 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoGS: Training-Free Gaussian Splat Simplification
Mar 17, 20263D Gaussian Splat (3DGS) enables high-fidelity, real-time novel view synthesis by representing scenes with large sets of anisotropic primitives, but often requires millions of Splats, incurring significant storage and transmission costs. Most existing compression methods rely on GPU-intensive post-training optimization with calibrated images, limiting practical deployment. We introduce NanoGS, a training-free and lightweight framework for Gaussian Splat simplification. Instead of relying on image-based rendering supervision, NanoGS formulates simplification as local pairwise merging over a sparse spatial graph. The method approximates a pair of Gaussians with a single primitive using mass preserved moment matching and evaluates merge quality through a principled merge cost between the original mixture and its approximation. By restricting merge candidates to local neighborhoods and selecting compatible pairs efficiently, NanoGS produces compact Gaussian representations while preserving scene structure and appearance. NanoGS operates directly on existing Gaussian Splat models, runs efficiently on CPU, and preserves the standard 3DGS parameterization, enabling seamless integration with existing rendering pipelines. Experiments demonstrate that NanoGS substantially reduces primitive count while maintaining high rendering fidelity, providing an efficient and practical solution for Gaussian Splat simplification. Our project website is available at https://saliteta.github.io/NanoGS/.
LowDiff: Efficient Diffusion Sampling with Low-Resolution Condition
Sep 18, 2025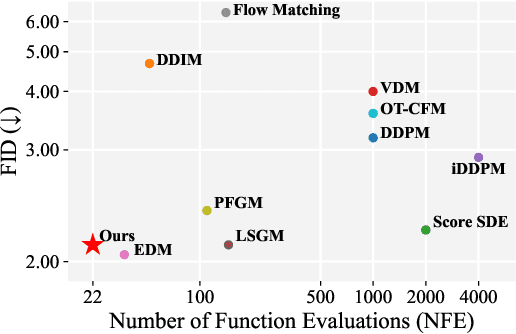
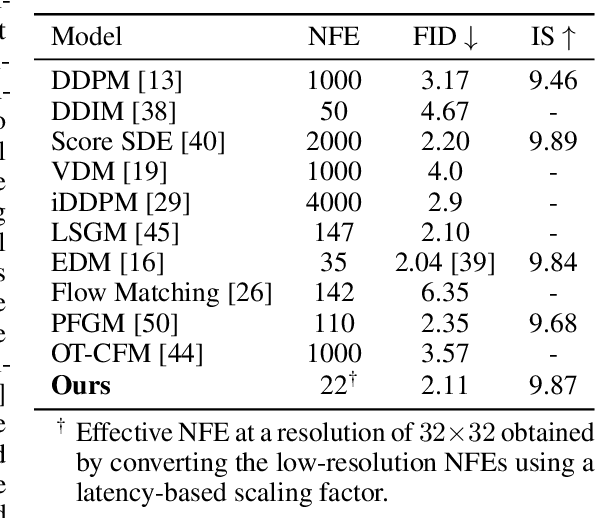
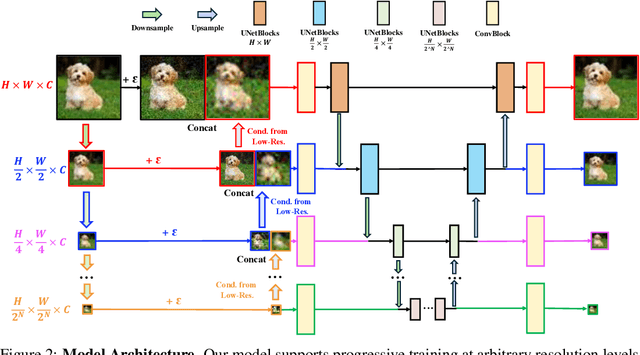
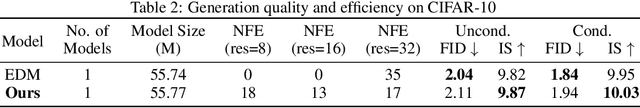
Diffusion models have achieved remarkable success in image generation but their practical application is often hindered by the slow sampling speed. Prior efforts of improving efficiency primarily focus on compressing models or reducing the total number of denoising steps, largely neglecting the possibility to leverage multiple input resolutions in the generation process. In this work, we propose LowDiff, a novel and efficient diffusion framework based on a cascaded approach by generating increasingly higher resolution outputs. Besides, LowDiff employs a unified model to progressively refine images from low resolution to the desired resolution. With the proposed architecture design and generation techniques, we achieve comparable or even superior performance with much fewer high-resolution sampling steps. LowDiff is applicable to diffusion models in both pixel space and latent space. Extensive experiments on both conditional and unconditional generation tasks across CIFAR-10, FFHQ and ImageNet demonstrate the effectiveness and generality of our method. Results show over 50% throughput improvement across all datasets and settings while maintaining comparable or better quality. On unconditional CIFAR-10, LowDiff achieves an FID of 2.11 and IS of 9.87, while on conditional CIFAR-10, an FID of 1.94 and IS of 10.03. On FFHQ 64x64, LowDiff achieves an FID of 2.43, and on ImageNet 256x256, LowDiff built on LightningDiT-B/1 produces high-quality samples with a FID of 4.00 and an IS of 195.06, together with substantial efficiency gains.
IDU: Incremental Dynamic Update of Existing 3D Virtual Environments with New Imagery Data
Aug 25, 2025For simulation and training purposes, military organizations have made substantial investments in developing high-resolution 3D virtual environments through extensive imaging and 3D scanning. However, the dynamic nature of battlefield conditions-where objects may appear or vanish over time-makes frequent full-scale updates both time-consuming and costly. In response, we introduce the Incremental Dynamic Update (IDU) pipeline, which efficiently updates existing 3D reconstructions, such as 3D Gaussian Splatting (3DGS), with only a small set of newly acquired images. Our approach starts with camera pose estimation to align new images with the existing 3D model, followed by change detection to pinpoint modifications in the scene. A 3D generative AI model is then used to create high-quality 3D assets of the new elements, which are seamlessly integrated into the existing 3D model. The IDU pipeline incorporates human guidance to ensure high accuracy in object identification and placement, with each update focusing on a single new object at a time. Experimental results confirm that our proposed IDU pipeline significantly reduces update time and labor, offering a cost-effective and targeted solution for maintaining up-to-date 3D models in rapidly evolving military scenarios.
Splat Feature Solver
Aug 17, 2025



Feature lifting has emerged as a crucial component in 3D scene understanding, enabling the attachment of rich image feature descriptors (e.g., DINO, CLIP) onto splat-based 3D representations. The core challenge lies in optimally assigning rich general attributes to 3D primitives while addressing the inconsistency issues from multi-view images. We present a unified, kernel- and feature-agnostic formulation of the feature lifting problem as a sparse linear inverse problem, which can be solved efficiently in closed form. Our approach admits a provable upper bound on the global optimal error under convex losses for delivering high quality lifted features. To address inconsistencies and noise in multi-view observations, we introduce two complementary regularization strategies to stabilize the solution and enhance semantic fidelity. Tikhonov Guidance enforces numerical stability through soft diagonal dominance, while Post-Lifting Aggregation filters noisy inputs via feature clustering. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on open-vocabulary 3D segmentation benchmarks, outperforming training-based, grouping-based, and heuristic-forward baselines while producing the lifted features in minutes. Code is available at \href{https://github.com/saliteta/splat-distiller.git}{\textbf{github}}. We also have a \href{https://splat-distiller.pages.dev/}
Deformable Beta Splatting
Jan 27, 2025



3D Gaussian Splatting (3DGS) has advanced radiance field reconstruction by enabling real-time rendering. However, its reliance on Gaussian kernels for geometry and low-order Spherical Harmonics (SH) for color encoding limits its ability to capture complex geometries and diverse colors. We introduce Deformable Beta Splatting (DBS), a deformable and compact approach that enhances both geometry and color representation. DBS replaces Gaussian kernels with deformable Beta Kernels, which offer bounded support and adaptive frequency control to capture fine geometric details with higher fidelity while achieving better memory efficiency. In addition, we extended the Beta Kernel to color encoding, which facilitates improved representation of diffuse and specular components, yielding superior results compared to SH-based methods. Furthermore, Unlike prior densification techniques that depend on Gaussian properties, we mathematically prove that adjusting regularized opacity alone ensures distribution-preserved Markov chain Monte Carlo (MCMC), independent of the splatting kernel type. Experimental results demonstrate that DBS achieves state-of-the-art visual quality while utilizing only 45% of the parameters and rendering 1.5x faster than 3DGS-based methods. Notably, for the first time, splatting-based methods outperform state-of-the-art Neural Radiance Fields, highlighting the superior performance and efficiency of DBS for real-time radiance field rendering.
SplatMAP: Online Dense Monocular SLAM with 3D Gaussian Splatting
Jan 14, 2025



Achieving high-fidelity 3D reconstruction from monocular video remains challenging due to the inherent limitations of traditional methods like Structure-from-Motion (SfM) and monocular SLAM in accurately capturing scene details. While differentiable rendering techniques such as Neural Radiance Fields (NeRF) address some of these challenges, their high computational costs make them unsuitable for real-time applications. Additionally, existing 3D Gaussian Splatting (3DGS) methods often focus on photometric consistency, neglecting geometric accuracy and failing to exploit SLAM's dynamic depth and pose updates for scene refinement. We propose a framework integrating dense SLAM with 3DGS for real-time, high-fidelity dense reconstruction. Our approach introduces SLAM-Informed Adaptive Densification, which dynamically updates and densifies the Gaussian model by leveraging dense point clouds from SLAM. Additionally, we incorporate Geometry-Guided Optimization, which combines edge-aware geometric constraints and photometric consistency to jointly optimize the appearance and geometry of the 3DGS scene representation, enabling detailed and accurate SLAM mapping reconstruction. Experiments on the Replica and TUM-RGBD datasets demonstrate the effectiveness of our approach, achieving state-of-the-art results among monocular systems. Specifically, our method achieves a PSNR of 36.864, SSIM of 0.985, and LPIPS of 0.040 on Replica, representing improvements of 10.7%, 6.4%, and 49.4%, respectively, over the previous SOTA. On TUM-RGBD, our method outperforms the closest baseline by 10.2%, 6.6%, and 34.7% in the same metrics. These results highlight the potential of our framework in bridging the gap between photometric and geometric dense 3D scene representations, paving the way for practical and efficient monocular dense reconstruction.
Open-Vocabulary High-Resolution 3D (OVHR3D) Data Segmentation and Annotation Framework
Dec 09, 2024In the domain of the U.S. Army modeling and simulation, the availability of high quality annotated 3D data is pivotal to creating virtual environments for training and simulations. Traditional methodologies for 3D semantic and instance segmentation, such as KpConv, RandLA, Mask3D, etc., are designed to train on extensive labeled datasets to obtain satisfactory performance in practical tasks. This requirement presents a significant challenge, given the inherent scarcity of manually annotated 3D datasets, particularly for the military use cases. Recognizing this gap, our previous research leverages the One World Terrain data repository manually annotated databases, as showcased at IITSEC 2019 and 2021, to enrich the training dataset for deep learning models. However, collecting and annotating large scale 3D data for specific tasks remains costly and inefficient. To this end, the objective of this research is to design and develop a comprehensive and efficient framework for 3D segmentation tasks to assist in 3D data annotation. This framework integrates Grounding DINO and Segment anything Model, augmented by an enhancement in 2D image rendering via 3D mesh. Furthermore, the authors have also developed a user friendly interface that facilitates the 3D annotation process, offering intuitive visualization of rendered images and the 3D point cloud.
AtomGS: Atomizing Gaussian Splatting for High-Fidelity Radiance Field
May 22, 20243D Gaussian Splatting (3DGS) has recently advanced radiance field reconstruction by offering superior capabilities for novel view synthesis and real-time rendering speed. However, its strategy of blending optimization and adaptive density control might lead to sub-optimal results; it can sometimes yield noisy geometry and blurry artifacts due to prioritizing optimizing large Gaussians at the cost of adequately densifying smaller ones. To address this, we introduce AtomGS, consisting of Atomized Proliferation and Geometry-Guided Optimization. The Atomized Proliferation constrains ellipsoid Gaussians of various sizes into more uniform-sized Atom Gaussians. The strategy enhances the representation of areas with fine features by placing greater emphasis on densification in accordance with scene details. In addition, we proposed a Geometry-Guided Optimization approach that incorporates an Edge-Aware Normal Loss. This optimization method effectively smooths flat surfaces while preserving intricate details. Our evaluation shows that AtomGS outperforms existing state-of-the-art methods in rendering quality. Additionally, it achieves competitive accuracy in geometry reconstruction and offers a significant improvement in training speed over other SDF-based methods. More interactive demos can be found in our website (https://rongliu-leo.github.io/AtomGS/).
TokenMotion: Motion-Guided Vision Transformer for Video Camouflaged Object Detection Via Learnable Token Selection
Nov 05, 2023



The area of Video Camouflaged Object Detection (VCOD) presents unique challenges in the field of computer vision due to texture similarities between target objects and their surroundings, as well as irregular motion patterns caused by both objects and camera movement. In this paper, we introduce TokenMotion (TMNet), which employs a transformer-based model to enhance VCOD by extracting motion-guided features using a learnable token selection. Evaluated on the challenging MoCA-Mask dataset, TMNet achieves state-of-the-art performance in VCOD. It outperforms the existing state-of-the-art method by a 12.8% improvement in weighted F-measure, an 8.4% enhancement in S-measure, and a 10.7% boost in mean IoU. The results demonstrate the benefits of utilizing motion-guided features via learnable token selection within a transformer-based framework to tackle the intricate task of VCOD.
TransUPR: A Transformer-based Uncertain Point Refiner for LiDAR Point Cloud Semantic Segmentation
Feb 20, 2023



In this work, we target the problem of uncertain points refinement for image-based LiDAR point cloud semantic segmentation (LiDAR PCSS). This problem mainly results from the boundary-blurring problem of convolution neural networks (CNNs) and quantitation loss of spherical projection, which are often hard to avoid for common image-based LiDAR PCSS approaches. We propose a plug-and-play transformer-based uncertain point refiner (TransUPR) to address the problem. Through local feature aggregation, uncertain point localization, and self-attention-based transformer design, TransUPR, integrated into an existing range image-based LiDAR PCSS approach (e.g., CENet), achieves the state-of-the-art performance (68.2% mIoU) on Semantic-KITTI benchmark, which provides a performance improvement of 0.6% on the mIoU.