 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$μ_0$: A Scalable 3D Interaction-Trace World Model
Jun 11, 2026World models that capture how actions induce physical change enable scalable robot learning without reliance on embodiment-specific action labels. Pixel-space video models provide broad visual priors but expend model capacity on dense appearance reconstruction, while direct action models require embodiment-specific labels that hinder scalability. We present $μ_0$, a scalable world model based on 3D traces. Rather than predicting dense pixels or directly modeling actions, $μ_0$ forecasts smooth 3D trajectories for salient interaction points such as objects, tools, hands, and contact regions, yielding a compact, embodiment-agnostic motion interface. To enable training from diverse video sources, our TraceExtract system automatically extracts 3D supervision by selecting keypoints, constructing globally aligned traces, and associating motion segments with hierarchical language captions. This TraceExtract supervision pretrains $μ_0$ by combining a pretrained vision-language backbone with a modular trace expert, which represents each query via B-spline control points and predicts future traces. Experiments show that $μ_0$ outperforms baselines in both 2D and 3D trace prediction, including trace prediction models and tokenized VLM methods. Because $μ_0$ is frozen and reusable, it can be paired with action experts for downstream robot embodiments. Despite action-free pretraining, the resulting trace-conditioned policies achieve performance competitive with VLA models pretrained with action supervision, such as $π_0$. These results establish 3D traces as a scalable and transferable representation for cross-embodiment manipulation.
Generative Omnimatte: Learning to Decompose Video into Layers
Nov 25, 2024



Given a video and a set of input object masks, an omnimatte method aims to decompose the video into semantically meaningful layers containing individual objects along with their associated effects, such as shadows and reflections. Existing omnimatte methods assume a static background or accurate pose and depth estimation and produce poor decompositions when these assumptions are violated. Furthermore, due to the lack of generative prior on natural videos, existing methods cannot complete dynamic occluded regions. We present a novel generative layered video decomposition framework to address the omnimatte problem. Our method does not assume a stationary scene or require camera pose or depth information and produces clean, complete layers, including convincing completions of occluded dynamic regions. Our core idea is to train a video diffusion model to identify and remove scene effects caused by a specific object. We show that this model can be finetuned from an existing video inpainting model with a small, carefully curated dataset, and demonstrate high-quality decompositions and editing results for a wide range of casually captured videos containing soft shadows, glossy reflections, splashing water, and more.
VividDream: Generating 3D Scene with Ambient Dynamics
May 30, 2024We introduce VividDream, a method for generating explorable 4D scenes with ambient dynamics from a single input image or text prompt. VividDream first expands an input image into a static 3D point cloud through iterative inpainting and geometry merging. An ensemble of animated videos is then generated using video diffusion models with quality refinement techniques and conditioned on renderings of the static 3D scene from the sampled camera trajectories. We then optimize a canonical 4D scene representation using an animated video ensemble, with per-video motion embeddings and visibility masks to mitigate inconsistencies. The resulting 4D scene enables free-view exploration of a 3D scene with plausible ambient scene dynamics. Experiments demonstrate that VividDream can provide human viewers with compelling 4D experiences generated based on diverse real images and text prompts.
Fast View Synthesis of Casual Videos
Dec 04, 2023Novel view synthesis from an in-the-wild video is difficult due to challenges like scene dynamics and lack of parallax. While existing methods have shown promising results with implicit neural radiance fields, they are slow to train and render. This paper revisits explicit video representations to synthesize high-quality novel views from a monocular video efficiently. We treat static and dynamic video content separately. Specifically, we build a global static scene model using an extended plane-based scene representation to synthesize temporally coherent novel video. Our plane-based scene representation is augmented with spherical harmonics and displacement maps to capture view-dependent effects and model non-planar complex surface geometry. We opt to represent the dynamic content as per-frame point clouds for efficiency. While such representations are inconsistency-prone, minor temporal inconsistencies are perceptually masked due to motion. We develop a method to quickly estimate such a hybrid video representation and render novel views in real time. Our experiments show that our method can render high-quality novel views from an in-the-wild video with comparable quality to state-of-the-art methods while being 100x faster in training and enabling real-time rendering.
Text-driven Visual Synthesis with Latent Diffusion Prior
Feb 16, 2023



There has been tremendous progress in large-scale text-to-image synthesis driven by diffusion models enabling versatile downstream applications such as 3D object synthesis from texts, image editing, and customized generation. We present a generic approach using latent diffusion models as powerful image priors for various visual synthesis tasks. Existing methods that utilize such priors fail to use these models' full capabilities. To improve this, our core ideas are 1) a feature matching loss between features from different layers of the decoder to provide detailed guidance and 2) a KL divergence loss to regularize the predicted latent features and stabilize the training. We demonstrate the efficacy of our approach on three different applications, text-to-3D, StyleGAN adaptation, and layered image editing. Extensive results show our method compares favorably against baselines.
Shape-aware Text-driven Layered Video Editing
Jan 30, 2023



Temporal consistency is essential for video editing applications. Existing work on layered representation of videos allows propagating edits consistently to each frame. These methods, however, can only edit object appearance rather than object shape changes due to the limitation of using a fixed UV mapping field for texture atlas. We present a shape-aware, text-driven video editing method to tackle this challenge. To handle shape changes in video editing, we first propagate the deformation field between the input and edited keyframe to all frames. We then leverage a pre-trained text-conditioned diffusion model as guidance for refining shape distortion and completing unseen regions. The experimental results demonstrate that our method can achieve shape-aware consistent video editing and compare favorably with the state-of-the-art.
Globally Consistent Video Depth and Pose Estimation with Efficient Test-Time Training
Aug 04, 2022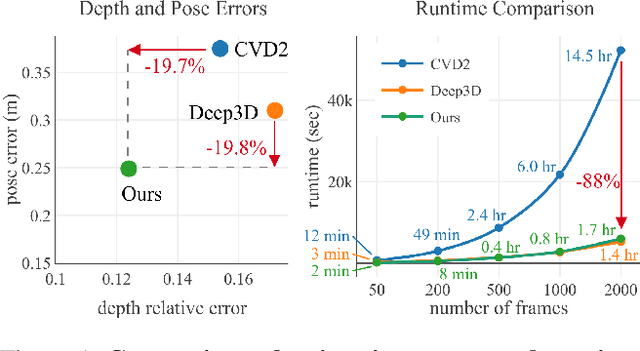
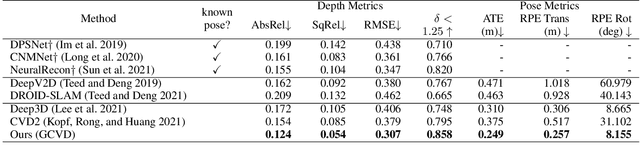

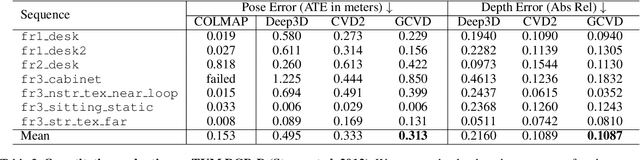
Dense depth and pose estimation is a vital prerequisite for various video applications. Traditional solutions suffer from the robustness of sparse feature tracking and insufficient camera baselines in videos. Therefore, recent methods utilize learning-based optical flow and depth prior to estimate dense depth. However, previous works require heavy computation time or yield sub-optimal depth results. We present GCVD, a globally consistent method for learning-based video structure from motion (SfM) in this paper. GCVD integrates a compact pose graph into the CNN-based optimization to achieve globally consistent estimation from an effective keyframe selection mechanism. It can improve the robustness of learning-based methods with flow-guided keyframes and well-established depth prior. Experimental results show that GCVD outperforms the state-of-the-art methods on both depth and pose estimation. Besides, the runtime experiments reveal that it provides strong efficiency in both short- and long-term videos with global consistency provided.
Part-Aware Measurement for Robust Multi-View Multi-Human 3D Pose Estimation and Tracking
Jun 22, 2021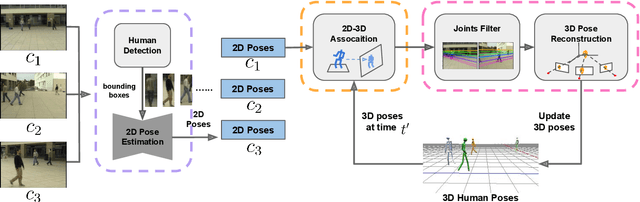
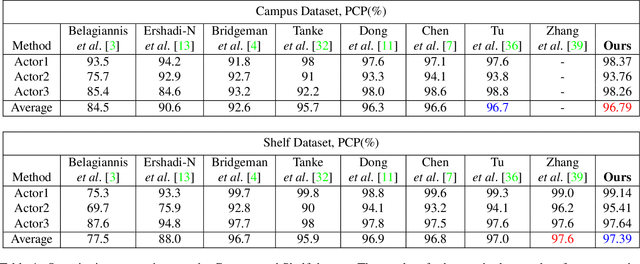
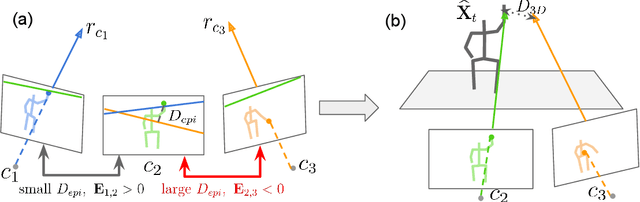
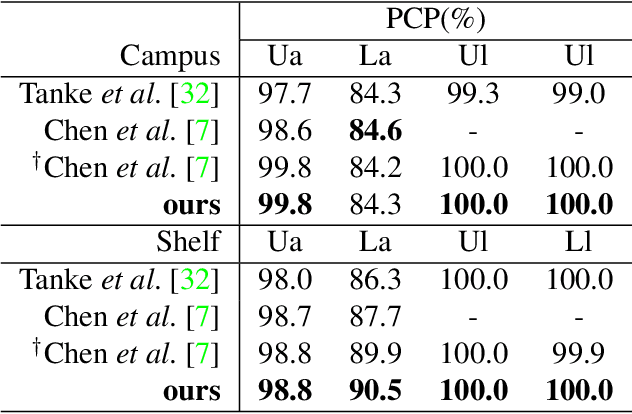
This paper introduces an approach for multi-human 3D pose estimation and tracking based on calibrated multi-view. The main challenge lies in finding the cross-view and temporal correspondences correctly even when several human pose estimations are noisy. Compare to previous solutions that construct 3D poses from multiple views, our approach takes advantage of temporal consistency to match the 2D poses estimated with previously constructed 3D skeletons in every view. Therefore cross-view and temporal associations are accomplished simultaneously. Since the performance suffers from mistaken association and noisy predictions, we design two strategies for aiming better correspondences and 3D reconstruction. Specifically, we propose a part-aware measurement for 2D-3D association and a filter that can cope with 2D outliers during reconstruction. Our approach is efficient and effective comparing to state-of-the-art methods; it achieves competitive results on two benchmarks: 96.8% on Campus and 97.4% on Shelf. Moreover, we extends the length of Campus evaluation frames to be more challenging and our proposal also reach well-performed result.