 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryCard: Topic-Aware Multi-Modal Clue Compression for Long-Video Question Answering
Jun 04, 2026Long-video question answering remains challenging for Vision-Language Models (VLMs), as answer-relevant evidence is often sparse, transient, and temporally dispersed across lengthy video contexts. Existing frame-centric approaches improve efficiency through uniform sampling, query-aware frame selection, visual-token compression, and adaptive resolution strategies. However, they still rely on isolated and fragmented frames as the fundamental evidence units, limiting VLMs' ability to effectively capture coherent event-level semantics. To address this limitation, we propose MemoryCard, a video-memory-based augmentation framework that organizes long videos into self-contained Memory Cards. Specifically, MemoryCard first performs a self-reading process over videos and aligned utterances to segment the video into semantically coherent units, each corresponding to a distinct topic or event. For each unit, it generates an event-level video gist and selects representative visual moments, which are then rendered into unified Memory Cards for retrieval and question answering. Experimental results demonstrate that MemoryCard consistently improves long-video QA performance under comparable visual-token budgets, achieving up to a 21.8% relative improvement in accuracy. All code is available at https://github.com/NEUIR/MemoryCard.
ReAlign: Optimizing the Visual Document Retriever with Reasoning-Guided Fine-Grained Alignment
Apr 08, 2026Visual document retrieval aims to retrieve a set of document pages relevant to a query from visually rich collections. Existing methods often employ Vision-Language Models (VLMs) to encode queries and visual pages into a shared embedding space, which is then optimized via contrastive training. However, during visual document representation, localized evidence is usually scattered across complex document layouts, making it difficult for retrieval models to capture crucial cues for effective embedding learning. In this paper, we propose Reasoning-Guided Alignment (ReAlign), a method that enhances visual document retrieval by leveraging the reasoning capability of VLMs to provide fine-grained visual document descriptions as supervision signals for training. Specifically, ReAlign employs a superior VLM to identify query-related regions on a page and then generates a query-aware description grounding the cropped visual regions. The retriever is then trained using these region-focused descriptions to align the semantics between queries and visual documents by encouraging the document ranking distribution induced by the region-focused descriptions to match that induced by the original query. Experiments on diverse visually rich document retrieval benchmarks demonstrate that ReAlign consistently improves visual document retrieval performance on both in-domain and out-of-domain datasets, achieving up to 2% relative improvements. Moreover, the advantages of ReAlign generalize across different VLM backbones by guiding models to better focus their attention on critical visual cues for document representation. All code and datasets are available at https://github.com/NEUIR/ReAlign.
DIAL-KG: Schema-Free Incremental Knowledge Graph Construction via Dynamic Schema Induction and Evolution-Intent Assessment
Mar 20, 2026Knowledge Graphs (KGs) are foundational to applications such as search, question answering, and recommendation. Conventional knowledge graph construction methods are predominantly static, rely ing on a single-step construction from a fixed corpus with a prede f ined schema. However, such methods are suboptimal for real-world sce narios where data arrives dynamically, as incorporating new informa tion requires complete and computationally expensive graph reconstruc tions. Furthermore, predefined schemas hinder the flexibility of knowl edge graph construction. To address these limitations, we introduce DIAL KG, a closed-loop framework for incremental KG construction orches trated by a Meta-Knowledge Base (MKB). The framework oper ates in a three-stage cycle: (i) Dual-Track Extraction, which ensures knowledge completeness by defaulting to triple generation and switching to event extraction for complex knowledge; (ii) Governance Adjudica tion, which ensures the fidelity and currency of extracted facts to prevent hallucinations and knowledge staleness; and (iii) Schema Evolution, in which new schemas are induced from validated knowledge to guide subsequent construction cycles, and knowledge from the current round is incrementally applied to the existing KG. Extensive experiments demon strate that our framework achieves state-of-the-art (SOTA) performance in the quality of both the constructed graph and the induced schemas.
Tau-BNO: Brain Neural Operator for Tau Transport Model
Mar 09, 2026Mechanistic modeling provides a biophysically grounded framework for studying the spread of pathological tau protein in tauopathies like Alzheimer's disease. Existing approaches typically model tau propagation as a diffusive process on the brain's structural connectome, reproducing macroscopic patterns but neglecting microscale cellular transport and reaction mechanisms. The Network Transport Model (NTM) was introduced to fill this gap, explaining how region-level progression of tau emerges from microscale biophysical processes. However, the NTM faces a common challenge for complex models defined by large systems of partial differential equations: the inability to perform parameter inference and mechanistic discovery due to high computational burden and slow model simulations. To overcome this barrier, we propose Tau-BNO, a Brain Neural Operator surrogate framework for rapidly approximating NTM dynamics that captures both intra-regional reaction kinetics and inter-regional network transport. Tau-BNO combines a function operator that encodes kinetic parameters with a query operator that preserves initial state information, while approximating anisotropic transport through a spectral kernel that retains directionality. Empirical evaluations demonstrate high predictive accuracy ($R^2\approx$ 0.98) across diverse biophysical regimes and an 89\% performance improvement over state-of-the-art sequence models like Transformers and Mamba, which lack inherent structural priors. By reducing simulation time from hours to seconds, we show that the surrogate model is capable of producing new insights and generating new hypotheses. This framework is readily extensible to a broader class of connectome-based biophysical models, showcasing the transformative value of deep learning surrogates to accelerate analysis of large-scale, computationally intensive dynamical systems.
UNIKIE-BENCH: Benchmarking Large Multimodal Models for Key Information Extraction in Visual Documents
Feb 03, 2026Key Information Extraction (KIE) from real-world documents remains challenging due to substantial variations in layout structures, visual quality, and task-specific information requirements. Recent Large Multimodal Models (LMMs) have shown promising potential for performing end-to-end KIE directly from document images. To enable a comprehensive and systematic evaluation across realistic and diverse application scenarios, we introduce UNIKIE-BENCH, a unified benchmark designed to rigorously evaluate the KIE capabilities of LMMs. UNIKIE-BENCH consists of two complementary tracks: a constrained-category KIE track with scenario-predefined schemas that reflect practical application needs, and an open-category KIE track that extracts any key information that is explicitly present in the document. Experiments on 15 state-of-the-art LMMs reveal substantial performance degradation under diverse schema definitions, long-tail key fields, and complex layouts, along with pronounced performance disparities across different document types and scenarios. These findings underscore persistent challenges in grounding accuracy and layout-aware reasoning for LMM-based KIE. All codes and datasets are available at https://github.com/NEUIR/UNIKIE-BENCH.
Teaching LLMs to Learn Tool Trialing and Execution through Environment Interaction
Jan 19, 2026Equipping Large Language Models (LLMs) with external tools enables them to solve complex real-world problems. However, the robustness of existing methods remains a critical challenge when confronting novel or evolving tools. Existing trajectory-centric paradigms primarily rely on memorizing static solution paths during training, which limits the ability of LLMs to generalize tool usage to newly introduced or previously unseen tools. In this paper, we propose ToolMaster, a framework that shifts tool use from imitating golden tool-calling trajectories to actively learning tool usage through interaction with the environment. To optimize LLMs for tool planning and invocation, ToolMaster adopts a trial-and-execution paradigm, which trains LLMs to first imitate teacher-generated trajectories containing explicit tool trials and self-correction, followed by reinforcement learning to coordinate the trial and execution phases jointly. This process enables agents to autonomously explore correct tool usage by actively interacting with environments and forming experiential knowledge that benefits tool execution. Experimental results demonstrate that ToolMaster significantly outperforms existing baselines in terms of generalization and robustness across unseen or unfamiliar tools. All code and data are available at https://github.com/NEUIR/ToolMaster.
Long-Chain Reasoning Distillation via Adaptive Prefix Alignment
Jan 15, 2026Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, particularly in solving complex mathematical problems. Recent studies show that distilling long reasoning trajectories can effectively enhance the reasoning performance of small-scale student models. However, teacher-generated reasoning trajectories are often excessively long and structurally complex, making them difficult for student models to learn. This mismatch leads to a gap between the provided supervision signal and the learning capacity of the student model. To address this challenge, we propose Prefix-ALIGNment distillation (P-ALIGN), a framework that fully exploits teacher CoTs for distillation through adaptive prefix alignment. Specifically, P-ALIGN adaptively truncates teacher-generated reasoning trajectories by determining whether the remaining suffix is concise and sufficient to guide the student model. Then, P-ALIGN leverages the teacher-generated prefix to supervise the student model, encouraging effective prefix alignment. Experiments on multiple mathematical reasoning benchmarks demonstrate that P-ALIGN outperforms all baselines by over 3%. Further analysis indicates that the prefixes constructed by P-ALIGN provide more effective supervision signals, while avoiding the negative impact of redundant and uncertain reasoning components. All code is available at https://github.com/NEUIR/P-ALIGN.
Structured Knowledge Representation through Contextual Pages for Retrieval-Augmented Generation
Jan 14, 2026Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge. Recently, some works have incorporated iterative knowledge accumulation processes into RAG models to progressively accumulate and refine query-related knowledge, thereby constructing more comprehensive knowledge representations. However, these iterative processes often lack a coherent organizational structure, which limits the construction of more comprehensive and cohesive knowledge representations. To address this, we propose PAGER, a page-driven autonomous knowledge representation framework for RAG. PAGER first prompts an LLM to construct a structured cognitive outline for a given question, which consists of multiple slots representing a distinct knowledge aspect. Then, PAGER iteratively retrieves and refines relevant documents to populate each slot, ultimately constructing a coherent page that serves as contextual input for guiding answer generation. Experiments on multiple knowledge-intensive benchmarks and backbone models show that PAGER consistently outperforms all RAG baselines. Further analyses demonstrate that PAGER constructs higher-quality and information-dense knowledge representations, better mitigates knowledge conflicts, and enables LLMs to leverage external knowledge more effectively. All code is available at https://github.com/OpenBMB/PAGER.
Revealing the Attention Floating Mechanism in Masked Diffusion Models
Jan 12, 2026Masked diffusion models (MDMs), which leverage bidirectional attention and a denoising process, are narrowing the performance gap with autoregressive models (ARMs). However, their internal attention mechanisms remain under-explored. This paper investigates the attention behaviors in MDMs, revealing the phenomenon of Attention Floating. Unlike ARMs, where attention converges to a fixed sink, MDMs exhibit dynamic, dispersed attention anchors that shift across denoising steps and layers. Further analysis reveals its Shallow Structure-Aware, Deep Content-Focused attention mechanism: shallow layers utilize floating tokens to build a global structural framework, while deeper layers allocate more capability toward capturing semantic content. Empirically, this distinctive attention pattern provides a mechanistic explanation for the strong in-context learning capabilities of MDMs, allowing them to double the performance compared to ARMs in knowledge-intensive tasks. All codes and datasets are available at https://github.com/NEUIR/Attention-Floating.
MSC-180: A Benchmark for Automated Formal Theorem Proving from Mathematical Subject Classification
Dec 20, 2025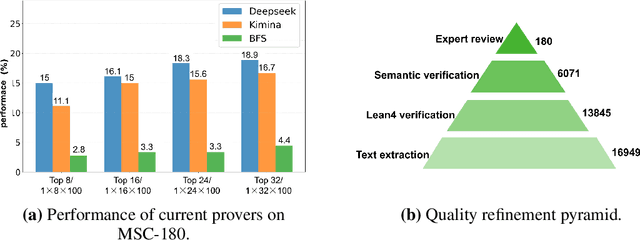



Automated Theorem Proving (ATP) represents a core research direction in artificial intelligence for achieving formal reasoning and verification, playing a significant role in advancing machine intelligence. However, current large language model (LLM)-based theorem provers suffer from limitations such as restricted domain coverage and weak generalization in mathematical reasoning. To address these issues, we propose MSC-180, a benchmark for evaluation based on the MSC2020 mathematical subject classification. It comprises 180 formal verification problems, 3 advanced problems from each of 60 mathematical branches, spanning from undergraduate to graduate levels. Each problem has undergone multiple rounds of verification and refinement by domain experts to ensure formal accuracy. Evaluations of state-of-the-art LLM-based theorem provers under the pass@32 setting reveal that the best model achieves only an 18.89% overall pass rate, with prominent issues including significant domain bias (maximum domain coverage 41.7%) and a difficulty gap (significantly lower pass rates on graduate-level problems). To further quantify performance variability across mathematical domains, we introduce the coefficient of variation (CV) as an evaluation metric. The observed CV values are 4-6 times higher than the statistical high-variability threshold, indicating that the models still rely on pattern matching from training corpora rather than possessing transferable reasoning mechanisms and systematic generalization capabilities. MSC-180, together with its multi-dimensional evaluation framework, provides a discriminative and systematic benchmark for driving the development of next-generation AI systems with genuine mathematical reasoning abilities.