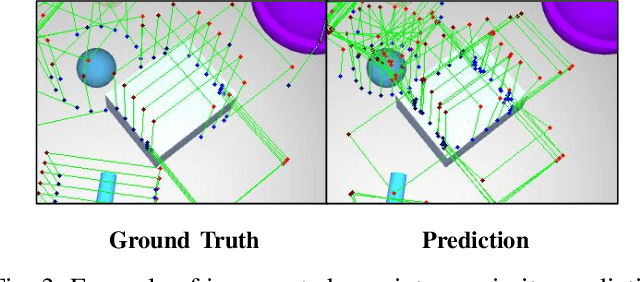

We propose a new 6-DoF grasp pose synthesis approach from 2D/2.5D input based on keypoints. Keypoint-based grasp detector from image input has demonstrated promising results in the previous study, where the additional visual information provided by color images compensates for the noisy depth perception. However, it relies heavily on accurately predicting the location of keypoints in the image space. In this paper, we devise a new grasp generation network that reduces the dependency on precise keypoint estimation. Given an RGB-D input, our network estimates both the grasp pose from keypoint detection as well as scale towards the camera. We further re-design the keypoint output space in order to mitigate the negative impact of keypoint prediction noise to Perspective-n-Point (PnP) algorithm. Experiments show that the proposed method outperforms the baseline by a large margin, validating the efficacy of our approach. Finally, despite trained on simple synthetic objects, our method demonstrate sim-to-real capacity by showing competitive results in real-world robot experiments.
Roadmap on Deep Learning for Microscopy
Mar 07, 2023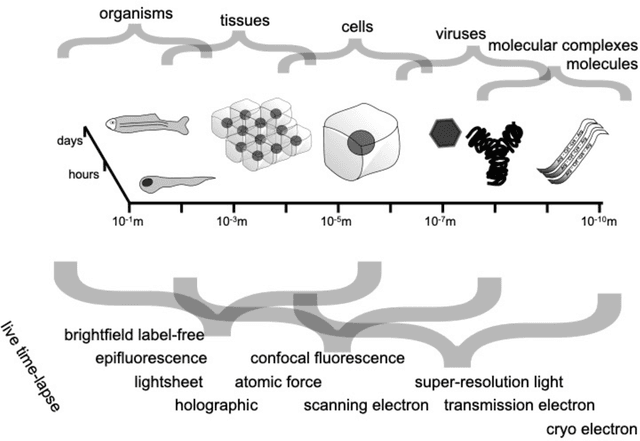
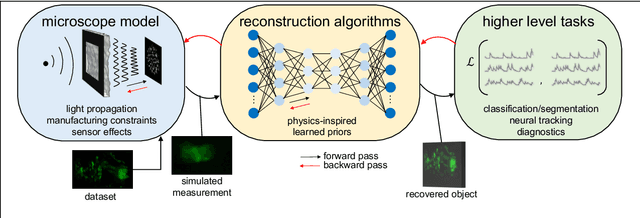

Through digital imaging, microscopy has evolved from primarily being a means for visual observation of life at the micro- and nano-scale, to a quantitative tool with ever-increasing resolution and throughput. Artificial intelligence, deep neural networks, and machine learning are all niche terms describing computational methods that have gained a pivotal role in microscopy-based research over the past decade. This Roadmap is written collectively by prominent researchers and encompasses selected aspects of how machine learning is applied to microscopy image data, with the aim of gaining scientific knowledge by improved image quality, automated detection, segmentation, classification and tracking of objects, and efficient merging of information from multiple imaging modalities. We aim to give the reader an overview of the key developments and an understanding of possibilities and limitations of machine learning for microscopy. It will be of interest to a wide cross-disciplinary audience in the physical sciences and life sciences.
Multi Modal Facial Expression Recognition with Transformer-Based Fusion Networks and Dynamic Sampling
Mar 19, 2023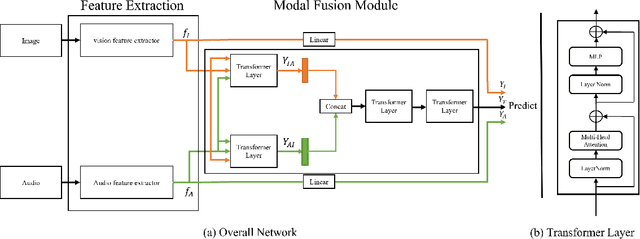
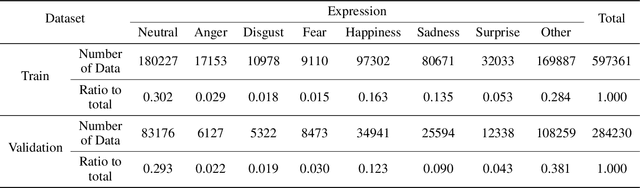
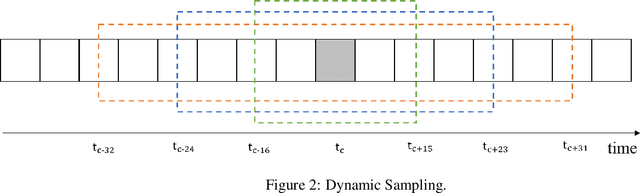
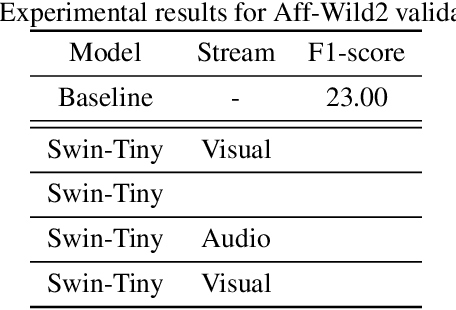
Facial expression recognition is an essential task for various applications, including emotion detection, mental health analysis, and human-machine interactions. In this paper, we propose a multi-modal facial expression recognition method that exploits audio information along with facial images to provide a crucial clue to differentiate some ambiguous facial expressions. Specifically, we introduce a Modal Fusion Module (MFM) to fuse audio-visual information, where image and audio features are extracted from Swin Transformer. Additionally, we tackle the imbalance problem in the dataset by employing dynamic data resampling. Our model has been evaluated in the Affective Behavior in-the-wild (ABAW) challenge of CVPR 2023.