 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuxRemix: Lighting Decomposition and Remixing for Indoor Scenes
Jan 21, 2026We present a novel approach for interactive light editing in indoor scenes from a single multi-view scene capture. Our method leverages a generative image-based light decomposition model that factorizes complex indoor scene illumination into its constituent light sources. This factorization enables independent manipulation of individual light sources, specifically allowing control over their state (on/off), chromaticity, and intensity. We further introduce multi-view lighting harmonization to ensure consistent propagation of the lighting decomposition across all scene views. This is integrated into a relightable 3D Gaussian splatting representation, providing real-time interactive control over the individual light sources. Our results demonstrate highly photorealistic lighting decomposition and relighting outcomes across diverse indoor scenes. We evaluate our method on both synthetic and real-world datasets and provide a quantitative and qualitative comparison to state-of-the-art techniques. For video results and interactive demos, see https://luxremix.github.io.
Easy3D: A Simple Yet Effective Method for 3D Interactive Segmentation
Apr 15, 2025



The increasing availability of digital 3D environments, whether through image-based 3D reconstruction, generation, or scans obtained by robots, is driving innovation across various applications. These come with a significant demand for 3D interaction, such as 3D Interactive Segmentation, which is useful for tasks like object selection and manipulation. Additionally, there is a persistent need for solutions that are efficient, precise, and performing well across diverse settings, particularly in unseen environments and with unfamiliar objects. In this work, we introduce a 3D interactive segmentation method that consistently surpasses previous state-of-the-art techniques on both in-domain and out-of-domain datasets. Our simple approach integrates a voxel-based sparse encoder with a lightweight transformer-based decoder that implements implicit click fusion, achieving superior performance and maximizing efficiency. Our method demonstrates substantial improvements on benchmark datasets, including ScanNet, ScanNet++, S3DIS, and KITTI-360, and also on unseen geometric distributions such as the ones obtained by Gaussian Splatting. The project web-page is available at https://simonelli-andrea.github.io/easy3d.
FlowR: Flowing from Sparse to Dense 3D Reconstructions
Apr 02, 2025



3D Gaussian splatting enables high-quality novel view synthesis (NVS) at real-time frame rates. However, its quality drops sharply as we depart from the training views. Thus, dense captures are needed to match the high-quality expectations of some applications, e.g. Virtual Reality (VR). However, such dense captures are very laborious and expensive to obtain. Existing works have explored using 2D generative models to alleviate this requirement by distillation or generating additional training views. These methods are often conditioned only on a handful of reference input views and thus do not fully exploit the available 3D information, leading to inconsistent generation results and reconstruction artifacts. To tackle this problem, we propose a multi-view, flow matching model that learns a flow to connect novel view renderings from possibly sparse reconstructions to renderings that we expect from dense reconstructions. This enables augmenting scene captures with novel, generated views to improve reconstruction quality. Our model is trained on a novel dataset of 3.6M image pairs and can process up to 45 views at 540x960 resolution (91K tokens) on one H100 GPU in a single forward pass. Our pipeline consistently improves NVS in sparse- and dense-view scenarios, leading to higher-quality reconstructions than prior works across multiple, widely-used NVS benchmarks.
Fillerbuster: Multi-View Scene Completion for Casual Captures
Feb 07, 2025
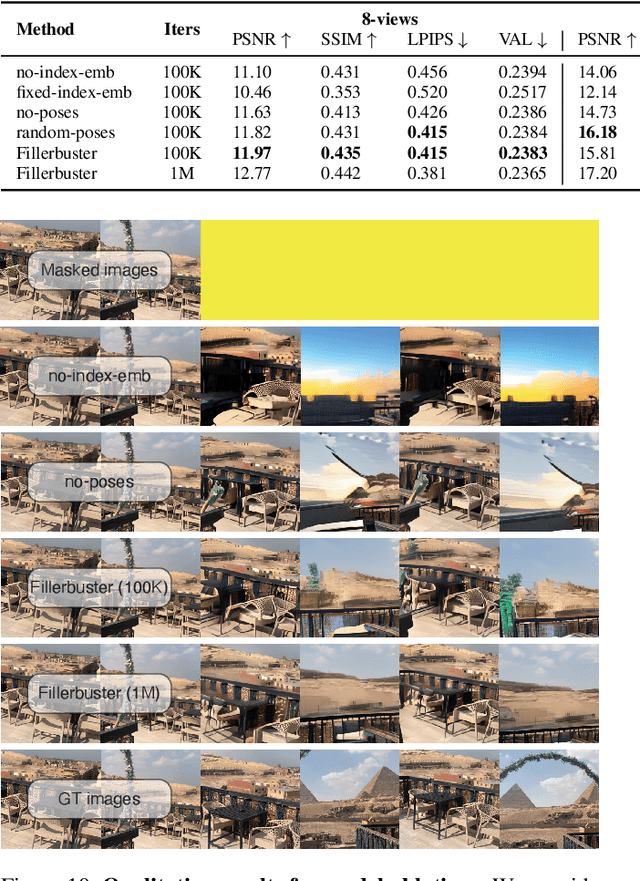
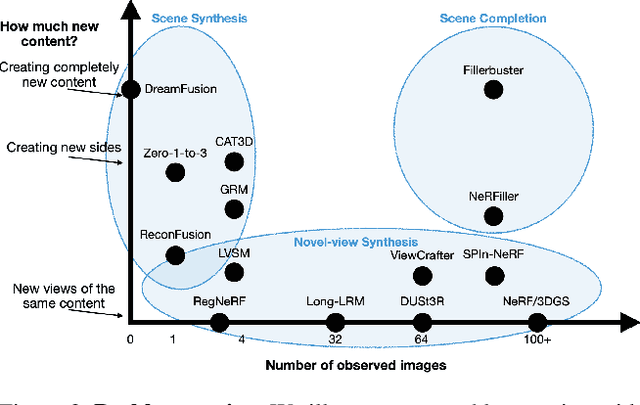

We present Fillerbuster, a method that completes unknown regions of a 3D scene by utilizing a novel large-scale multi-view latent diffusion transformer. Casual captures are often sparse and miss surrounding content behind objects or above the scene. Existing methods are not suitable for handling this challenge as they focus on making the known pixels look good with sparse-view priors, or on creating the missing sides of objects from just one or two photos. In reality, we often have hundreds of input frames and want to complete areas that are missing and unobserved from the input frames. Additionally, the images often do not have known camera parameters. Our solution is to train a generative model that can consume a large context of input frames while generating unknown target views and recovering image poses when desired. We show results where we complete partial captures on two existing datasets. We also present an uncalibrated scene completion task where our unified model predicts both poses and creates new content. Our model is the first to predict many images and poses together for scene completion.
Coherent 3D Scene Diffusion From a Single RGB Image
Dec 13, 2024



We present a novel diffusion-based approach for coherent 3D scene reconstruction from a single RGB image. Our method utilizes an image-conditioned 3D scene diffusion model to simultaneously denoise the 3D poses and geometries of all objects within the scene. Motivated by the ill-posed nature of the task and to obtain consistent scene reconstruction results, we learn a generative scene prior by conditioning on all scene objects simultaneously to capture the scene context and by allowing the model to learn inter-object relationships throughout the diffusion process. We further propose an efficient surface alignment loss to facilitate training even in the absence of full ground-truth annotation, which is common in publicly available datasets. This loss leverages an expressive shape representation, which enables direct point sampling from intermediate shape predictions. By framing the task of single RGB image 3D scene reconstruction as a conditional diffusion process, our approach surpasses current state-of-the-art methods, achieving a 12.04% improvement in AP3D on SUN RGB-D and a 13.43% increase in F-Score on Pix3D.
Multi-view Image Diffusion via Coordinate Noise and Fourier Attention
Dec 04, 2024



Recently, text-to-image generation with diffusion models has made significant advancements in both higher fidelity and generalization capabilities compared to previous baselines. However, generating holistic multi-view consistent images from prompts still remains an important and challenging task. To address this challenge, we propose a diffusion process that attends to time-dependent spatial frequencies of features with a novel attention mechanism as well as novel noise initialization technique and cross-attention loss. This Fourier-based attention block focuses on features from non-overlapping regions of the generated scene in order to better align the global appearance. Our noise initialization technique incorporates shared noise and low spatial frequency information derived from pixel coordinates and depth maps to induce noise correlations across views. The cross-attention loss further aligns features sharing the same prompt across the scene. Our technique improves SOTA on several quantitative metrics with qualitatively better results when compared to other state-of-the-art approaches for multi-view consistency.
L3DG: Latent 3D Gaussian Diffusion
Oct 17, 2024



We propose L3DG, the first approach for generative 3D modeling of 3D Gaussians through a latent 3D Gaussian diffusion formulation. This enables effective generative 3D modeling, scaling to generation of entire room-scale scenes which can be very efficiently rendered. To enable effective synthesis of 3D Gaussians, we propose a latent diffusion formulation, operating in a compressed latent space of 3D Gaussians. This compressed latent space is learned by a vector-quantized variational autoencoder (VQ-VAE), for which we employ a sparse convolutional architecture to efficiently operate on room-scale scenes. This way, the complexity of the costly generation process via diffusion is substantially reduced, allowing higher detail on object-level generation, as well as scalability to large scenes. By leveraging the 3D Gaussian representation, the generated scenes can be rendered from arbitrary viewpoints in real-time. We demonstrate that our approach significantly improves visual quality over prior work on unconditional object-level radiance field synthesis and showcase its applicability to room-scale scene generation.
MultiDiff: Consistent Novel View Synthesis from a Single Image
Jun 26, 2024



We introduce MultiDiff, a novel approach for consistent novel view synthesis of scenes from a single RGB image. The task of synthesizing novel views from a single reference image is highly ill-posed by nature, as there exist multiple, plausible explanations for unobserved areas. To address this issue, we incorporate strong priors in form of monocular depth predictors and video-diffusion models. Monocular depth enables us to condition our model on warped reference images for the target views, increasing geometric stability. The video-diffusion prior provides a strong proxy for 3D scenes, allowing the model to learn continuous and pixel-accurate correspondences across generated images. In contrast to approaches relying on autoregressive image generation that are prone to drifts and error accumulation, MultiDiff jointly synthesizes a sequence of frames yielding high-quality and multi-view consistent results -- even for long-term scene generation with large camera movements, while reducing inference time by an order of magnitude. For additional consistency and image quality improvements, we introduce a novel, structured noise distribution. Our experimental results demonstrate that MultiDiff outperforms state-of-the-art methods on the challenging, real-world datasets RealEstate10K and ScanNet. Finally, our model naturally supports multi-view consistent editing without the need for further tuning.
ConsistDreamer: 3D-Consistent 2D Diffusion for High-Fidelity Scene Editing
Jun 13, 2024



This paper proposes ConsistDreamer - a novel framework that lifts 2D diffusion models with 3D awareness and 3D consistency, thus enabling high-fidelity instruction-guided scene editing. To overcome the fundamental limitation of missing 3D consistency in 2D diffusion models, our key insight is to introduce three synergetic strategies that augment the input of the 2D diffusion model to become 3D-aware and to explicitly enforce 3D consistency during the training process. Specifically, we design surrounding views as context-rich input for the 2D diffusion model, and generate 3D-consistent, structured noise instead of image-independent noise. Moreover, we introduce self-supervised consistency-enforcing training within the per-scene editing procedure. Extensive evaluation shows that our ConsistDreamer achieves state-of-the-art performance for instruction-guided scene editing across various scenes and editing instructions, particularly in complicated large-scale indoor scenes from ScanNet++, with significantly improved sharpness and fine-grained textures. Notably, ConsistDreamer stands as the first work capable of successfully editing complex (e.g., plaid/checkered) patterns. Our project page is at immortalco.github.io/ConsistDreamer.
ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
Mar 04, 2024



3D asset generation is getting massive amounts of attention, inspired by the recent success of text-guided 2D content creation. Existing text-to-3D methods use pretrained text-to-image diffusion models in an optimization problem or fine-tune them on synthetic data, which often results in non-photorealistic 3D objects without backgrounds. In this paper, we present a method that leverages pretrained text-to-image models as a prior, and learn to generate multi-view images in a single denoising process from real-world data. Concretely, we propose to integrate 3D volume-rendering and cross-frame-attention layers into each block of the existing U-Net network of the text-to-image model. Moreover, we design an autoregressive generation that renders more 3D-consistent images at any viewpoint. We train our model on real-world datasets of objects and showcase its capabilities to generate instances with a variety of high-quality shapes and textures in authentic surroundings. Compared to the existing methods, the results generated by our method are consistent, and have favorable visual quality (-30% FID, -37% KID).