 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-Bench: Benchmarking Self-Evolution with Knowledge Internalization
Feb 04, 2026True self-evolution requires agents to act as lifelong learners that internalize novel experiences to solve future problems. However, rigorously measuring this foundational capability is hindered by two obstacles: the entanglement of prior knowledge, where ``new'' knowledge may appear in pre-training data, and the entanglement of reasoning complexity, where failures may stem from problem difficulty rather than an inability to recall learned knowledge. We introduce SE-Bench, a diagnostic environment that obfuscates the NumPy library and its API doc into a pseudo-novel package with randomized identifiers. Agents are trained to internalize this package and evaluated on simple coding tasks without access to documentation, yielding a clean setting where tasks are trivial with the new API doc but impossible for base models without it. Our investigation reveals three insights: (1) the Open-Book Paradox, where training with reference documentation inhibits retention, requiring "Closed-Book Training" to force knowledge compression into weights; (2) the RL Gap, where standard RL fails to internalize new knowledge completely due to PPO clipping and negative gradients; and (3) the viability of Self-Play for internalization, proving models can learn from self-generated, noisy tasks when coupled with SFT, but not RL. Overall, SE-Bench establishes a rigorous diagnostic platform for self-evolution with knowledge internalization. Our code and dataset can be found at https://github.com/thunlp/SE-Bench.
The Overthinker's DIET: Cutting Token Calories with DIfficulty-AwarE Training
May 25, 2025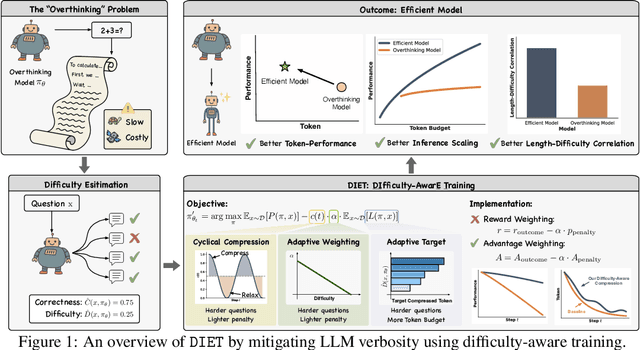



Recent large language models (LLMs) exhibit impressive reasoning but often over-think, generating excessively long responses that hinder efficiency. We introduce DIET ( DIfficulty-AwarE Training), a framework that systematically cuts these "token calories" by integrating on-the-fly problem difficulty into the reinforcement learning (RL) process. DIET dynamically adapts token compression strategies by modulating token penalty strength and conditioning target lengths on estimated task difficulty, to optimize the performance-efficiency trade-off. We also theoretically analyze the pitfalls of naive reward weighting in group-normalized RL algorithms like GRPO, and propose Advantage Weighting technique, which enables stable and effective implementation of these difficulty-aware objectives. Experimental results demonstrate that DIET significantly reduces token counts while simultaneously improving reasoning performance. Beyond raw token reduction, we show two crucial benefits largely overlooked by prior work: (1) DIET leads to superior inference scaling. By maintaining high per-sample quality with fewer tokens, it enables better scaling performance via majority voting with more samples under fixed computational budgets, an area where other methods falter. (2) DIET enhances the natural positive correlation between response length and problem difficulty, ensuring verbosity is appropriately allocated, unlike many existing compression methods that disrupt this relationship. Our analyses provide a principled and effective framework for developing more efficient, practical, and high-performing LLMs.
On the Resilience of Multi-Agent Systems with Malicious Agents
Aug 02, 2024Multi-agent systems, powered by large language models, have shown great abilities across various tasks due to the collaboration of expert agents, each focusing on a specific domain. However, when agents are deployed separately, there is a risk that malicious users may introduce malicious agents who generate incorrect or irrelevant results that are too stealthy to be identified by other non-specialized agents. Therefore, this paper investigates two essential questions: (1) What is the resilience of various multi-agent system structures (e.g., A$\rightarrow$B$\rightarrow$C, A$\leftrightarrow$B$\leftrightarrow$C) under malicious agents, on different downstream tasks? (2) How can we increase system resilience to defend against malicious agents? To simulate malicious agents, we devise two methods, AutoTransform and AutoInject, to transform any agent into a malicious one while preserving its functional integrity. We run comprehensive experiments on four downstream multi-agent systems tasks, namely code generation, math problems, translation, and text evaluation. Results suggest that the "hierarchical" multi-agent structure, i.e., A$\rightarrow$(B$\leftrightarrow$C), exhibits superior resilience with the lowest performance drop of $23.6\%$, compared to $46.4\%$ and $49.8\%$ of other two structures. Additionally, we show the promise of improving multi-agent system resilience by demonstrating that two defense methods, introducing an additional agent to review and correct messages or mechanisms for each agent to challenge others' outputs, can enhance system resilience. Our code and data are available at https://github.com/CUHK-ARISE/MAS-Resilience.