 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgriWorld:A World Tools Protocol Framework for Verifiable Agricultural Reasoning with Code-Executing LLM Agents
Feb 17, 2026Foundation models for agriculture are increasingly trained on massive spatiotemporal data (e.g., multi-spectral remote sensing, soil grids, and field-level management logs) and achieve strong performance on forecasting and monitoring. However, these models lack language-based reasoning and interactive capabilities, limiting their usefulness in real-world agronomic workflows. Meanwhile, large language models (LLMs) excel at interpreting and generating text, but cannot directly reason over high-dimensional, heterogeneous agricultural datasets. We bridge this gap with an agentic framework for agricultural science. It provides a Python execution environment, AgriWorld, exposing unified tools for geospatial queries over field parcels, remote-sensing time-series analytics, crop growth simulation, and task-specific predictors (e.g., yield, stress, and disease risk). On top of this environment, we design a multi-turn LLM agent, Agro-Reflective, that iteratively writes code, observes execution results, and refines its analysis via an execute-observe-refine loop. We introduce AgroBench, with scalable data generation for diverse agricultural QA spanning lookups, forecasting, anomaly detection, and counterfactual "what-if" analysis. Experiments outperform text-only and direct tool-use baselines, validating execution-driven reflection for reliable agricultural reasoning.
DeformCL: Learning Deformable Centerline Representation for Vessel Extraction in 3D Medical Image
Jun 06, 2025In the field of 3D medical imaging, accurately extracting and representing the blood vessels with curvilinear structures holds paramount importance for clinical diagnosis. Previous methods have commonly relied on discrete representation like mask, often resulting in local fractures or scattered fragments due to the inherent limitations of the per-pixel classification paradigm. In this work, we introduce DeformCL, a new continuous representation based on Deformable Centerlines, where centerline points act as nodes connected by edges that capture spatial relationships. Compared with previous representations, DeformCL offers three key advantages: natural connectivity, noise robustness, and interaction facility. We present a comprehensive training pipeline structured in a cascaded manner to fully exploit these favorable properties of DeformCL. Extensive experiments on four 3D vessel segmentation datasets demonstrate the effectiveness and superiority of our method. Furthermore, the visualization of curved planar reformation images validates the clinical significance of the proposed framework. We release the code in https://github.com/barry664/DeformCL
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
Dec 13, 2024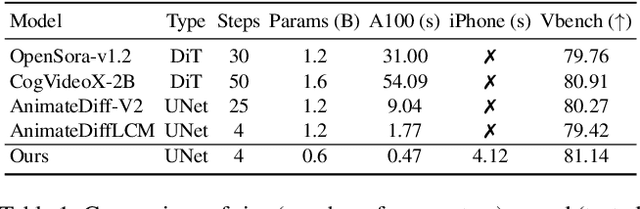
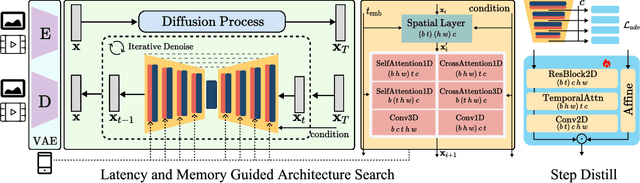
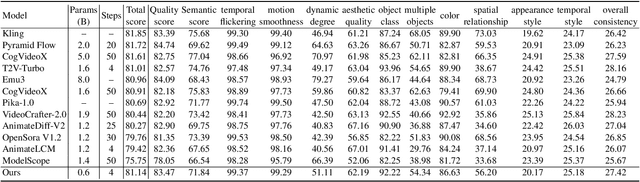
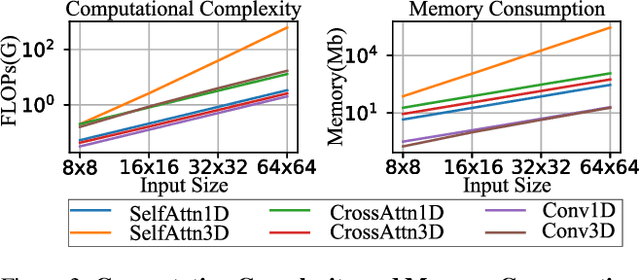
We have witnessed the unprecedented success of diffusion-based video generation over the past year. Recently proposed models from the community have wielded the power to generate cinematic and high-resolution videos with smooth motions from arbitrary input prompts. However, as a supertask of image generation, video generation models require more computation and are thus hosted mostly on cloud servers, limiting broader adoption among content creators. In this work, we propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. From the network architecture scope, we initialize from a compact image backbone and search out the design and arrangement of temporal layers to maximize hardware efficiency. In addition, we propose a dedicated adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. Compared to server-side models that take minutes on powerful GPUs to generate a single video, we accelerate the generation by magnitudes while delivering on-par quality.
Enhancing Monotonic Modeling with Spatio-Temporal Adaptive Awareness in Diverse Marketing
Jun 20, 2024In the mobile internet era, the Online Food Ordering Service (OFOS) emerges as an integral component of inclusive finance owing to the convenience it brings to people. OFOS platforms offer dynamic allocation incentives to users and merchants through diverse marketing campaigns to encourage payments while maintaining the platforms' budget efficiency. Despite significant progress, the marketing domain continues to face two primary challenges: (i) how to allocate a limited budget with greater efficiency, demanding precision in predicting users' monotonic response (i.e. sensitivity) to incentives, and (ii) ensuring spatio-temporal adaptability and robustness in diverse marketing campaigns across different times and locations. To address these issues, we propose a Constrained Monotonic Adaptive Network (CoMAN) method for spatio-temporal perception within marketing pricing. Specifically, we capture spatio-temporal preferences within attribute features through two foundational spatio-temporal perception modules. To further enhance catching the user sensitivity differentials to incentives across varied times and locations, we design modules for learning spatio-temporal convexity and concavity as well as for expressing sensitivity functions. CoMAN can achieve a more efficient allocation of incentive investments during pricing, thus increasing the conversion rate and orders while maintaining budget efficiency. Extensive offline and online experimental results within our diverse marketing campaigns demonstrate the effectiveness of the proposed approach while outperforming the monotonic state-of-the-art method.
SF-V: Single Forward Video Generation Model
Jun 06, 2024Diffusion-based video generation models have demonstrated remarkable success in obtaining high-fidelity videos through the iterative denoising process. However, these models require multiple denoising steps during sampling, resulting in high computational costs. In this work, we propose a novel approach to obtain single-step video generation models by leveraging adversarial training to fine-tune pre-trained video diffusion models. We show that, through the adversarial training, the multi-steps video diffusion model, i.e., Stable Video Diffusion (SVD), can be trained to perform single forward pass to synthesize high-quality videos, capturing both temporal and spatial dependencies in the video data. Extensive experiments demonstrate that our method achieves competitive generation quality of synthesized videos with significantly reduced computational overhead for the denoising process (i.e., around $23\times$ speedup compared with SVD and $6\times$ speedup compared with existing works, with even better generation quality), paving the way for real-time video synthesis and editing. More visualization results are made publicly available at https://snap-research.github.io/SF-V.
AVID: Any-Length Video Inpainting with Diffusion Model
Dec 06, 2023



Recent advances in diffusion models have successfully enabled text-guided image inpainting. While it seems straightforward to extend such editing capability into video domain, there has been fewer works regarding text-guided video inpainting. Given a video, a masked region at its initial frame, and an editing prompt, it requires a model to do infilling at each frame following the editing guidance while keeping the out-of-mask region intact. There are three main challenges in text-guided video inpainting: ($i$) temporal consistency of the edited video, ($ii$) supporting different inpainting types at different structural fidelity level, and ($iii$) dealing with variable video length. To address these challenges, we introduce Any-Length Video Inpainting with Diffusion Model, dubbed as AVID. At its core, our model is equipped with effective motion modules and adjustable structure guidance, for fixed-length video inpainting. Building on top of that, we propose a novel Temporal MultiDiffusion sampling pipeline with an middle-frame attention guidance mechanism, facilitating the generation of videos with any desired duration. Our comprehensive experiments show our model can robustly deal with various inpainting types at different video duration range, with high quality. More visualization results is made publicly available at https://zhang-zx.github.io/AVID/ .
DeFormer: Integrating Transformers with Deformable Models for 3D Shape Abstraction from a Single Image
Sep 22, 2023



Accurate 3D shape abstraction from a single 2D image is a long-standing problem in computer vision and graphics. By leveraging a set of primitives to represent the target shape, recent methods have achieved promising results. However, these methods either use a relatively large number of primitives or lack geometric flexibility due to the limited expressibility of the primitives. In this paper, we propose a novel bi-channel Transformer architecture, integrated with parameterized deformable models, termed DeFormer, to simultaneously estimate the global and local deformations of primitives. In this way, DeFormer can abstract complex object shapes while using a small number of primitives which offer a broader geometry coverage and finer details. Then, we introduce a force-driven dynamic fitting and a cycle-consistent re-projection loss to optimize the primitive parameters. Extensive experiments on ShapeNet across various settings show that DeFormer achieves better reconstruction accuracy over the state-of-the-art, and visualizes with consistent semantic correspondences for improved interpretability.
Improving Pseudo Labels for Open-Vocabulary Object Detection
Aug 11, 2023Recent studies show promising performance in open-vocabulary object detection (OVD) using pseudo labels (PLs) from pretrained vision and language models (VLMs). However, PLs generated by VLMs are extremely noisy due to the gap between the pretraining objective of VLMs and OVD, which blocks further advances on PLs. In this paper, we aim to reduce the noise in PLs and propose a method called online Self-training And a Split-and-fusion head for OVD (SAS-Det). First, the self-training finetunes VLMs to generate high quality PLs while prevents forgetting the knowledge learned in the pretraining. Second, a split-and-fusion (SAF) head is designed to remove the noise in localization of PLs, which is usually ignored in existing methods. It also fuses complementary knowledge learned from both precise ground truth and noisy pseudo labels to boost the performance. Extensive experiments demonstrate SAS-Det is both efficient and effective. Our pseudo labeling is 3 times faster than prior methods. SAS-Det outperforms prior state-of-the-art models of the same scale by a clear margin and achieves 37.4 AP$_{50}$ and 27.3 AP$_r$ on novel categories of the COCO and LVIS benchmarks, respectively.
Topology-Preserving Automatic Labeling of Coronary Arteries via Anatomy-aware Connection Classifier
Jul 22, 2023



Automatic labeling of coronary arteries is an essential task in the practical diagnosis process of cardiovascular diseases. For experienced radiologists, the anatomically predetermined connections are important for labeling the artery segments accurately, while this prior knowledge is barely explored in previous studies. In this paper, we present a new framework called TopoLab which incorporates the anatomical connections into the network design explicitly. Specifically, the strategies of intra-segment feature aggregation and inter-segment feature interaction are introduced for hierarchical segment feature extraction. Moreover, we propose the anatomy-aware connection classifier to enable classification for each connected segment pair, which effectively exploits the prior topology among the arteries with different categories. To validate the effectiveness of our method, we contribute high-quality annotations of artery labeling to the public orCaScore dataset. The experimental results on both the orCaScore dataset and an in-house dataset show that our TopoLab has achieved state-of-the-art performance.
Improving Tuning-Free Real Image Editing with Proximal Guidance
Jun 29, 2023



DDIM inversion has revealed the remarkable potential of real image editing within diffusion-based methods. However, the accuracy of DDIM reconstruction degrades as larger classifier-free guidance (CFG) scales being used for enhanced editing. Null-text inversion (NTI) optimizes null embeddings to align the reconstruction and inversion trajectories with larger CFG scales, enabling real image editing with cross-attention control. Negative-prompt inversion (NPI) further offers a training-free closed-form solution of NTI. However, it may introduce artifacts and is still constrained by DDIM reconstruction quality. To overcome these limitations, we propose proximal guidance and incorporate it to NPI with cross-attention control. We enhance NPI with a regularization term and reconstruction guidance, which reduces artifacts while capitalizing on its training-free nature. Additionally, we extend the concepts to incorporate mutual self-attention control, enabling geometry and layout alterations in the editing process. Our method provides an efficient and straightforward approach, effectively addressing real image editing tasks with minimal computational overhead.