 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Position Embedding as a Context Controller for Multi-Reference and Multi-Shot Video Generation
Apr 04, 2026Recent proprietary models such as Sora2 demonstrate promising progress in generating multi-shot videos conditioned on multiple reference characters. However, academic research on this problem remains limited. We study this task and identify a core challenge: when reference images exhibit highly similar appearances, the model often suffers from reference confusion, where semantically similar tokens degrade the model's ability to retrieve the correct context. To address this, we introduce PoCo (Position Embedding as a Context Controller), which incorporates position encoding as additional context control beyond semantic retrieval. By employing side information of tokens, PoCo enables precise token-level matching while preserving implicit semantic consistency modeling. Building on PoCo, we develop a multi-reference and multi-shot video generation model capable of reliably controlling characters with extremely similar visual traits. Extensive experiments demonstrate that PoCo improves cross-shot consistency and reference fidelity compared with various baselines.
Forgetting-Resistant and Lesion-Aware Source-Free Domain Adaptive Fundus Image Analysis with Vision-Language Model
Feb 23, 2026Source-free domain adaptation (SFDA) aims to adapt a model trained in the source domain to perform well in the target domain, with only unlabeled target domain data and the source model. Taking into account that conventional SFDA methods are inevitably error-prone under domain shift, recently greater attention has been directed to SFDA assisted with off-the-shelf foundation models, e.g., vision-language (ViL) models. However, existing works of leveraging ViL models for SFDA confront two issues: (i) Although mutual information is exploited to consider the joint distribution between the predictions of ViL model and the target model, we argue that the forgetting of some superior predictions of the target model still occurs, as indicated by the decline of the accuracies of certain classes during adaptation; (ii) Prior research disregards the rich, fine-grained knowledge embedded in the ViL model, which offers detailed grounding for fundus image diagnosis. In this paper, we introduce a novel forgetting-resistant and lesion-aware (FRLA) method for SFDA of fundus image diagnosis with ViL model. Specifically, a forgetting-resistant adaptation module explicitly preserves the confident predictions of the target model, and a lesion-aware adaptation module yields patch-wise predictions from ViL model and employs them to help the target model be aware of the lesion areas and leverage the ViL model's fine-grained knowledge. Extensive experiments show that our method not only significantly outperforms the vision-language model, but also achieves consistent improvements over the state-of-the-art methods. Our code will be released.
Cross-view Generalized Diffusion Model for Sparse-view CT Reconstruction
Aug 14, 2025Sparse-view computed tomography (CT) reduces radiation exposure by subsampling projection views, but conventional reconstruction methods produce severe streak artifacts with undersampled data. While deep-learning-based methods enable single-step artifact suppression, they often produce over-smoothed results under significant sparsity. Though diffusion models improve reconstruction via iterative refinement and generative priors, they require hundreds of sampling steps and struggle with stability in highly sparse regimes. To tackle these concerns, we present the Cross-view Generalized Diffusion Model (CvG-Diff), which reformulates sparse-view CT reconstruction as a generalized diffusion process. Unlike existing diffusion approaches that rely on stochastic Gaussian degradation, CvG-Diff explicitly models image-domain artifacts caused by angular subsampling as a deterministic degradation operator, leveraging correlations across sparse-view CT at different sample rates. To address the inherent artifact propagation and inefficiency of sequential sampling in generalized diffusion model, we introduce two innovations: Error-Propagating Composite Training (EPCT), which facilitates identifying error-prone regions and suppresses propagated artifacts, and Semantic-Prioritized Dual-Phase Sampling (SPDPS), an adaptive strategy that prioritizes semantic correctness before detail refinement. Together, these innovations enable CvG-Diff to achieve high-quality reconstructions with minimal iterations, achieving 38.34 dB PSNR and 0.9518 SSIM for 18-view CT using only \textbf{10} steps on AAPM-LDCT dataset. Extensive experiments demonstrate the superiority of CvG-Diff over state-of-the-art sparse-view CT reconstruction methods. The code is available at https://github.com/xmed-lab/CvG-Diff.
UniEval: Unified Holistic Evaluation for Unified Multimodal Understanding and Generation
May 15, 2025The emergence of unified multimodal understanding and generation models is rapidly attracting attention because of their ability to enhance instruction-following capabilities while minimizing model redundancy. However, there is a lack of a unified evaluation framework for these models, which would enable an elegant, simplified, and overall evaluation. Current models conduct evaluations on multiple task-specific benchmarks, but there are significant limitations, such as the lack of overall results, errors from extra evaluation models, reliance on extensive labeled images, benchmarks that lack diversity, and metrics with limited capacity for instruction-following evaluation. To tackle these challenges, we introduce UniEval, the first evaluation framework designed for unified multimodal models without extra models, images, or annotations. This facilitates a simplified and unified evaluation process. The UniEval framework contains a holistic benchmark, UniBench (supports both unified and visual generation models), along with the corresponding UniScore metric. UniBench includes 81 fine-grained tags contributing to high diversity. Experimental results indicate that UniBench is more challenging than existing benchmarks, and UniScore aligns closely with human evaluations, surpassing current metrics. Moreover, we extensively evaluated SoTA unified and visual generation models, uncovering new insights into Univeral's unique values.
DeepSparse: A Foundation Model for Sparse-View CBCT Reconstruction
May 05, 2025Cone-beam computed tomography (CBCT) is a critical 3D imaging technology in the medical field, while the high radiation exposure required for high-quality imaging raises significant concerns, particularly for vulnerable populations. Sparse-view reconstruction reduces radiation by using fewer X-ray projections while maintaining image quality, yet existing methods face challenges such as high computational demands and poor generalizability to different datasets. To overcome these limitations, we propose DeepSparse, the first foundation model for sparse-view CBCT reconstruction, featuring DiCE (Dual-Dimensional Cross-Scale Embedding), a novel network that integrates multi-view 2D features and multi-scale 3D features. Additionally, we introduce the HyViP (Hybrid View Sampling Pretraining) framework, which pretrains the model on large datasets with both sparse-view and dense-view projections, and a two-step finetuning strategy to adapt and refine the model for new datasets. Extensive experiments and ablation studies demonstrate that our proposed DeepSparse achieves superior reconstruction quality compared to state-of-the-art methods, paving the way for safer and more efficient CBCT imaging.
MuTri: Multi-view Tri-alignment for OCT to OCTA 3D Image Translation
Apr 02, 2025



Optical coherence tomography angiography (OCTA) shows its great importance in imaging microvascular networks by providing accurate 3D imaging of blood vessels, but it relies upon specialized sensors and expensive devices. For this reason, previous works show the potential to translate the readily available 3D Optical Coherence Tomography (OCT) images into 3D OCTA images. However, existing OCTA translation methods directly learn the mapping from the OCT domain to the OCTA domain in continuous and infinite space with guidance from only a single view, i.e., the OCTA project map, resulting in suboptimal results. To this end, we propose the multi-view Tri-alignment framework for OCT to OCTA 3D image translation in discrete and finite space, named MuTri. In the first stage, we pre-train two vector-quantized variational auto-encoder (VQ- VAE) by reconstructing 3D OCT and 3D OCTA data, providing semantic prior for subsequent multi-view guidances. In the second stage, our multi-view tri-alignment facilitates another VQVAE model to learn the mapping from the OCT domain to the OCTA domain in discrete and finite space. Specifically, a contrastive-inspired semantic alignment is proposed to maximize the mutual information with the pre-trained models from OCT and OCTA views, to facilitate codebook learning. Meanwhile, a vessel structure alignment is proposed to minimize the structure discrepancy with the pre-trained models from the OCTA project map view, benefiting from learning the detailed vessel structure information. We also collect the first large-scale dataset, namely, OCTA2024, which contains a pair of OCT and OCTA volumes from 846 subjects.
Vision Foundation Models in Medical Image Analysis: Advances and Challenges
Feb 21, 2025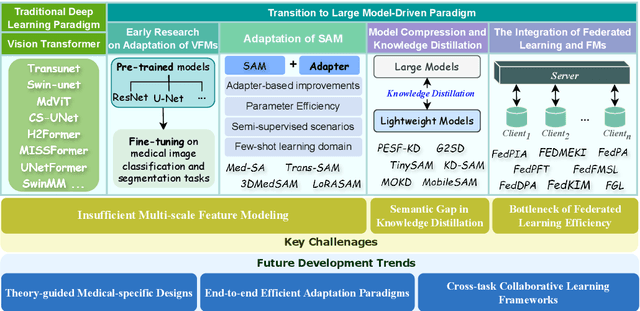
The rapid development of Vision Foundation Models (VFMs), particularly Vision Transformers (ViT) and Segment Anything Model (SAM), has sparked significant advances in the field of medical image analysis. These models have demonstrated exceptional capabilities in capturing long-range dependencies and achieving high generalization in segmentation tasks. However, adapting these large models to medical image analysis presents several challenges, including domain differences between medical and natural images, the need for efficient model adaptation strategies, and the limitations of small-scale medical datasets. This paper reviews the state-of-the-art research on the adaptation of VFMs to medical image segmentation, focusing on the challenges of domain adaptation, model compression, and federated learning. We discuss the latest developments in adapter-based improvements, knowledge distillation techniques, and multi-scale contextual feature modeling, and propose future directions to overcome these bottlenecks. Our analysis highlights the potential of VFMs, along with emerging methodologies such as federated learning and model compression, to revolutionize medical image analysis and enhance clinical applications. The goal of this work is to provide a comprehensive overview of current approaches and suggest key areas for future research that can drive the next wave of innovation in medical image segmentation.
Tri-Plane Mamba: Efficiently Adapting Segment Anything Model for 3D Medical Images
Sep 13, 2024General networks for 3D medical image segmentation have recently undergone extensive exploration. Behind the exceptional performance of these networks lies a significant demand for a large volume of pixel-level annotated data, which is time-consuming and labor-intensive. The emergence of the Segment Anything Model (SAM) has enabled this model to achieve superior performance in 2D medical image segmentation tasks via parameter- and data-efficient feature adaptation. However, the introduction of additional depth channels in 3D medical images not only prevents the sharing of 2D pre-trained features but also results in a quadratic increase in the computational cost for adapting SAM. To overcome these challenges, we present the Tri-Plane Mamba (TP-Mamba) adapters tailored for the SAM, featuring two major innovations: 1) multi-scale 3D convolutional adapters, optimized for efficiently processing local depth-level information, 2) a tri-plane mamba module, engineered to capture long-range depth-level representation without significantly increasing computational costs. This approach achieves state-of-the-art performance in 3D CT organ segmentation tasks. Remarkably, this superior performance is maintained even with scarce training data. Specifically using only three CT training samples from the BTCV dataset, it surpasses conventional 3D segmentation networks, attaining a Dice score that is up to 12% higher.
Learning Unlabeled Clients Divergence via Anchor Model Aggregation for Federated Semi-supervised Learning
Jul 14, 2024



Federated semi-supervised learning (FedSemi) refers to scenarios where there may be clients with fully labeled data, clients with partially labeled, and even fully unlabeled clients while preserving data privacy. However, challenges arise from client drift due to undefined heterogeneous class distributions and erroneous pseudo-labels. Existing FedSemi methods typically fail to aggregate models from unlabeled clients due to their inherent unreliability, thus overlooking unique information from their heterogeneous data distribution, leading to sub-optimal results. In this paper, we enable unlabeled client aggregation through SemiAnAgg, a novel Semi-supervised Anchor-Based federated Aggregation. SemiAnAgg learns unlabeled client contributions via an anchor model, effectively harnessing their informative value. Our key idea is that by feeding local client data to the same global model and the same consistently initialized anchor model (i.e., random model), we can measure the importance of each unlabeled client accordingly. Extensive experiments demonstrate that SemiAnAgg achieves new state-of-the-art results on four widely used FedSemi benchmarks, leading to substantial performance improvements: a 9% increase in accuracy on CIFAR-100 and a 7.6% improvement in recall on the medical dataset ISIC-18, compared with prior state-of-the-art. Code is available at: https://github.com/xmed-lab/SemiAnAgg.
Learning 3D Gaussians for Extremely Sparse-View Cone-Beam CT Reconstruction
Jul 01, 2024Cone-Beam Computed Tomography (CBCT) is an indispensable technique in medical imaging, yet the associated radiation exposure raises concerns in clinical practice. To mitigate these risks, sparse-view reconstruction has emerged as an essential research direction, aiming to reduce the radiation dose by utilizing fewer projections for CT reconstruction. Although implicit neural representations have been introduced for sparse-view CBCT reconstruction, existing methods primarily focus on local 2D features queried from sparse projections, which is insufficient to process the more complicated anatomical structures, such as the chest. To this end, we propose a novel reconstruction framework, namely DIF-Gaussian, which leverages 3D Gaussians to represent the feature distribution in the 3D space, offering additional 3D spatial information to facilitate the estimation of attenuation coefficients. Furthermore, we incorporate test-time optimization during inference to further improve the generalization capability of the model. We evaluate DIF-Gaussian on two public datasets, showing significantly superior reconstruction performance than previous state-of-the-art methods.