 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICG-MVSNet: Learning Intra-view and Cross-view Relationships for Guidance in Multi-View Stereo
Mar 27, 2025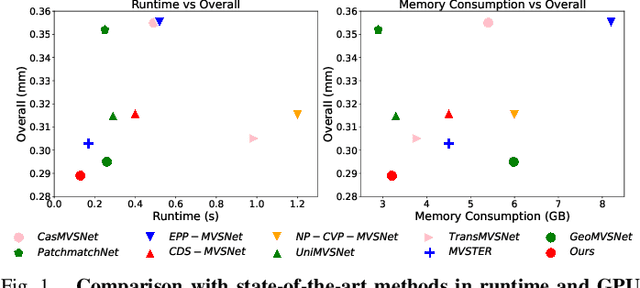
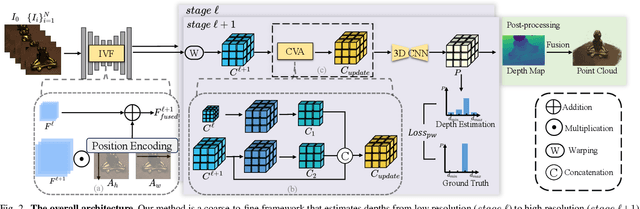
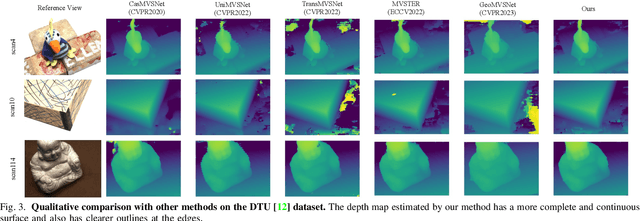

Multi-view Stereo (MVS) aims to estimate depth and reconstruct 3D point clouds from a series of overlapping images. Recent learning-based MVS frameworks overlook the geometric information embedded in features and correlations, leading to weak cost matching. In this paper, we propose ICG-MVSNet, which explicitly integrates intra-view and cross-view relationships for depth estimation. Specifically, we develop an intra-view feature fusion module that leverages the feature coordinate correlations within a single image to enhance robust cost matching. Additionally, we introduce a lightweight cross-view aggregation module that efficiently utilizes the contextual information from volume correlations to guide regularization. Our method is evaluated on the DTU dataset and Tanks and Temples benchmark, consistently achieving competitive performance against state-of-the-art works, while requiring lower computational resources.
GS-EVT: Cross-Modal Event Camera Tracking based on Gaussian Splatting
Sep 28, 2024Reliable self-localization is a foundational skill for many intelligent mobile platforms. This paper explores the use of event cameras for motion tracking thereby providing a solution with inherent robustness under difficult dynamics and illumination. In order to circumvent the challenge of event camera-based mapping, the solution is framed in a cross-modal way. It tracks a map representation that comes directly from frame-based cameras. Specifically, the proposed method operates on top of gaussian splatting, a state-of-the-art representation that permits highly efficient and realistic novel view synthesis. The key of our approach consists of a novel pose parametrization that uses a reference pose plus first order dynamics for local differential image rendering. The latter is then compared against images of integrated events in a staggered coarse-to-fine optimization scheme. As demonstrated by our results, the realistic view rendering ability of gaussian splatting leads to stable and accurate tracking across a variety of both publicly available and newly recorded data sequences.
EVIT: Event-based Visual-Inertial Tracking in Semi-Dense Maps Using Windowed Nonlinear Optimization
Aug 02, 2024Event cameras are an interesting visual exteroceptive sensor that reacts to brightness changes rather than integrating absolute image intensities. Owing to this design, the sensor exhibits strong performance in situations of challenging dynamics and illumination conditions. While event-based simultaneous tracking and mapping remains a challenging problem, a number of recent works have pointed out the sensor's suitability for prior map-based tracking. By making use of cross-modal registration paradigms, the camera's ego-motion can be tracked across a large spectrum of illumination and dynamics conditions on top of accurate maps that have been created a priori by more traditional sensors. The present paper follows up on a recently introduced event-based geometric semi-dense tracking paradigm, and proposes the addition of inertial signals in order to robustify the estimation. More specifically, the added signals provide strong cues for pose initialization as well as regularization during windowed, multi-frame tracking. As a result, the proposed framework achieves increased performance under challenging illumination conditions as well as a reduction of the rate at which intermediate event representations need to be registered in order to maintain stable tracking across highly dynamic sequences. Our evaluation focuses on a diverse set of real world sequences and comprises a comparison of our proposed method against a purely event-based alternative running at different rates.
Scale jump-aware pose graph relaxation for monocular SLAM with re-initializations
Jul 23, 2023Pose graph relaxation has become an indispensable addition to SLAM enabling efficient global registration of sensor reference frames under the objective of satisfying pair-wise relative transformation constraints. The latter may be given by incremental motion estimation or global place recognition. While the latter case enables loop closures and drift compensation, care has to be taken in the monocular case in which local estimates of structure and displacements can differ from reality not just in terms of noise, but also in terms of a scale factor. Owing to the accumulation of scale propagation errors, this scale factor is drifting over time, hence scale-drift aware pose graph relaxation has been introduced. We extend this idea to cases in which the relative scale between subsequent sensor frames is unknown, a situation that can easily occur if monocular SLAM enters re-initialization and no reliable overlap between successive local maps can be identified. The approach is realized by a hybrid pose graph formulation that combines the regular similarity consistency terms with novel, scale-blind constraints. We apply the technique to the practically relevant case of small indoor service robots capable of effectuating purely rotational displacements, a condition that can easily cause tracking failures. We demonstrate that globally consistent trajectories can be recovered even if multiple re-initializations occur along the loop, and present an in-depth study of success and failure cases.
Incremental Semantic Localization using Hierarchical Clustering of Object Association Sets
Aug 28, 2022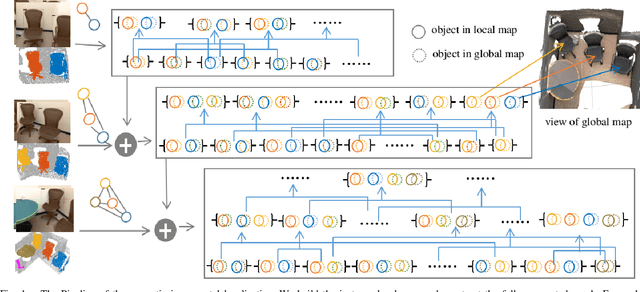
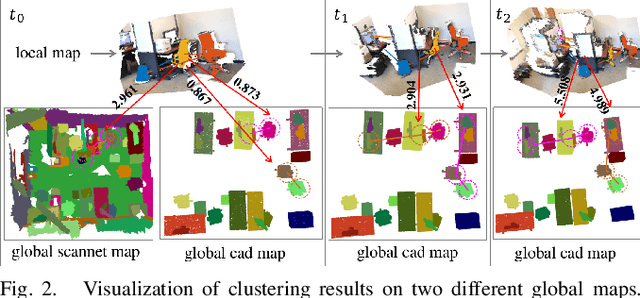
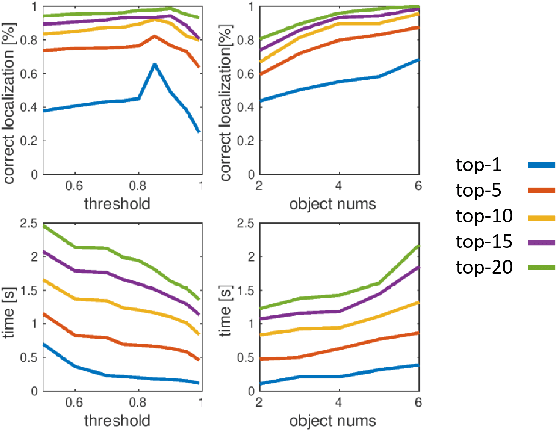
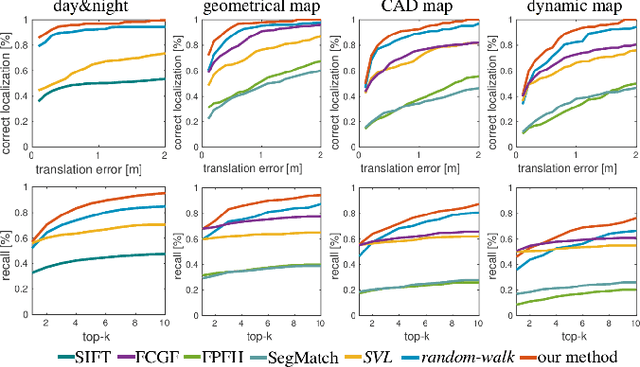
We present a novel approach for relocalization or place recognition, a fundamental problem to be solved in many robotics, automation, and AR applications. Rather than relying on often unstable appearance information, we consider a situation in which the reference map is given in the form of localized objects. Our localization framework relies on 3D semantic object detections, which are then associated to objects in the map. Possible pair-wise association sets are grown based on hierarchical clustering using a merge metric that evaluates spatial compatibility. The latter notably uses information about relative object configurations, which is invariant with respect to global transformations. Association sets are furthermore updated and expanded as the camera incrementally explores the environment and detects further objects. We test our algorithm in several challenging situations including dynamic scenes, large view-point changes, and scenes with repeated instances. Our experiments demonstrate that our approach outperforms prior art in terms of both robustness and accuracy.