 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Task Experiential Learning on LLM-based Multi-Agent Collaboration
May 29, 2025Large Language Model-based multi-agent systems (MAS) have shown remarkable progress in solving complex tasks through collaborative reasoning and inter-agent critique. However, existing approaches typically treat each task in isolation, resulting in redundant computations and limited generalization across structurally similar tasks. To address this, we introduce multi-agent cross-task experiential learning (MAEL), a novel framework that endows LLM-driven agents with explicit cross-task learning and experience accumulation. We model the task-solving workflow on a graph-structured multi-agent collaboration network, where agents propagate information and coordinate via explicit connectivity. During the experiential learning phase, we quantify the quality for each step in the task-solving workflow and store the resulting rewards along with the corresponding inputs and outputs into each agent's individual experience pool. During inference, agents retrieve high-reward, task-relevant experiences as few-shot examples to enhance the effectiveness of each reasoning step, thereby enabling more accurate and efficient multi-agent collaboration. Experimental results on diverse datasets demonstrate that MAEL empowers agents to learn from prior task experiences effectively-achieving faster convergence and producing higher-quality solutions on current tasks.
EULER: Enhancing the Reasoning Ability of Large Language Models through Error-Induced Learning
May 28, 2025Large Language Models (LLMs) have demonstrated strong reasoning capabilities and achieved promising results in mathematical problem-solving tasks. Learning from errors offers the potential to further enhance the performance of LLMs during Supervised Fine-Tuning (SFT). However, the errors in synthesized solutions are typically gathered from sampling trails, making it challenging to generate solution errors for each mathematical problem. This paper introduces the Error-IndUced LEaRning (EULER) model, which aims to develop an error exposure model that generates high-quality solution errors to enhance the mathematical reasoning capabilities of LLMs. Specifically, EULER optimizes the error exposure model to increase the generation probability of self-made solution errors while utilizing solutions produced by a superior LLM to regularize the generation quality. Our experiments across various mathematical problem datasets demonstrate the effectiveness of the EULER model, achieving an improvement of over 4% compared to all baseline models. Further analysis reveals that EULER is capable of synthesizing more challenging and educational solution errors, which facilitate both the training and inference processes of LLMs. All codes are available at https://github.com/NEUIR/EULER.
Co-Saving: Resource Aware Multi-Agent Collaboration for Software Development
May 28, 2025Recent advancements in Large Language Models (LLMs) and autonomous agents have demonstrated remarkable capabilities across various domains. However, standalone agents frequently encounter limitations when handling complex tasks that demand extensive interactions and substantial computational resources. Although Multi-Agent Systems (MAS) alleviate some of these limitations through collaborative mechanisms like task decomposition, iterative communication, and role specialization, they typically remain resource-unaware, incurring significant inefficiencies due to high token consumption and excessive execution time. To address these limitations, we propose a resource-aware multi-agent system -- Co-Saving (meaning that multiple agents collaboratively engage in resource-saving activities), which leverages experiential knowledge to enhance operational efficiency and solution quality. Our key innovation is the introduction of "shortcuts" -- instructional transitions learned from historically successful trajectories -- which allows to bypass redundant reasoning agents and expedite the collective problem-solving process. Experiments for software development tasks demonstrate significant advantages over existing methods. Specifically, compared to the state-of-the-art MAS ChatDev, our method achieves an average reduction of 50.85% in token usage, and improves the overall code quality by 10.06%.
Learning to Route Queries Across Knowledge Bases for Step-wise Retrieval-Augmented Reasoning
May 28, 2025



Multimodal Retrieval-Augmented Generation (MRAG) has shown promise in mitigating hallucinations in Multimodal Large Language Models (MLLMs) by incorporating external knowledge during generation. Existing MRAG methods typically adopt a static retrieval pipeline that fetches relevant information from multiple Knowledge Bases (KBs), followed by a refinement step. However, these approaches overlook the reasoning and planning capabilities of MLLMs to dynamically determine how to interact with different KBs during the reasoning process. To address this limitation, we propose R1-Router, a novel MRAG framework that learns to decide when and where to retrieve knowledge based on the evolving reasoning state. Specifically, R1-Router can generate follow-up queries according to the current reasoning step, routing these intermediate queries to the most suitable KB, and integrating external knowledge into a coherent reasoning trajectory to answer the original query. Furthermore, we introduce Step-wise Group Relative Policy Optimization (Step-GRPO), a tailored reinforcement learning algorithm that assigns step-specific rewards to optimize the reasoning behavior of MLLMs. Experimental results on various open-domain QA benchmarks across multiple modalities demonstrate that R1-Router outperforms baseline models by over 7%. Further analysis shows that R1-Router can adaptively and effectively leverage diverse KBs, reducing unnecessary retrievals and improving both efficiency and accuracy.
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
May 28, 2025



This paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
Monocle: Hybrid Local-Global In-Context Evaluation for Long-Text Generation with Uncertainty-Based Active Learning
May 27, 2025Assessing the quality of long-form, model-generated text is challenging, even with advanced LLM-as-a-Judge methods, due to performance degradation as input length increases. To address this issue, we propose a divide-and-conquer approach, which breaks down the comprehensive evaluation task into a series of localized scoring tasks, followed by a final global assessment. This strategy allows for more granular and manageable evaluations, ensuring that each segment of the text is assessed in isolation for both coherence and quality, while also accounting for the overall structure and consistency of the entire piece. Moreover, we introduce a hybrid in-context learning approach that leverages human annotations to enhance the performance of both local and global evaluations. By incorporating human-generated feedback directly into the evaluation process, this method allows the model to better align with human judgment. Finally, we develop an uncertainty-based active learning algorithm that efficiently selects data samples for human annotation, thereby reducing annotation costs in practical scenarios. Experimental results show that the proposed evaluation framework outperforms several representative baselines, highlighting the effectiveness of our approach.
AutoReproduce: Automatic AI Experiment Reproduction with Paper Lineage
May 27, 2025Efficient experiment reproduction is critical to accelerating progress in artificial intelligence. However, the inherent complexity of method design and training procedures presents substantial challenges for automation. Notably, reproducing experiments often requires implicit domain-specific knowledge not explicitly documented in the original papers. To address this, we introduce the paper lineage algorithm, which identifies and extracts implicit knowledge from the relevant references cited by the target paper. Building on this idea, we propose AutoReproduce, a multi-agent framework capable of automatically reproducing experiments described in research papers in an end-to-end manner. AutoReproduce enhances code executability by generating unit tests alongside the reproduction process. To evaluate the reproduction capability, we construct ReproduceBench, a benchmark annotated with verified implementations, and introduce novel evaluation metrics to assess both the reproduction and execution fidelity. Experimental results demonstrate that AutoReproduce outperforms the existing strong agent baselines on all five evaluation metrics by a peak margin of over $70\%$. In particular, compared to the official implementations, AutoReproduce achieves an average performance gap of $22.1\%$ on $89.74\%$ of the executable experiment runs. The code will be available at https://github.com/AI9Stars/AutoReproduce.
Multi-Agent Collaboration via Evolving Orchestration
May 26, 2025



Large language models (LLMs) have achieved remarkable results across diverse downstream tasks, but their monolithic nature restricts scalability and efficiency in complex problem-solving. While recent research explores multi-agent collaboration among LLMs, most approaches rely on static organizational structures that struggle to adapt as task complexity and agent numbers grow, resulting in coordination overhead and inefficiencies. To this end, we propose a puppeteer-style paradigm for LLM-based multi-agent collaboration, where a centralized orchestrator ("puppeteer") dynamically directs agents ("puppets") in response to evolving task states. This orchestrator is trained via reinforcement learning to adaptively sequence and prioritize agents, enabling flexible and evolvable collective reasoning. Experiments on closed- and open-domain scenarios show that this method achieves superior performance with reduced computational costs. Analyses further reveal that the key improvements consistently stem from the emergence of more compact, cyclic reasoning structures under the orchestrator's evolution.
The Overthinker's DIET: Cutting Token Calories with DIfficulty-AwarE Training
May 25, 2025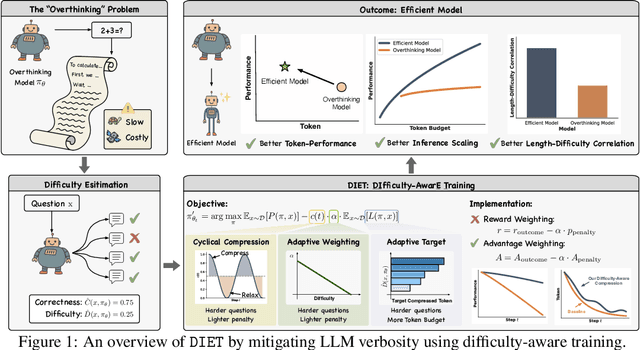



Recent large language models (LLMs) exhibit impressive reasoning but often over-think, generating excessively long responses that hinder efficiency. We introduce DIET ( DIfficulty-AwarE Training), a framework that systematically cuts these "token calories" by integrating on-the-fly problem difficulty into the reinforcement learning (RL) process. DIET dynamically adapts token compression strategies by modulating token penalty strength and conditioning target lengths on estimated task difficulty, to optimize the performance-efficiency trade-off. We also theoretically analyze the pitfalls of naive reward weighting in group-normalized RL algorithms like GRPO, and propose Advantage Weighting technique, which enables stable and effective implementation of these difficulty-aware objectives. Experimental results demonstrate that DIET significantly reduces token counts while simultaneously improving reasoning performance. Beyond raw token reduction, we show two crucial benefits largely overlooked by prior work: (1) DIET leads to superior inference scaling. By maintaining high per-sample quality with fewer tokens, it enables better scaling performance via majority voting with more samples under fixed computational budgets, an area where other methods falter. (2) DIET enhances the natural positive correlation between response length and problem difficulty, ensuring verbosity is appropriately allocated, unlike many existing compression methods that disrupt this relationship. Our analyses provide a principled and effective framework for developing more efficient, practical, and high-performing LLMs.
Using Large Language Models to Tackle Fundamental Challenges in Graph Learning: A Comprehensive Survey
May 24, 2025



Graphs are a widely used paradigm for representing non-Euclidean data, with applications ranging from social network analysis to biomolecular prediction. Conventional graph learning approaches typically rely on fixed structural assumptions or fully observed data, limiting their effectiveness in more complex, noisy, or evolving settings. Consequently, real-world graph data often violates the assumptions of traditional graph learning methods, in particular, it leads to four fundamental challenges: (1) Incompleteness, real-world graphs have missing nodes, edges, or attributes; (2) Imbalance, the distribution of the labels of nodes or edges and their structures for real-world graphs are highly skewed; (3) Cross-domain Heterogeneity, graphs from different domains exhibit incompatible feature spaces or structural patterns; and (4) Dynamic Instability, graphs evolve over time in unpredictable ways. Recent advances in Large Language Models (LLMs) offer the potential to tackle these challenges by leveraging rich semantic reasoning and external knowledge. This survey provides a comprehensive review of how LLMs can be integrated with graph learning to address the aforementioned challenges. For each challenge, we review both traditional solutions and modern LLM-driven approaches, highlighting how LLMs contribute unique advantages. Finally, we discuss open research questions and promising future directions in this emerging interdisciplinary field. To support further exploration, we have curated a repository of recent advances on graph learning challenges: https://github.com/limengran98/Awesome-Literature-Graph-Learning-Challenges.