 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle View 3d Reconstruction
Single-view 3D reconstruction is the process of estimating the 3D shape of an object from a single 2D image.
Papers and Code
ViewMorpher3D: A 3D-aware Diffusion Framework for Multi-Camera Novel View Synthesis in Autonomous Driving
Jan 13, 2026Autonomous driving systems rely heavily on multi-view images to ensure accurate perception and robust decision-making. To effectively develop and evaluate perception stacks and planning algorithms, realistic closed-loop simulators are indispensable. While 3D reconstruction techniques such as Gaussian Splatting offer promising avenues for simulator construction, the rendered novel views often exhibit artifacts, particularly in extrapolated perspectives or when available observations are sparse. We introduce ViewMorpher3D, a multi-view image enhancement framework based on image diffusion models, designed to elevate photorealism and multi-view coherence in driving scenes. Unlike single-view approaches, ViewMorpher3D jointly processes a set of rendered views conditioned on camera poses, 3D geometric priors, and temporally adjacent or spatially overlapping reference views. This enables the model to infer missing details, suppress rendering artifacts, and enforce cross-view consistency. Our framework accommodates variable numbers of cameras and flexible reference/target view configurations, making it adaptable to diverse sensor setups. Experiments on real-world driving datasets demonstrate substantial improvements in image quality metrics, effectively reducing artifacts while preserving geometric fidelity.
Segmentation-Driven Monocular Shape from Polarization based on Physical Model
Jan 08, 2026Monocular shape-from-polarization (SfP) leverages the intrinsic relationship between light polarization properties and surface geometry to recover surface normals from single-view polarized images, providing a compact and robust approach for three-dimensional (3D) reconstruction. Despite its potential, existing monocular SfP methods suffer from azimuth angle ambiguity, an inherent limitation of polarization analysis, that severely compromises reconstruction accuracy and stability. This paper introduces a novel segmentation-driven monocular SfP (SMSfP) framework that reformulates global shape recovery into a set of local reconstructions over adaptively segmented convex sub-regions. Specifically, a polarization-aided adaptive region growing (PARG) segmentation strategy is proposed to decompose the global convexity assumption into locally convex regions, effectively suppressing azimuth ambiguities and preserving surface continuity. Furthermore, a multi-scale fusion convexity prior (MFCP) constraint is developed to ensure local surface consistency and enhance the recovery of fine textural and structural details. Extensive experiments on both synthetic and real-world datasets validate the proposed approach, showing significant improvements in disambiguation accuracy and geometric fidelity compared with existing physics-based monocular SfP techniques.
GeoSurDepth: Spatial Geometry-Consistent Self-Supervised Depth Estimation for Surround-View Cameras
Jan 09, 2026Accurate surround-view depth estimation provides a competitive alternative to laser-based sensors and is essential for 3D scene understanding in autonomous driving. While prior studies have proposed various approaches that primarily focus on enforcing cross-view constraints at the photometric level, few explicitly exploit the rich geometric structure inherent in both monocular and surround-view setting. In this work, we propose GeoSurDepth, a framework that leverages geometry consistency as the primary cue for surround-view depth estimation. Concretely, we utilize foundation models as a pseudo geometry prior and feature representation enhancement tool to guide the network to maintain surface normal consistency in spatial 3D space and regularize object- and texture-consistent depth estimation in 2D. In addition, we introduce a novel view synthesis pipeline where 2D-3D lifting is achieved with dense depth reconstructed via spatial warping, encouraging additional photometric supervision across temporal, spatial, and spatial-temporal contexts, and compensating for the limitations of single-view image reconstruction. Finally, a newly-proposed adaptive joint motion learning strategy enables the network to adaptively emphasize informative spatial geometry cues for improved motion reasoning. Extensive experiments on DDAD and nuScenes demonstrate that GeoSurDepth achieves state-of-the-art performance, validating the effectiveness of our approach. Our framework highlights the importance of exploiting geometry coherence and consistency for robust self-supervised multi-view depth estimation.
Mon3tr: Monocular 3D Telepresence with Pre-built Gaussian Avatars as Amortization
Jan 12, 2026Immersive telepresence aims to transform human interaction in AR/VR applications by enabling lifelike full-body holographic representations for enhanced remote collaboration. However, existing systems rely on hardware-intensive multi-camera setups and demand high bandwidth for volumetric streaming, limiting their real-time performance on mobile devices. To overcome these challenges, we propose Mon3tr, a novel Monocular 3D telepresence framework that integrates 3D Gaussian splatting (3DGS) based parametric human modeling into telepresence for the first time. Mon3tr adopts an amortized computation strategy, dividing the process into a one-time offline multi-view reconstruction phase to build a user-specific avatar and a monocular online inference phase during live telepresence sessions. A single monocular RGB camera is used to capture body motions and facial expressions in real time to drive the 3DGS-based parametric human model, significantly reducing system complexity and cost. The extracted motion and appearance features are transmitted at < 0.2 Mbps over WebRTC's data channel, allowing robust adaptation to network fluctuations. On the receiver side, e.g., Meta Quest 3, we develop a lightweight 3DGS attribute deformation network to dynamically generate corrective 3DGS attribute adjustments on the pre-built avatar, synthesizing photorealistic motion and appearance at ~ 60 FPS. Extensive experiments demonstrate the state-of-the-art performance of our method, achieving a PSNR of > 28 dB for novel poses, an end-to-end latency of ~ 80 ms, and > 1000x bandwidth reduction compared to point-cloud streaming, while supporting real-time operation from monocular inputs across diverse scenarios. Our demos can be found at https://mon3tr3d.github.io.
A Modular Framework for Single-View 3D Reconstruction of Indoor Environments
Dec 17, 2025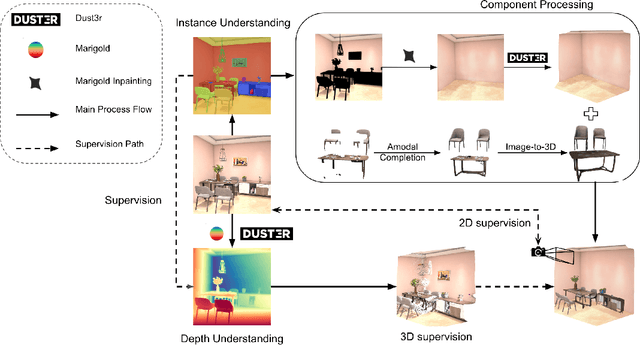

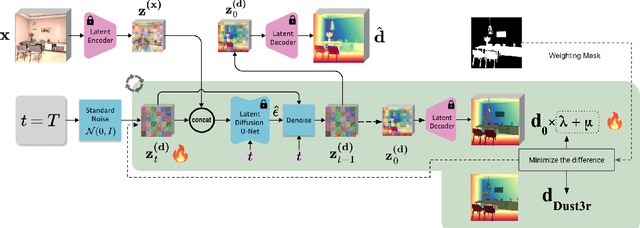
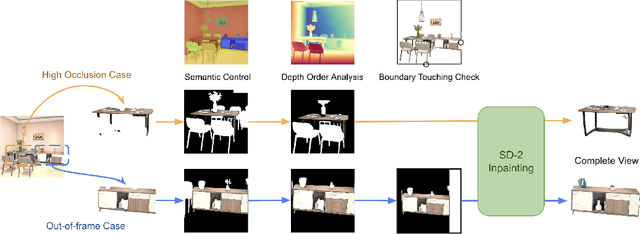
We propose a modular framework for single-view indoor scene 3D reconstruction, where several core modules are powered by diffusion techniques. Traditional approaches for this task often struggle with the complex instance shapes and occlusions inherent in indoor environments. They frequently overshoot by attempting to predict 3D shapes directly from incomplete 2D images, which results in limited reconstruction quality. We aim to overcome this limitation by splitting the process into two steps: first, we employ diffusion-based techniques to predict the complete views of the room background and occluded indoor instances, then transform them into 3D. Our modular framework makes contributions to this field through the following components: an amodal completion module for restoring the full view of occluded instances, an inpainting model specifically trained to predict room layouts, a hybrid depth estimation technique that balances overall geometric accuracy with fine detail expressiveness, and a view-space alignment method that exploits both 2D and 3D cues to ensure precise placement of instances within the scene. This approach effectively reconstructs both foreground instances and the room background from a single image. Extensive experiments on the 3D-Front dataset demonstrate that our method outperforms current state-of-the-art (SOTA) approaches in terms of both visual quality and reconstruction accuracy. The framework holds promising potential for applications in interior design, real estate, and augmented reality.
Edit3r: Instant 3D Scene Editing from Sparse Unposed Images
Dec 31, 2025We present Edit3r, a feed-forward framework that reconstructs and edits 3D scenes in a single pass from unposed, view-inconsistent, instruction-edited images. Unlike prior methods requiring per-scene optimization, Edit3r directly predicts instruction-aligned 3D edits, enabling fast and photorealistic rendering without optimization or pose estimation. A key challenge in training such a model lies in the absence of multi-view consistent edited images for supervision. We address this with (i) a SAM2-based recoloring strategy that generates reliable, cross-view-consistent supervision, and (ii) an asymmetric input strategy that pairs a recolored reference view with raw auxiliary views, encouraging the network to fuse and align disparate observations. At inference, our model effectively handles images edited by 2D methods such as InstructPix2Pix, despite not being exposed to such edits during training. For large-scale quantitative evaluation, we introduce DL3DV-Edit-Bench, a benchmark built on the DL3DV test split, featuring 20 diverse scenes, 4 edit types and 100 edits in total. Comprehensive quantitative and qualitative results show that Edit3r achieves superior semantic alignment and enhanced 3D consistency compared to recent baselines, while operating at significantly higher inference speed, making it promising for real-time 3D editing applications.
OSCAR: Open-Set CAD Retrieval from a Language Prompt and a Single Image
Jan 12, 20266D object pose estimation plays a crucial role in scene understanding for applications such as robotics and augmented reality. To support the needs of ever-changing object sets in such context, modern zero-shot object pose estimators were developed to not require object-specific training but only rely on CAD models. Such models are hard to obtain once deployed, and a continuously changing and growing set of objects makes it harder to reliably identify the instance model of interest. To address this challenge, we introduce an Open-Set CAD Retrieval from a Language Prompt and a Single Image (OSCAR), a novel training-free method that retrieves a matching object model from an unlabeled 3D object database. During onboarding, OSCAR generates multi-view renderings of database models and annotates them with descriptive captions using an image captioning model. At inference, GroundedSAM detects the queried object in the input image, and multi-modal embeddings are computed for both the Region-of-Interest and the database captions. OSCAR employs a two-stage retrieval: text-based filtering using CLIP identifies candidate models, followed by image-based refinement using DINOv2 to select the most visually similar object. In our experiments we demonstrate that OSCAR outperforms all state-of-the-art methods on the cross-domain 3D model retrieval benchmark MI3DOR. Furthermore, we demonstrate OSCAR's direct applicability in automating object model sourcing for 6D object pose estimation. We propose using the most similar object model for pose estimation if the exact instance is not available and show that OSCAR achieves an average precision of 90.48\% during object retrieval on the YCB-V object dataset. Moreover, we demonstrate that the most similar object model can be utilized for pose estimation using Megapose achieving better results than a reconstruction-based approach.
IDESplat: Iterative Depth Probability Estimation for Generalizable 3D Gaussian Splatting
Jan 07, 2026Generalizable 3D Gaussian Splatting aims to directly predict Gaussian parameters using a feed-forward network for scene reconstruction. Among these parameters, Gaussian means are particularly difficult to predict, so depth is usually estimated first and then unprojected to obtain the Gaussian sphere centers. Existing methods typically rely solely on a single warp to estimate depth probability, which hinders their ability to fully leverage cross-view geometric cues, resulting in unstable and coarse depth maps. To address this limitation, we propose IDESplat, which iteratively applies warp operations to boost depth probability estimation for accurate Gaussian mean prediction. First, to eliminate the inherent instability of a single warp, we introduce a Depth Probability Boosting Unit (DPBU) that integrates epipolar attention maps produced by cascading warp operations in a multiplicative manner. Next, we construct an iterative depth estimation process by stacking multiple DPBUs, progressively identifying potential depth candidates with high likelihood. As IDESplat iteratively boosts depth probability estimates and updates the depth candidates, the depth map is gradually refined, resulting in accurate Gaussian means. We conduct experiments on RealEstate10K, ACID, and DL3DV. IDESplat achieves outstanding reconstruction quality and state-of-the-art performance with real-time efficiency. On RE10K, it outperforms DepthSplat by 0.33 dB in PSNR, using only 10.7% of the parameters and 70% of the memory. Additionally, our IDESplat improves PSNR by 2.95 dB over DepthSplat on the DTU dataset in cross-dataset experiments, demonstrating its strong generalization ability.
RelightAnyone: A Generalized Relightable 3D Gaussian Head Model
Jan 06, 20263D Gaussian Splatting (3DGS) has become a standard approach to reconstruct and render photorealistic 3D head avatars. A major challenge is to relight the avatars to match any scene illumination. For high quality relighting, existing methods require subjects to be captured under complex time-multiplexed illumination, such as one-light-at-a-time (OLAT). We propose a new generalized relightable 3D Gaussian head model that can relight any subject observed in a single- or multi-view images without requiring OLAT data for that subject. Our core idea is to learn a mapping from flat-lit 3DGS avatars to corresponding relightable Gaussian parameters for that avatar. Our model consists of two stages: a first stage that models flat-lit 3DGS avatars without OLAT lighting, and a second stage that learns the mapping to physically-based reflectance parameters for high-quality relighting. This two-stage design allows us to train the first stage across diverse existing multi-view datasets without OLAT lighting ensuring cross-subject generalization, where we learn a dataset-specific lighting code for self-supervised lighting alignment. Subsequently, the second stage can be trained on a significantly smaller dataset of subjects captured under OLAT illumination. Together, this allows our method to generalize well and relight any subject from the first stage as if we had captured them under OLAT lighting. Furthermore, we can fit our model to unseen subjects from as little as a single image, allowing several applications in novel view synthesis and relighting for digital avatars.
MuS-Polar3D: A Benchmark Dataset for Computational Polarimetric 3D Imaging under Multi-Scattering Conditions
Dec 25, 2025Polarization-based underwater 3D imaging exploits polarization cues to suppress background scattering, exhibiting distinct advantages in turbid water. Although data-driven polarization-based underwater 3D reconstruction methods show great potential, existing public datasets lack sufficient diversity in scattering and observation conditions, hindering fair comparisons among different approaches, including single-view and multi-view polarization imaging methods. To address this limitation, we construct MuS-Polar3D, a benchmark dataset comprising polarization images of 42 objects captured under seven quantitatively controlled scattering conditions and five viewpoints, together with high-precision 3D models (+/- 0.05 mm accuracy), normal maps, and foreground masks. The dataset supports multiple vision tasks, including normal estimation, object segmentation, descattering, and 3D reconstruction. Inspired by computational imaging, we further decouple underwater 3D reconstruction under scattering into a two-stage pipeline, namely descattering followed by 3D reconstruction, from an imaging-chain perspective. Extensive evaluations using multiple baseline methods under complex scattering conditions demonstrate the effectiveness of the proposed benchmark, achieving a best mean angular error of 15.49 degrees. To the best of our knowledge, MuS-Polar3D is the first publicly available benchmark dataset for quantitative turbidity underwater polarization-based 3D imaging, enabling accurate reconstruction and fair algorithm evaluation under controllable scattering conditions. The dataset and code are publicly available at https://github.com/WangPuyun/MuS-Polar3D.