 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowObject: Flow Steering for Bridging Generative Priors and Reconstruction Fidelity
Jun 17, 2026Recovering complete 3D representations of objects from few casual image captures remains a significant challenge. Recent 3D generative models, particularly those based on Flow-Matching (FM), can synthesize high-quality textured assets; however, they often suffer from ''synthetic bias'' where learned priors override observational evidence, alongside a lack of alignment with the observed instance. Conversely, optimization-based methods like 3D Gaussian Splatting (3DGS) provide high fidelity on visible surfaces but fail to reason about unobserved geometry. In this paper, we present FlowObject, a framework that reformulates sparse-view 3D reconstruction as a training-free, guided inverse problem. Our approach applies a dual-space guidance strategy to steer the Ordinary Differential Equation (ODE) trajectory of a flow-matching model, enabling the completion of unseen regions through learned generative priors while enforcing strict consistency with real-world observations. By integrating a 3DGS refinement stage, FlowObject further bridges the gap between ''synthetic-looking'' generative outputs and photorealistic reconstructions. Comprehensive benchmarks on synthetic and real-world datasets demonstrate that current state-of-the-art methods often struggle to achieve geometric completeness and observational consistency simultaneously, especially under severe occlusions. In contrast, our method significantly outperforms state-of-the-art generative models and optimization-based frameworks in both geometric completeness and view-dependent appearance fidelity.
TerraSky3D: Multi-View Reconstructions of European Landmarks in 4K
Mar 30, 2026Despite the growing need for data of more and more sophisticated 3D reconstruction pipelines, we can still observe a scarcity of suitable public datasets. Existing 3D datasets are either low resolution, limited to a small amount of scenes, based on images of varying quality because retrieved from the internet, or limited to specific capturing scenarios. Motivated by this lack of suitable 3D datasets, we captured TerraSky3D, a high-resolution large-scale 3D reconstruction dataset comprising 50,000 images divided into 150 ground, aerial, and mixed scenes. The dataset focuses on European landmarks and comes with curated calibration data, camera poses, and depth maps. TerraSky3D tries to answer the need for challenging dataset that can be used to train and evaluate 3D reconstruction-related pipelines.
LEAR: Learning Edge-Aware Representations for Event-to-LiDAR Localization
Mar 02, 2026Event cameras offer high-temporal-resolution sensing that remains reliable under high-speed motion and challenging lighting, making them promising for localization from LiDAR point clouds in GPS-denied and visually degraded environments. However, aligning sparse, asynchronous events with dense LiDAR maps is fundamentally ill-posed, as direct correspondence estimation suffers from modality gaps. We propose LEAR, a dual-task learning framework that jointly estimates edge structures and dense event-depth flow fields to bridge the sensing-modality divide. Instead of treating edges as a post-hoc aid, LEAR couples them with flow estimation through a cross-modal fusion mechanism that injects modality-invariant geometric cues into the motion representation, and an iterative refinement strategy that enforces mutual consistency between the two tasks over multiple update steps. This synergy produces edge-aware, depth-aligned flow fields that enable more robust and accurate pose recovery via Perspective-n-Point (PnP) solvers. On several popular and challenging datasets, LEAR achieves superior performance over the best prior method. The source code, trained models, and demo videos are made publicly available online.
A Streamlined Attention-Based Network for Descriptor Extraction
Jan 19, 2026We introduce SANDesc, a Streamlined Attention-Based Network for Descriptor extraction that aims to improve on existing architectures for keypoint description. Our descriptor network learns to compute descriptors that improve matching without modifying the underlying keypoint detector. We employ a revised U-Net-like architecture enhanced with Convolutional Block Attention Modules and residual paths, enabling effective local representation while maintaining computational efficiency. We refer to the building blocks of our model as Residual U-Net Blocks with Attention. The model is trained using a modified triplet loss in combination with a curriculum learning-inspired hard negative mining strategy, which improves training stability. Extensive experiments on HPatches, MegaDepth-1500, and the Image Matching Challenge 2021 show that training SANDesc on top of existing keypoint detectors leads to improved results on multiple matching tasks compared to the original keypoint descriptors. At the same time, SANDesc has a model complexity of just 2.4 million parameters. As a further contribution, we introduce a new urban dataset featuring 4K images and pre-calibrated intrinsics, designed to evaluate feature extractors. On this benchmark, SANDesc achieves substantial performance gains over the existing descriptors while operating with limited computational resources.
Trifocal Tensor and Relative Pose Estimation with Known Vertical Direction
Dec 22, 2025This work presents two novel solvers for estimating the relative poses among views with known vertical directions. The vertical directions of camera views can be easily obtained using inertial measurement units (IMUs) which have been widely used in autonomous vehicles, mobile phones, and unmanned aerial vehicles (UAVs). Given the known vertical directions, our lgorithms only need to solve for two rotation angles and two translation vectors. In this paper, a linear closed-form solution has been described, requiring only four point correspondences in three views. We also propose a minimal solution with three point correspondences using the latest Gröbner basis solver. Since the proposed methods require fewer point correspondences, they can be efficiently applied within the RANSAC framework for outliers removal and pose estimation in visual odometry. The proposed method has been tested on both synthetic data and real-world scenes from KITTI. The experimental results show that the accuracy of the estimated poses is superior to other alternative methods.
${C}^{3}$-GS: Learning Context-aware, Cross-dimension, Cross-scale Feature for Generalizable Gaussian Splatting
Aug 28, 2025



Generalizable Gaussian Splatting aims to synthesize novel views for unseen scenes without per-scene optimization. In particular, recent advancements utilize feed-forward networks to predict per-pixel Gaussian parameters, enabling high-quality synthesis from sparse input views. However, existing approaches fall short in encoding discriminative, multi-view consistent features for Gaussian predictions, which struggle to construct accurate geometry with sparse views. To address this, we propose $\mathbf{C}^{3}$-GS, a framework that enhances feature learning by incorporating context-aware, cross-dimension, and cross-scale constraints. Our architecture integrates three lightweight modules into a unified rendering pipeline, improving feature fusion and enabling photorealistic synthesis without requiring additional supervision. Extensive experiments on benchmark datasets validate that $\mathbf{C}^{3}$-GS achieves state-of-the-art rendering quality and generalization ability. Code is available at: https://github.com/YuhsiHu/C3-GS.
Leveraging Automatic CAD Annotations for Supervised Learning in 3D Scene Understanding
Apr 18, 2025High-level 3D scene understanding is essential in many applications. However, the challenges of generating accurate 3D annotations make development of deep learning models difficult. We turn to recent advancements in automatic retrieval of synthetic CAD models, and show that data generated by such methods can be used as high-quality ground truth for training supervised deep learning models. More exactly, we employ a pipeline akin to the one previously used to automatically annotate objects in ScanNet scenes with their 9D poses and CAD models. This time, we apply it to the recent ScanNet++ v1 dataset, which previously lacked such annotations. Our findings demonstrate that it is not only possible to train deep learning models on these automatically-obtained annotations but that the resulting models outperform those trained on manually annotated data. We validate this on two distinct tasks: point cloud completion and single-view CAD model retrieval and alignment. Our results underscore the potential of automatic 3D annotations to enhance model performance while significantly reducing annotation costs. To support future research in 3D scene understanding, we will release our annotations, which we call SCANnotate++, along with our trained models.
ICG-MVSNet: Learning Intra-view and Cross-view Relationships for Guidance in Multi-View Stereo
Mar 27, 2025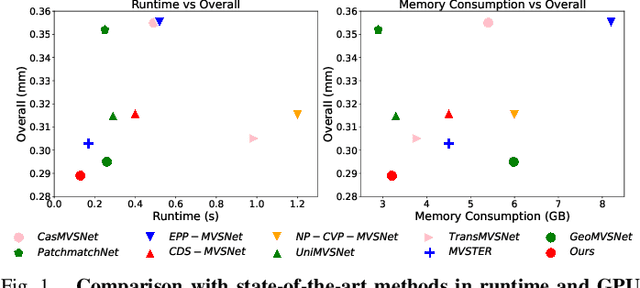
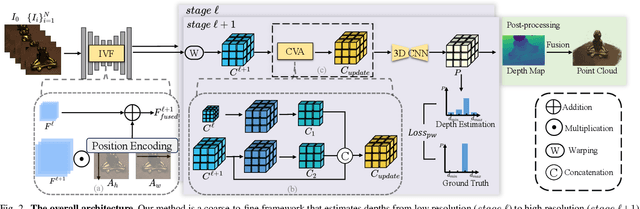
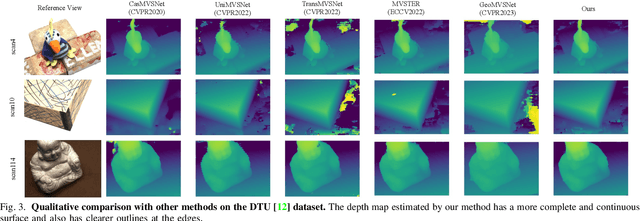

Multi-view Stereo (MVS) aims to estimate depth and reconstruct 3D point clouds from a series of overlapping images. Recent learning-based MVS frameworks overlook the geometric information embedded in features and correlations, leading to weak cost matching. In this paper, we propose ICG-MVSNet, which explicitly integrates intra-view and cross-view relationships for depth estimation. Specifically, we develop an intra-view feature fusion module that leverages the feature coordinate correlations within a single image to enhance robust cost matching. Additionally, we introduce a lightweight cross-view aggregation module that efficiently utilizes the contextual information from volume correlations to guide regularization. Our method is evaluated on the DTU dataset and Tanks and Temples benchmark, consistently achieving competitive performance against state-of-the-art works, while requiring lower computational resources.
SAda-Net: A Self-Supervised Adaptive Stereo Estimation CNN For Remote Sensing Image Data
Oct 17, 2024Stereo estimation has made many advancements in recent years with the introduction of deep-learning. However the traditional supervised approach to deep-learning requires the creation of accurate and plentiful ground-truth data, which is expensive to create and not available in many situations. This is especially true for remote sensing applications, where there is an excess of available data without proper ground truth. To tackle this problem, we propose a self-supervised CNN with self-improving adaptive abilities. In the first iteration, the created disparity map is inaccurate and noisy. Leveraging the left-right consistency check, we get a sparse but more accurate disparity map which is used as an initial pseudo ground-truth. This pseudo ground-truth is then adapted and updated after every epoch in the training step of the network. We use the sum of inconsistent points in order to track the network convergence. The code for our method is publicly available at: https://github.com/thedodo/SAda-Net}{https://github.com/thedodo/SAda-Net
GMM-IKRS: Gaussian Mixture Models for Interpretable Keypoint Refinement and Scoring
Aug 30, 2024



The extraction of keypoints in images is at the basis of many computer vision applications, from localization to 3D reconstruction. Keypoints come with a score permitting to rank them according to their quality. While learned keypoints often exhibit better properties than handcrafted ones, their scores are not easily interpretable, making it virtually impossible to compare the quality of individual keypoints across methods. We propose a framework that can refine, and at the same time characterize with an interpretable score, the keypoints extracted by any method. Our approach leverages a modified robust Gaussian Mixture Model fit designed to both reject non-robust keypoints and refine the remaining ones. Our score comprises two components: one relates to the probability of extracting the same keypoint in an image captured from another viewpoint, the other relates to the localization accuracy of the keypoint. These two interpretable components permit a comparison of individual keypoints extracted across different methods. Through extensive experiments we demonstrate that, when applied to popular keypoint detectors, our framework consistently improves the repeatability of keypoints as well as their performance in homography and two/multiple-view pose recovery tasks.