 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC-OCR V2: Benchmarking Large Multimodal Models for Literacy in Real-world Document Processing
May 05, 2026Large Multimodal Models (LMMs) have recently shown strong performance on Optical Character Recognition (OCR) tasks, demonstrating their promising capability in document literacy. However, their effectiveness in real-world applications remains underexplored, as existing benchmarks adopt task scopes misaligned with practical applications and assume homogeneous acquisition conditions. To address this gap, we introduce CC-OCR V2, a comprehensive and challenging OCR benchmark tailored to real-world document processing. CC-OCR V2 focuses on practical enterprise document processing tasks and incorporates hard and corner cases that are critical yet underrepresented in prior benchmarks, covering 5 major OCR-centric tracks: text recognition, document parsing, document grounding, key information extraction, and document question answering, comprising 7,093 high-difficulty samples. Extensive experiments on 14 advanced LMMs reveal that current models fall short of real-world application requirements. Even state-of-the-art LMMs exhibit substantial performance degradation across diverse tasks and scenarios. These findings reveal a significant gap between performance on current benchmarks and effectiveness in real-world applications. We release the full dataset and evaluation toolkit at https://github.com/eioss/CC-OCR-V2.
ReCUT: Balancing Reasoning Length and Accuracy in LLMs via Stepwise Trails and Preference Optimization
Jun 12, 2025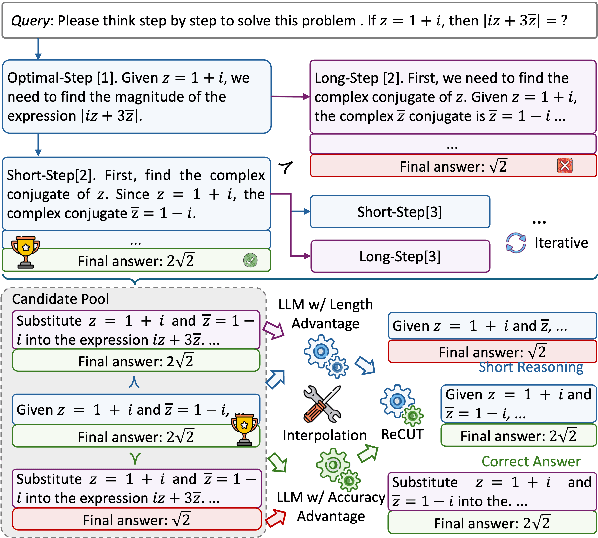
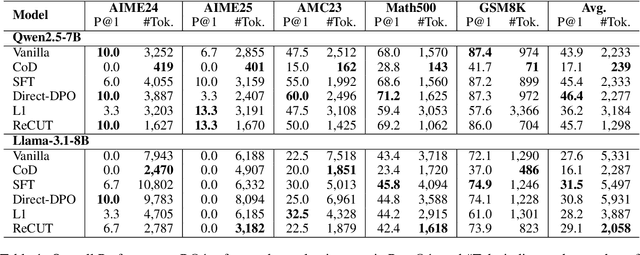
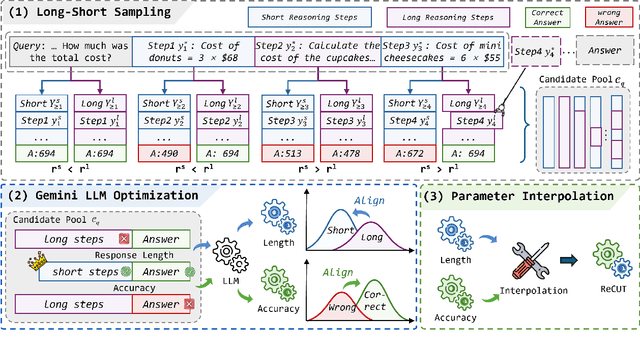
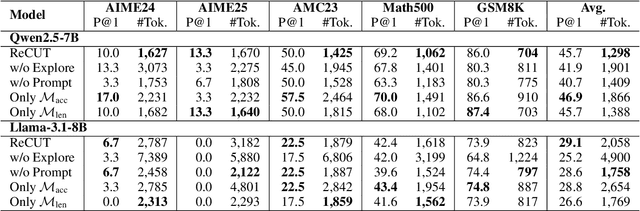
Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of Large Language Models (LLMs). However, these methods often suffer from overthinking, leading to unnecessarily lengthy or redundant reasoning traces. Existing approaches attempt to mitigate this issue through curating multiple reasoning chains for training LLMs, but their effectiveness is often constrained by the quality of the generated data and prone to overfitting. To address the challenge, we propose Reasoning Compression ThroUgh Stepwise Trials (ReCUT), a novel method aimed at balancing the accuracy and length of reasoning trajectory. Specifically, ReCUT employs a stepwise exploration mechanism and a long-short switched sampling strategy, enabling LLMs to incrementally generate diverse reasoning paths. These paths are evaluated and used to construct preference pairs to train two specialized models (Gemini LLMs)-one optimized for reasoning accuracy, the other for shorter reasoning. A final integrated model is obtained by interpolating the parameters of these two models. Experimental results across multiple math reasoning datasets and backbone models demonstrate that ReCUT significantly reduces reasoning lengths by approximately 30-50%, while maintaining or improving reasoning accuracy compared to various baselines. All codes and data will be released via https://github.com/NEUIR/ReCUT.
Learning to Route Queries Across Knowledge Bases for Step-wise Retrieval-Augmented Reasoning
May 28, 2025



Multimodal Retrieval-Augmented Generation (MRAG) has shown promise in mitigating hallucinations in Multimodal Large Language Models (MLLMs) by incorporating external knowledge during generation. Existing MRAG methods typically adopt a static retrieval pipeline that fetches relevant information from multiple Knowledge Bases (KBs), followed by a refinement step. However, these approaches overlook the reasoning and planning capabilities of MLLMs to dynamically determine how to interact with different KBs during the reasoning process. To address this limitation, we propose R1-Router, a novel MRAG framework that learns to decide when and where to retrieve knowledge based on the evolving reasoning state. Specifically, R1-Router can generate follow-up queries according to the current reasoning step, routing these intermediate queries to the most suitable KB, and integrating external knowledge into a coherent reasoning trajectory to answer the original query. Furthermore, we introduce Step-wise Group Relative Policy Optimization (Step-GRPO), a tailored reinforcement learning algorithm that assigns step-specific rewards to optimize the reasoning behavior of MLLMs. Experimental results on various open-domain QA benchmarks across multiple modalities demonstrate that R1-Router outperforms baseline models by over 7%. Further analysis shows that R1-Router can adaptively and effectively leverage diverse KBs, reducing unnecessary retrievals and improving both efficiency and accuracy.
Towards Live Video Analytics with On-Drone Deeper-yet-Compatible Compression
Nov 10, 2021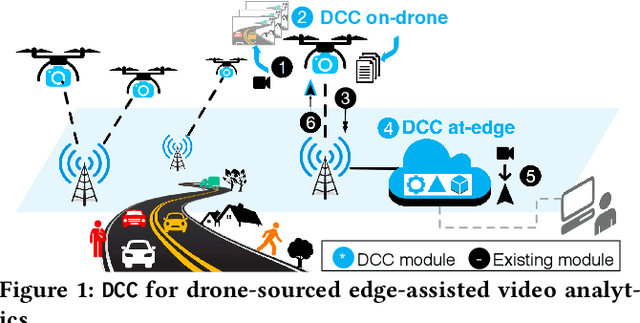

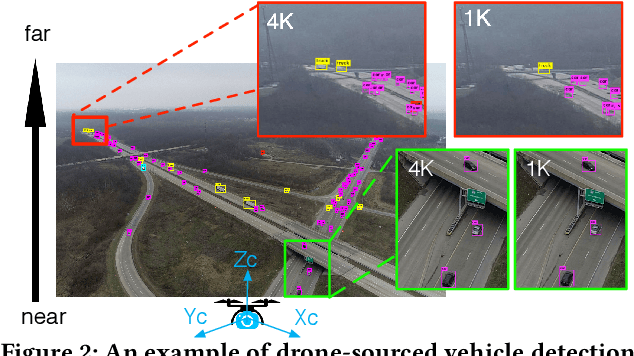
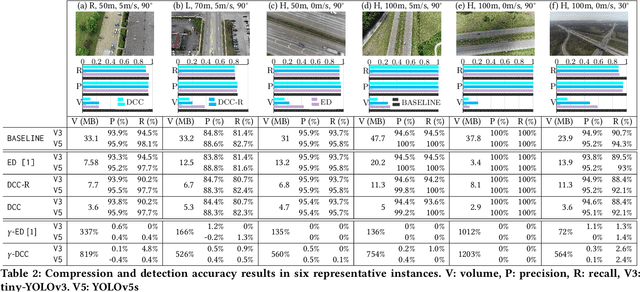
In this work, we present DCC(Deeper-yet-Compatible Compression), one enabling technique for real-time drone-sourced edge-assisted video analytics built on top of the existing codec. DCC tackles an important technical problem to compress streamed video from the drone to the edge without scarifying accuracy and timeliness of video analytical tasks performed at the edge. DCC is inspired by the fact that not every bit in streamed video is equally valuable to video analytics, which opens new compression room over the conventional analytics-oblivious video codec technology. We exploit drone-specific context and intermediate hints from object detection to pursue adaptive fidelity needed to retain analytical quality. We have prototyped DCC in one showcase application of vehicle detection and validated its efficiency in representative scenarios. DCC has reduced transmission volume by 9.5-fold over the baseline approach and 19-683% over the state-of-the-art with comparable detection accuracy.