 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models
Mar 26, 2025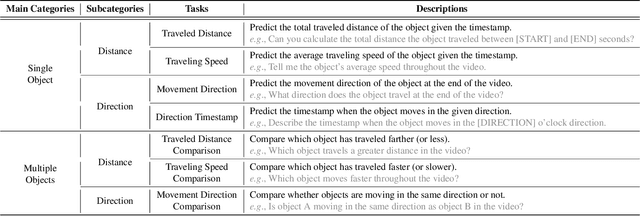

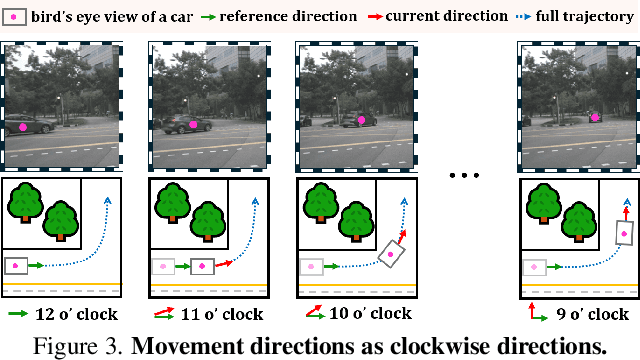
Spatio-temporal reasoning is essential in understanding real-world environments in various fields, eg, autonomous driving and sports analytics. Recent advances have improved the spatial reasoning ability of Vision-Language Models (VLMs) by introducing large-scale data, but these models still struggle to analyze kinematic elements like traveled distance and speed of moving objects. To bridge this gap, we construct a spatio-temporal reasoning dataset and benchmark involving kinematic instruction tuning, referred to as STKit and STKit-Bench. They consist of real-world videos with 3D annotations, detailing object motion dynamics: traveled distance, speed, movement direction, inter-object distance comparisons, and relative movement direction. To further scale such data construction to videos without 3D labels, we propose an automatic pipeline to generate pseudo-labels using 4D reconstruction in real-world scale. With our kinematic instruction tuning data for spatio-temporal reasoning, we present ST-VLM, a VLM enhanced for spatio-temporal reasoning, which exhibits outstanding performance on STKit-Bench. Furthermore, we show that ST-VLM generalizes robustly across diverse domains and tasks, outperforming baselines on other spatio-temporal benchmarks (eg, ActivityNet, TVQA+). Finally, by integrating learned spatio-temporal reasoning with existing abilities, ST-VLM enables complex multi-step reasoning. Project page: https://ikodoh.github.io/ST-VLM.
Generating Enhanced Negatives for Training Language-Based Object Detectors
Dec 29, 2023The recent progress in language-based open-vocabulary object detection can be largely attributed to finding better ways of leveraging large-scale data with free-form text annotations. Training such models with a discriminative objective function has proven successful, but requires good positive and negative samples. However, the free-form nature and the open vocabulary of object descriptions make the space of negatives extremely large. Prior works randomly sample negatives or use rule-based techniques to build them. In contrast, we propose to leverage the vast knowledge built into modern generative models to automatically build negatives that are more relevant to the original data. Specifically, we use large-language-models to generate negative text descriptions, and text-to-image diffusion models to also generate corresponding negative images. Our experimental analysis confirms the relevance of the generated negative data, and its use in language-based detectors improves performance on two complex benchmarks.
Improving Pseudo Labels for Open-Vocabulary Object Detection
Aug 11, 2023Recent studies show promising performance in open-vocabulary object detection (OVD) using pseudo labels (PLs) from pretrained vision and language models (VLMs). However, PLs generated by VLMs are extremely noisy due to the gap between the pretraining objective of VLMs and OVD, which blocks further advances on PLs. In this paper, we aim to reduce the noise in PLs and propose a method called online Self-training And a Split-and-fusion head for OVD (SAS-Det). First, the self-training finetunes VLMs to generate high quality PLs while prevents forgetting the knowledge learned in the pretraining. Second, a split-and-fusion (SAF) head is designed to remove the noise in localization of PLs, which is usually ignored in existing methods. It also fuses complementary knowledge learned from both precise ground truth and noisy pseudo labels to boost the performance. Extensive experiments demonstrate SAS-Det is both efficient and effective. Our pseudo labeling is 3 times faster than prior methods. SAS-Det outperforms prior state-of-the-art models of the same scale by a clear margin and achieves 37.4 AP$_{50}$ and 27.3 AP$_r$ on novel categories of the COCO and LVIS benchmarks, respectively.
Exploiting Unlabeled Data with Vision and Language Models for Object Detection
Jul 18, 2022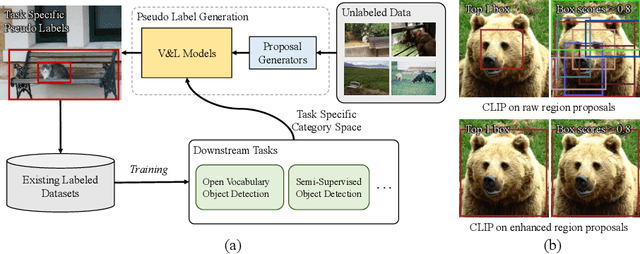
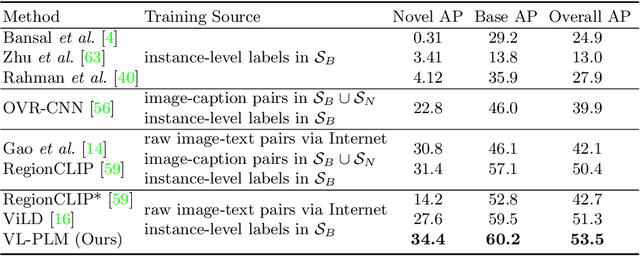
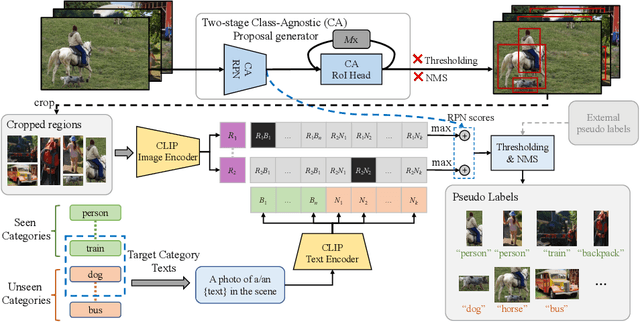

Building robust and generic object detection frameworks requires scaling to larger label spaces and bigger training datasets. However, it is prohibitively costly to acquire annotations for thousands of categories at a large scale. We propose a novel method that leverages the rich semantics available in recent vision and language models to localize and classify objects in unlabeled images, effectively generating pseudo labels for object detection. Starting with a generic and class-agnostic region proposal mechanism, we use vision and language models to categorize each region of an image into any object category that is required for downstream tasks. We demonstrate the value of the generated pseudo labels in two specific tasks, open-vocabulary detection, where a model needs to generalize to unseen object categories, and semi-supervised object detection, where additional unlabeled images can be used to improve the model. Our empirical evaluation shows the effectiveness of the pseudo labels in both tasks, where we outperform competitive baselines and achieve a novel state-of-the-art for open-vocabulary object detection. Our code is available at https://github.com/xiaofeng94/VL-PLM.