 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCPM-Explore: Realizing Long-Horizon Deep Exploration for Edge-Scale Agents
Feb 06, 2026While Large Language Model (LLM)-based agents have shown remarkable potential for solving complex tasks, existing systems remain heavily reliant on large-scale models, leaving the capabilities of edge-scale models largely underexplored. In this paper, we present the first systematic study on training agentic models at the 4B-parameter scale. We identify three primary bottlenecks hindering the performance of edge-scale models: catastrophic forgetting during Supervised Fine-Tuning (SFT), sensitivity to reward signal noise during Reinforcement Learning (RL), and reasoning degradation caused by redundant information in long-context scenarios. To address the issues, we propose AgentCPM-Explore, a compact 4B agent model with high knowledge density and strong exploration capability. We introduce a holistic training framework featuring parameter-space model fusion, reward signal denoising, and contextual information refinement. Through deep exploration, AgentCPM-Explore achieves state-of-the-art (SOTA) performance among 4B-class models, matches or surpasses 8B-class SOTA models on four benchmarks, and even outperforms larger-scale models such as Claude-4.5-Sonnet or DeepSeek-v3.2 in five benchmarks. Notably, AgentCPM-Explore achieves 97.09% accuracy on GAIA text-based tasks under pass@64. These results provide compelling evidence that the bottleneck for edge-scale models is not their inherent capability ceiling, but rather their inference stability. Based on our well-established training framework, AgentCPM-Explore effectively unlocks the significant, yet previously underestimated, potential of edge-scale models.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Cross-Task Experiential Learning on LLM-based Multi-Agent Collaboration
May 29, 2025Large Language Model-based multi-agent systems (MAS) have shown remarkable progress in solving complex tasks through collaborative reasoning and inter-agent critique. However, existing approaches typically treat each task in isolation, resulting in redundant computations and limited generalization across structurally similar tasks. To address this, we introduce multi-agent cross-task experiential learning (MAEL), a novel framework that endows LLM-driven agents with explicit cross-task learning and experience accumulation. We model the task-solving workflow on a graph-structured multi-agent collaboration network, where agents propagate information and coordinate via explicit connectivity. During the experiential learning phase, we quantify the quality for each step in the task-solving workflow and store the resulting rewards along with the corresponding inputs and outputs into each agent's individual experience pool. During inference, agents retrieve high-reward, task-relevant experiences as few-shot examples to enhance the effectiveness of each reasoning step, thereby enabling more accurate and efficient multi-agent collaboration. Experimental results on diverse datasets demonstrate that MAEL empowers agents to learn from prior task experiences effectively-achieving faster convergence and producing higher-quality solutions on current tasks.
Multi-Agent Collaboration via Evolving Orchestration
May 26, 2025



Large language models (LLMs) have achieved remarkable results across diverse downstream tasks, but their monolithic nature restricts scalability and efficiency in complex problem-solving. While recent research explores multi-agent collaboration among LLMs, most approaches rely on static organizational structures that struggle to adapt as task complexity and agent numbers grow, resulting in coordination overhead and inefficiencies. To this end, we propose a puppeteer-style paradigm for LLM-based multi-agent collaboration, where a centralized orchestrator ("puppeteer") dynamically directs agents ("puppets") in response to evolving task states. This orchestrator is trained via reinforcement learning to adaptively sequence and prioritize agents, enabling flexible and evolvable collective reasoning. Experiments on closed- and open-domain scenarios show that this method achieves superior performance with reduced computational costs. Analyses further reveal that the key improvements consistently stem from the emergence of more compact, cyclic reasoning structures under the orchestrator's evolution.
Autonomous Agents for Collaborative Task under Information Asymmetry
Jun 21, 2024Large Language Model Multi-Agent Systems (LLM-MAS) have achieved great progress in solving complex tasks. It performs communication among agents within the system to collaboratively solve tasks, under the premise of shared information. However, when agents' communication is leveraged to enhance human cooperation, a new challenge arises due to information asymmetry, since each agent can only access the information of its human user. Previous MAS struggle to complete tasks under this condition. To address this, we propose a new MAS paradigm termed iAgents, which denotes Informative Multi-Agent Systems. In iAgents, the human social network is mirrored in the agent network, where agents proactively exchange human information necessary for task resolution, thereby overcoming information asymmetry. iAgents employs a novel agent reasoning mechanism, InfoNav, to navigate agents' communication towards effective information exchange. Together with InfoNav, iAgents organizes human information in a mixed memory to provide agents with accurate and comprehensive information for exchange. Additionally, we introduce InformativeBench, the first benchmark tailored for evaluating LLM agents' task-solving ability under information asymmetry. Experimental results show that iAgents can collaborate within a social network of 140 individuals and 588 relationships, autonomously communicate over 30 turns, and retrieve information from nearly 70,000 messages to complete tasks within 3 minutes.
Multi-Agent Software Development through Cross-Team Collaboration
Jun 13, 2024



The latest breakthroughs in Large Language Models (LLMs), eg., ChatDev, have catalyzed profound transformations, particularly through multi-agent collaboration for software development. LLM agents can collaborate in teams like humans, and follow the waterfall model to sequentially work on requirements analysis, development, review, testing, and other phases to perform autonomous software generation. However, for an agent team, each phase in a single development process yields only one possible outcome. This results in the completion of only one development chain, thereby losing the opportunity to explore multiple potential decision paths within the solution space. Consequently, this may lead to obtaining suboptimal results. To address this challenge, we introduce Cross-Team Collaboration (CTC), a scalable multi-team framework that enables orchestrated teams to jointly propose various decisions and communicate with their insights in a cross-team collaboration environment for superior content generation. Experimental results in software development reveal a notable increase in quality compared to state-of-the-art baselines, underscoring the efficacy of our framework. The significant improvements in story generation demonstrate the promising generalization ability of our framework across various domains. We anticipate that our work will guide LLM agents towards a cross-team paradigm and contribute to their significant growth in but not limited to software development. The code and data will be available at https://github.com/OpenBMB/ChatDev.
Scaling Large-Language-Model-based Multi-Agent Collaboration
Jun 11, 2024



Pioneering advancements in large language model-powered agents have underscored the design pattern of multi-agent collaboration, demonstrating that collective intelligence can surpass the capabilities of each individual. Inspired by the neural scaling law, which posits that increasing neurons leads to emergent abilities, this study investigates whether a similar principle applies to increasing agents in multi-agent collaboration. Technically, we propose multi-agent collaboration networks (MacNet), which utilize directed acyclic graphs to organize agents and streamline their interactive reasoning via topological ordering, with solutions derived from their dialogues. Extensive experiments show that MacNet consistently outperforms baseline models, enabling effective agent collaboration across various network topologies and supporting cooperation among more than a thousand agents. Notably, we observed a small-world collaboration phenomenon, where topologies resembling small-world properties achieved superior performance. Additionally, we identified a collaborative scaling law, indicating that normalized solution quality follows a logistic growth pattern as scaling agents, with collaborative emergence occurring much earlier than previously observed instances of neural emergence. The code and data will be available at https://github.com/OpenBMB/ChatDev.
Iterative Experience Refinement of Software-Developing Agents
May 07, 2024



Autonomous agents powered by large language models (LLMs) show significant potential for achieving high autonomy in various scenarios such as software development. Recent research has shown that LLM agents can leverage past experiences to reduce errors and enhance efficiency. However, the static experience paradigm, reliant on a fixed collection of past experiences acquired heuristically, lacks iterative refinement and thus hampers agents' adaptability. In this paper, we introduce the Iterative Experience Refinement framework, enabling LLM agents to refine experiences iteratively during task execution. We propose two fundamental patterns: the successive pattern, refining based on nearest experiences within a task batch, and the cumulative pattern, acquiring experiences across all previous task batches. Augmented with our heuristic experience elimination, the method prioritizes high-quality and frequently-used experiences, effectively managing the experience space and enhancing efficiency. Extensive experiments show that while the successive pattern may yield superior results, the cumulative pattern provides more stable performance. Moreover, experience elimination facilitates achieving better performance using just 11.54% of a high-quality subset.
IoU-uniform R-CNN: Breaking Through the Limitations of RPN
Dec 11, 2019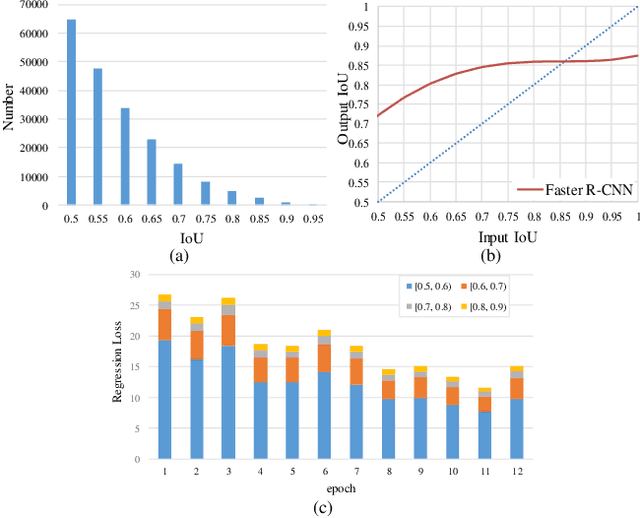
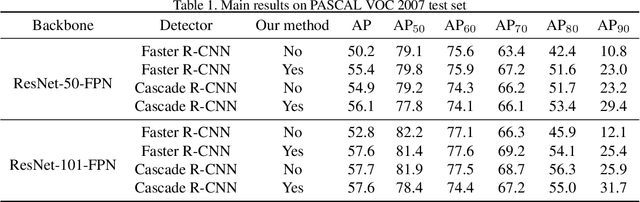
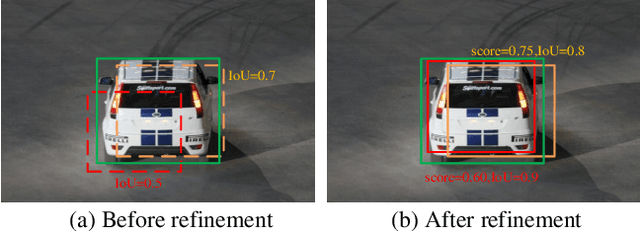
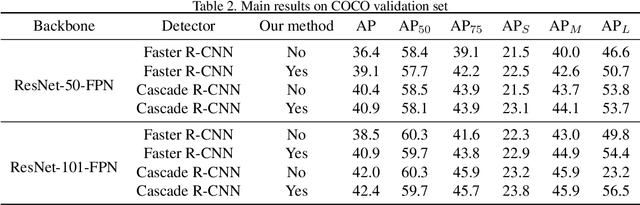
Region Proposal Network (RPN) is the cornerstone of two-stage object detectors, it generates a sparse set of object proposals and alleviates the extrem foregroundbackground class imbalance problem during training. However, we find that the potential of the detector has not been fully exploited due to the IoU distribution imbalance and inadequate quantity of the training samples generated by RPN. With the increasing intersection over union (IoU), the exponentially smaller numbers of positive samples would lead to the distribution skewed towards lower IoUs, which hinders the optimization of detector at high IoU levels. In this paper, to break through the limitations of RPN, we propose IoU-Uniform R-CNN, a simple but effective method that directly generates training samples with uniform IoU distribution for the regression branch as well as the IoU prediction branch. Besides, we improve the performance of IoU prediction branch by eliminating the feature offsets of RoIs at inference, which helps the NMS procedure by preserving accurately localized bounding box. Extensive experiments on the PASCAL VOC and MS COCO dataset show the effectiveness of our method, as well as its compatibility and adaptivity to many object detection architectures. The code is made publicly available at https://github.com/zl1994/IoU-Uniform-R-CNN,
Localization-aware Channel Pruning for Object Detection
Nov 21, 2019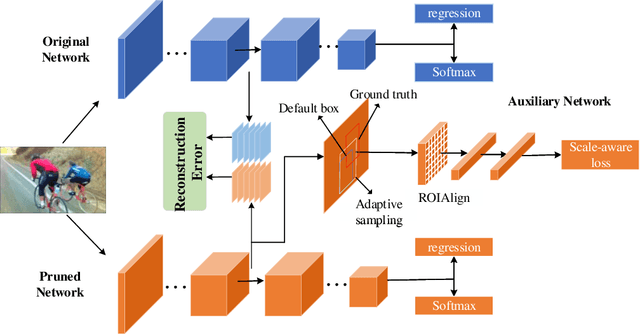
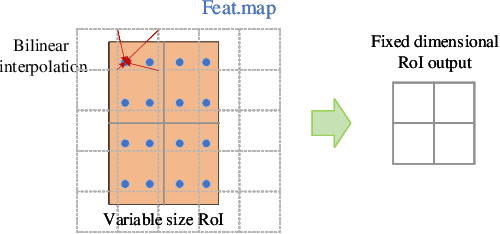
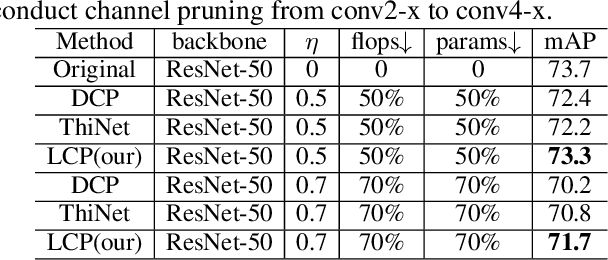
Channel pruning is one of the important methods for deep model compression. Most of existing pruning methods mainly focus on classification. Few of them conduct systematic research on object detection. However, object detection is different from classification, which requires not only semantic information but also localization information. In this paper, based on DCP \cite{zhuang2018discrimination} which is state-of-the-art pruning method for classification, we propose a localization-aware auxiliary network to find out the channels with key information for classification and regression so that we can conduct channel pruning directly for object detection, which saves lots of time and computing resources. In order to capture the localization information, we first design the auxiliary network with a contextual ROIAlign layer which can obtain precise localization information of the default boxes by pixel alignment and enlarges the receptive fields of the default boxes when pruning shallow layers. Then, we construct a loss function for object detection task which tends to keep the channels that contain the key information for classification and regression. Extensive experiments demonstrate the effectiveness of our method. On MS COCO, we prune 70\% parameters of the SSD based on ResNet-50 with modest accuracy drop, which outperforms the-state-of-art method.