 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Tackle Fundamental Challenges in Graph Learning: A Comprehensive Survey
May 24, 2025



Graphs are a widely used paradigm for representing non-Euclidean data, with applications ranging from social network analysis to biomolecular prediction. Conventional graph learning approaches typically rely on fixed structural assumptions or fully observed data, limiting their effectiveness in more complex, noisy, or evolving settings. Consequently, real-world graph data often violates the assumptions of traditional graph learning methods, in particular, it leads to four fundamental challenges: (1) Incompleteness, real-world graphs have missing nodes, edges, or attributes; (2) Imbalance, the distribution of the labels of nodes or edges and their structures for real-world graphs are highly skewed; (3) Cross-domain Heterogeneity, graphs from different domains exhibit incompatible feature spaces or structural patterns; and (4) Dynamic Instability, graphs evolve over time in unpredictable ways. Recent advances in Large Language Models (LLMs) offer the potential to tackle these challenges by leveraging rich semantic reasoning and external knowledge. This survey provides a comprehensive review of how LLMs can be integrated with graph learning to address the aforementioned challenges. For each challenge, we review both traditional solutions and modern LLM-driven approaches, highlighting how LLMs contribute unique advantages. Finally, we discuss open research questions and promising future directions in this emerging interdisciplinary field. To support further exploration, we have curated a repository of recent advances on graph learning challenges: https://github.com/limengran98/Awesome-Literature-Graph-Learning-Challenges.
TAS-TsC: A Data-Driven Framework for Estimating Time of Arrival Using Temporal-Attribute-Spatial Tri-space Coordination of Truck Trajectories
Dec 02, 2024



Accurately estimating time of arrival (ETA) for trucks is crucial for optimizing transportation efficiency in logistics. GPS trajectory data offers valuable information for ETA, but challenges arise due to temporal sparsity, variable sequence lengths, and the interdependencies among multiple trucks. To address these issues, we propose the Temporal-Attribute-Spatial Tri-space Coordination (TAS-TsC) framework, which leverages three feature spaces-temporal, attribute, and spatial-to enhance ETA. Our framework consists of a Temporal Learning Module (TLM) using state space models to capture temporal dependencies, an Attribute Extraction Module (AEM) that transforms sequential features into structured attribute embeddings, and a Spatial Fusion Module (SFM) that models the interactions among multiple trajectories using graph representation learning.These modules collaboratively learn trajectory embeddings, which are then used by a Downstream Prediction Module (DPM) to estimate arrival times. We validate TAS-TsC on real truck trajectory datasets collected from Shenzhen, China, demonstrating its superior performance compared to existing methods.
YouTube AV 50K: An Annotated Corpus for Comments in Autonomous Vehicles
Oct 15, 2018
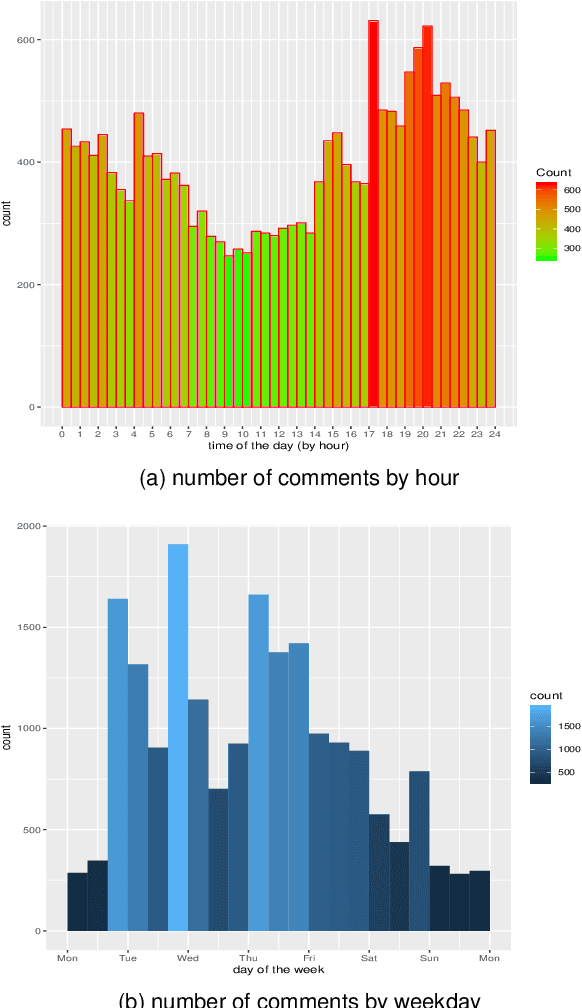
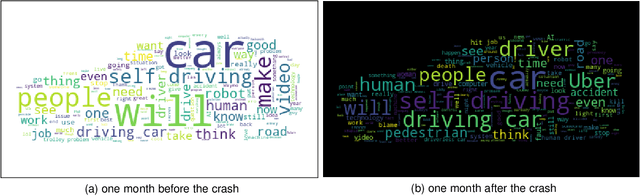
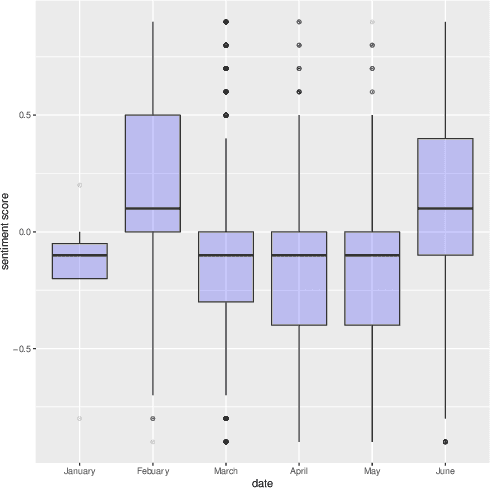
With one billion monthly viewers, and millions of users discussing and sharing opinions, comments below YouTube videos are rich sources of data for opinion mining and sentiment analysis. We introduce the YouTube AV 50K dataset, a freely-available collections of more than 50,000 YouTube comments and metadata below autonomous vehicle (AV)-related videos. We describe its creation process, its content and data format, and discuss its possible usages. Especially, we do a case study of the first self-driving car fatality to evaluate the dataset, and show how we can use this dataset to better understand public attitudes toward self-driving cars and public reactions to the accident. Future developments of the dataset are also discussed.