 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
Dec 29, 2023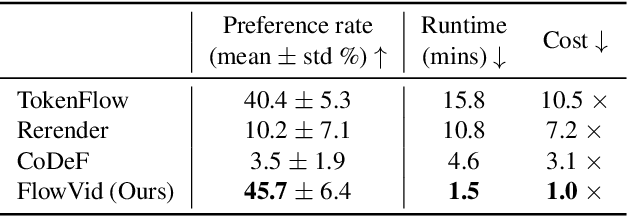

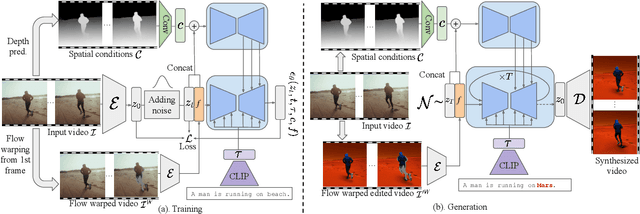

Diffusion models have transformed the image-to-image (I2I) synthesis and are now permeating into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames. This paper proposes a consistent V2V synthesis framework by jointly leveraging spatial conditions and temporal optical flow clues within the source video. Contrary to prior methods that strictly adhere to optical flow, our approach harnesses its benefits while handling the imperfection in flow estimation. We encode the optical flow via warping from the first frame and serve it as a supplementary reference in the diffusion model. This enables our model for video synthesis by editing the first frame with any prevalent I2I models and then propagating edits to successive frames. Our V2V model, FlowVid, demonstrates remarkable properties: (1) Flexibility: FlowVid works seamlessly with existing I2I models, facilitating various modifications, including stylization, object swaps, and local edits. (2) Efficiency: Generation of a 4-second video with 30 FPS and 512x512 resolution takes only 1.5 minutes, which is 3.1x, 7.2x, and 10.5x faster than CoDeF, Rerender, and TokenFlow, respectively. (3) High-quality: In user studies, our FlowVid is preferred 45.7% of the time, outperforming CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).
MixRT: Mixed Neural Representations For Real-Time NeRF Rendering
Dec 20, 2023



Neural Radiance Field (NeRF) has emerged as a leading technique for novel view synthesis, owing to its impressive photorealistic reconstruction and rendering capability. Nevertheless, achieving real-time NeRF rendering in large-scale scenes has presented challenges, often leading to the adoption of either intricate baked mesh representations with a substantial number of triangles or resource-intensive ray marching in baked representations. We challenge these conventions, observing that high-quality geometry, represented by meshes with substantial triangles, is not necessary for achieving photorealistic rendering quality. Consequently, we propose MixRT, a novel NeRF representation that includes a low-quality mesh, a view-dependent displacement map, and a compressed NeRF model. This design effectively harnesses the capabilities of existing graphics hardware, thus enabling real-time NeRF rendering on edge devices. Leveraging a highly-optimized WebGL-based rendering framework, our proposed MixRT attains real-time rendering speeds on edge devices (over 30 FPS at a resolution of 1280 x 720 on a MacBook M1 Pro laptop), better rendering quality (0.2 PSNR higher in indoor scenes of the Unbounded-360 datasets), and a smaller storage size (less than 80% compared to state-of-the-art methods).
Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis
Dec 20, 2023



In this paper, we introduce Fairy, a minimalist yet robust adaptation of image-editing diffusion models, enhancing them for video editing applications. Our approach centers on the concept of anchor-based cross-frame attention, a mechanism that implicitly propagates diffusion features across frames, ensuring superior temporal coherence and high-fidelity synthesis. Fairy not only addresses limitations of previous models, including memory and processing speed. It also improves temporal consistency through a unique data augmentation strategy. This strategy renders the model equivariant to affine transformations in both source and target images. Remarkably efficient, Fairy generates 120-frame 512x384 videos (4-second duration at 30 FPS) in just 14 seconds, outpacing prior works by at least 44x. A comprehensive user study, involving 1000 generated samples, confirms that our approach delivers superior quality, decisively outperforming established methods.
MaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers
Dec 19, 2023



Recent advances in generative AI have significantly enhanced image and video editing, particularly in the context of text prompt control. State-of-the-art approaches predominantly rely on diffusion models to accomplish these tasks. However, the computational demands of diffusion-based methods are substantial, often necessitating large-scale paired datasets for training, and therefore challenging the deployment in practical applications. This study addresses this challenge by breaking down the text-based video editing process into two separate stages. In the first stage, we leverage an existing text-to-image diffusion model to simultaneously edit a few keyframes without additional fine-tuning. In the second stage, we introduce an efficient model called MaskINT, which is built on non-autoregressive masked generative transformers and specializes in frame interpolation between the keyframes, benefiting from structural guidance provided by intermediate frames. Our comprehensive set of experiments illustrates the efficacy and efficiency of MaskINT when compared to other diffusion-based methodologies. This research offers a practical solution for text-based video editing and showcases the potential of non-autoregressive masked generative transformers in this domain.
ControlRoom3D: Room Generation using Semantic Proxy Rooms
Dec 08, 2023



Manually creating 3D environments for AR/VR applications is a complex process requiring expert knowledge in 3D modeling software. Pioneering works facilitate this process by generating room meshes conditioned on textual style descriptions. Yet, many of these automatically generated 3D meshes do not adhere to typical room layouts, compromising their plausibility, e.g., by placing several beds in one bedroom. To address these challenges, we present ControlRoom3D, a novel method to generate high-quality room meshes. Central to our approach is a user-defined 3D semantic proxy room that outlines a rough room layout based on semantic bounding boxes and a textual description of the overall room style. Our key insight is that when rendered to 2D, this 3D representation provides valuable geometric and semantic information to control powerful 2D models to generate 3D consistent textures and geometry that aligns well with the proxy room. Backed up by an extensive study including quantitative metrics and qualitative user evaluations, our method generates diverse and globally plausible 3D room meshes, thus empowering users to design 3D rooms effortlessly without specialized knowledge.
Cache Me if You Can: Accelerating Diffusion Models through Block Caching
Dec 06, 2023



Diffusion models have recently revolutionized the field of image synthesis due to their ability to generate photorealistic images. However, one of the major drawbacks of diffusion models is that the image generation process is costly. A large image-to-image network has to be applied many times to iteratively refine an image from random noise. While many recent works propose techniques to reduce the number of required steps, they generally treat the underlying denoising network as a black box. In this work, we investigate the behavior of the layers within the network and find that 1) the layers' output changes smoothly over time, 2) the layers show distinct patterns of change, and 3) the change from step to step is often very small. We hypothesize that many layer computations in the denoising network are redundant. Leveraging this, we introduce block caching, in which we reuse outputs from layer blocks of previous steps to speed up inference. Furthermore, we propose a technique to automatically determine caching schedules based on each block's changes over timesteps. In our experiments, we show through FID, human evaluation and qualitative analysis that Block Caching allows to generate images with higher visual quality at the same computational cost. We demonstrate this for different state-of-the-art models (LDM and EMU) and solvers (DDIM and DPM).
AVID: Any-Length Video Inpainting with Diffusion Model
Dec 06, 2023



Recent advances in diffusion models have successfully enabled text-guided image inpainting. While it seems straightforward to extend such editing capability into video domain, there has been fewer works regarding text-guided video inpainting. Given a video, a masked region at its initial frame, and an editing prompt, it requires a model to do infilling at each frame following the editing guidance while keeping the out-of-mask region intact. There are three main challenges in text-guided video inpainting: ($i$) temporal consistency of the edited video, ($ii$) supporting different inpainting types at different structural fidelity level, and ($iii$) dealing with variable video length. To address these challenges, we introduce Any-Length Video Inpainting with Diffusion Model, dubbed as AVID. At its core, our model is equipped with effective motion modules and adjustable structure guidance, for fixed-length video inpainting. Building on top of that, we propose a novel Temporal MultiDiffusion sampling pipeline with an middle-frame attention guidance mechanism, facilitating the generation of videos with any desired duration. Our comprehensive experiments show our model can robustly deal with various inpainting types at different video duration range, with high quality. More visualization results is made publicly available at https://zhang-zx.github.io/AVID/ .
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence
Dec 05, 2023



Current diffusion-based video editing primarily focuses on structure-preserved editing by utilizing various dense correspondences to ensure temporal consistency and motion alignment. However, these approaches are often ineffective when the target edit involves a shape change. To embark on video editing with shape change, we explore customized video subject swapping in this work, where we aim to replace the main subject in a source video with a target subject having a distinct identity and potentially different shape. In contrast to previous methods that rely on dense correspondences, we introduce the VideoSwap framework that exploits semantic point correspondences, inspired by our observation that only a small number of semantic points are necessary to align the subject's motion trajectory and modify its shape. We also introduce various user-point interactions (\eg, removing points and dragging points) to address various semantic point correspondence. Extensive experiments demonstrate state-of-the-art video subject swapping results across a variety of real-world videos.
NeRF-Det: Learning Geometry-Aware Volumetric Representation for Multi-View 3D Object Detection
Jul 27, 2023



We present NeRF-Det, a novel method for indoor 3D detection with posed RGB images as input. Unlike existing indoor 3D detection methods that struggle to model scene geometry, our method makes novel use of NeRF in an end-to-end manner to explicitly estimate 3D geometry, thereby improving 3D detection performance. Specifically, to avoid the significant extra latency associated with per-scene optimization of NeRF, we introduce sufficient geometry priors to enhance the generalizability of NeRF-MLP. Furthermore, we subtly connect the detection and NeRF branches through a shared MLP, enabling an efficient adaptation of NeRF to detection and yielding geometry-aware volumetric representations for 3D detection. Our method outperforms state-of-the-arts by 3.9 mAP and 3.1 mAP on the ScanNet and ARKITScenes benchmarks, respectively. We provide extensive analysis to shed light on how NeRF-Det works. As a result of our joint-training design, NeRF-Det is able to generalize well to unseen scenes for object detection, view synthesis, and depth estimation tasks without requiring per-scene optimization. Code is available at \url{https://github.com/facebookresearch/NeRF-Det}.
Pruning Compact ConvNets for Efficient Inference
Jan 11, 2023Neural network pruning is frequently used to compress over-parameterized networks by large amounts, while incurring only marginal drops in generalization performance. However, the impact of pruning on networks that have been highly optimized for efficient inference has not received the same level of attention. In this paper, we analyze the effect of pruning for computer vision, and study state-of-the-art ConvNets, such as the FBNetV3 family of models. We show that model pruning approaches can be used to further optimize networks trained through NAS (Neural Architecture Search). The resulting family of pruned models can consistently obtain better performance than existing FBNetV3 models at the same level of computation, and thus provide state-of-the-art results when trading off between computational complexity and generalization performance on the ImageNet benchmark. In addition to better generalization performance, we also demonstrate that when limited computation resources are available, pruning FBNetV3 models incur only a fraction of GPU-hours involved in running a full-scale NAS.