 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Inconsistent Semantics in Multi-Dataset Image Segmentation
Sep 15, 2024Leveraging multiple training datasets to scale up image segmentation models is beneficial for increasing robustness and semantic understanding. Individual datasets have well-defined ground truth with non-overlapping mask layouts and mutually exclusive semantics. However, merging them for multi-dataset training disrupts this harmony and leads to semantic inconsistencies; for example, the class "person" in one dataset and class "face" in another will require multilabel handling for certain pixels. Existing methods struggle with this setting, particularly when evaluated on label spaces mixed from the individual training sets. To overcome these issues, we introduce a simple yet effective multi-dataset training approach by integrating language-based embeddings of class names and label space-specific query embeddings. Our method maintains high performance regardless of the underlying inconsistencies between training datasets. Notably, on four benchmark datasets with label space inconsistencies during inference, we outperform previous methods by 1.6% mIoU for semantic segmentation, 9.1% PQ for panoptic segmentation, 12.1% AP for instance segmentation, and 3.0% in the newly proposed PIQ metric.
SceneTextGen: Layout-Agnostic Scene Text Image Synthesis with Diffusion Models
Jun 03, 2024



While diffusion models have significantly advanced the quality of image generation, their capability to accurately and coherently render text within these images remains a substantial challenge. Conventional diffusion-based methods for scene text generation are typically limited by their reliance on an intermediate layout output. This dependency often results in a constrained diversity of text styles and fonts, an inherent limitation stemming from the deterministic nature of the layout generation phase. To address these challenges, this paper introduces SceneTextGen, a novel diffusion-based model specifically designed to circumvent the need for a predefined layout stage. By doing so, SceneTextGen facilitates a more natural and varied representation of text. The novelty of SceneTextGen lies in its integration of three key components: a character-level encoder for capturing detailed typographic properties, coupled with a character-level instance segmentation model and a word-level spotting model to address the issues of unwanted text generation and minor character inaccuracies. We validate the performance of our method by demonstrating improved character recognition rates on generated images across different public visual text datasets in comparison to both standard diffusion based methods and text specific methods.
DeFormer: Integrating Transformers with Deformable Models for 3D Shape Abstraction from a Single Image
Sep 22, 2023



Accurate 3D shape abstraction from a single 2D image is a long-standing problem in computer vision and graphics. By leveraging a set of primitives to represent the target shape, recent methods have achieved promising results. However, these methods either use a relatively large number of primitives or lack geometric flexibility due to the limited expressibility of the primitives. In this paper, we propose a novel bi-channel Transformer architecture, integrated with parameterized deformable models, termed DeFormer, to simultaneously estimate the global and local deformations of primitives. In this way, DeFormer can abstract complex object shapes while using a small number of primitives which offer a broader geometry coverage and finer details. Then, we introduce a force-driven dynamic fitting and a cycle-consistent re-projection loss to optimize the primitive parameters. Extensive experiments on ShapeNet across various settings show that DeFormer achieves better reconstruction accuracy over the state-of-the-art, and visualizes with consistent semantic correspondences for improved interpretability.
Deep Deformable Models: Learning 3D Shape Abstractions with Part Consistency
Sep 02, 2023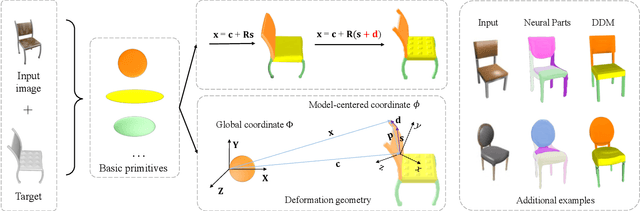
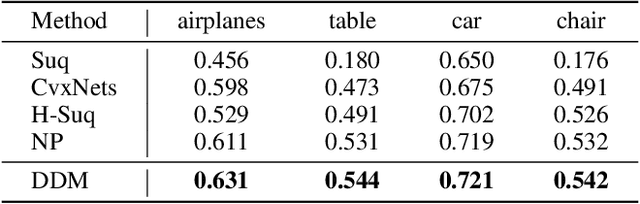
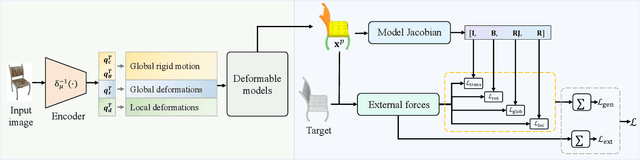
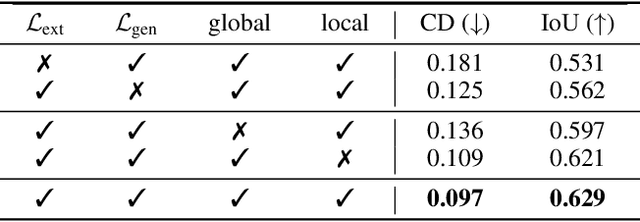
The task of shape abstraction with semantic part consistency is challenging due to the complex geometries of natural objects. Recent methods learn to represent an object shape using a set of simple primitives to fit the target. \textcolor{black}{However, in these methods, the primitives used do not always correspond to real parts or lack geometric flexibility for semantic interpretation.} In this paper, we investigate salient and efficient primitive descriptors for accurate shape abstractions, and propose \textit{Deep Deformable Models (DDMs)}. DDM employs global deformations and diffeomorphic local deformations. These properties enable DDM to abstract complex object shapes with significantly fewer primitives that offer broader geometry coverage and finer details. DDM is also capable of learning part-level semantic correspondences due to the differentiable and invertible properties of our primitive deformation. Moreover, DDM learning formulation is based on dynamic and kinematic modeling, which enables joint regularization of each sub-transformation during primitive fitting. Extensive experiments on \textit{ShapeNet} demonstrate that DDM outperforms the state-of-the-art in terms of reconstruction and part consistency by a notable margin.
Improving Tuning-Free Real Image Editing with Proximal Guidance
Jun 29, 2023



DDIM inversion has revealed the remarkable potential of real image editing within diffusion-based methods. However, the accuracy of DDIM reconstruction degrades as larger classifier-free guidance (CFG) scales being used for enhanced editing. Null-text inversion (NTI) optimizes null embeddings to align the reconstruction and inversion trajectories with larger CFG scales, enabling real image editing with cross-attention control. Negative-prompt inversion (NPI) further offers a training-free closed-form solution of NTI. However, it may introduce artifacts and is still constrained by DDIM reconstruction quality. To overcome these limitations, we propose proximal guidance and incorporate it to NPI with cross-attention control. We enhance NPI with a regularization term and reconstruction guidance, which reduces artifacts while capitalizing on its training-free nature. Additionally, we extend the concepts to incorporate mutual self-attention control, enabling geometry and layout alterations in the editing process. Our method provides an efficient and straightforward approach, effectively addressing real image editing tasks with minimal computational overhead.
Dealing With Heterogeneous 3D MR Knee Images: A Federated Few-Shot Learning Method With Dual Knowledge Distillation
Apr 18, 2023Federated Learning has gained popularity among medical institutions since it enables collaborative training between clients (e.g., hospitals) without aggregating data. However, due to the high cost associated with creating annotations, especially for large 3D image datasets, clinical institutions do not have enough supervised data for training locally. Thus, the performance of the collaborative model is subpar under limited supervision. On the other hand, large institutions have the resources to compile data repositories with high-resolution images and labels. Therefore, individual clients can utilize the knowledge acquired in the public data repositories to mitigate the shortage of private annotated images. In this paper, we propose a federated few-shot learning method with dual knowledge distillation. This method allows joint training with limited annotations across clients without jeopardizing privacy. The supervised learning of the proposed method extracts features from limited labeled data in each client, while the unsupervised data is used to distill both feature and response-based knowledge from a national data repository to further improve the accuracy of the collaborative model and reduce the communication cost. Extensive evaluations are conducted on 3D magnetic resonance knee images from a private clinical dataset. Our proposed method shows superior performance and less training time than other semi-supervised federated learning methods. Codes and additional visualization results are available at https://github.com/hexiaoxiao-cs/fedml-knee.
DeepRecon: Joint 2D Cardiac Segmentation and 3D Volume Reconstruction via A Structure-Specific Generative Method
Jun 14, 2022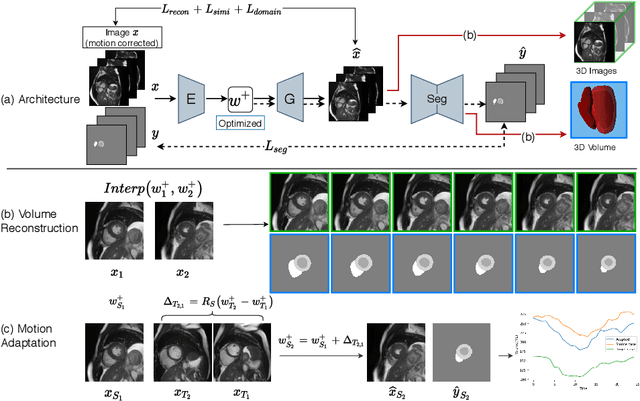
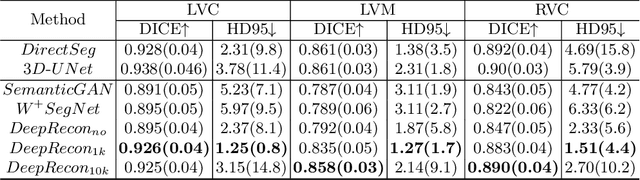
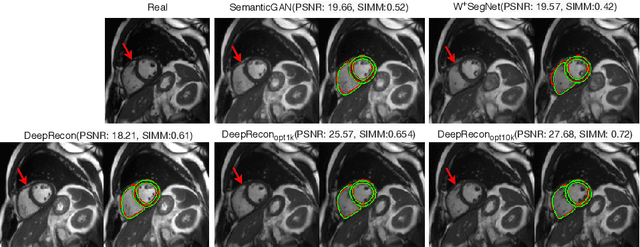
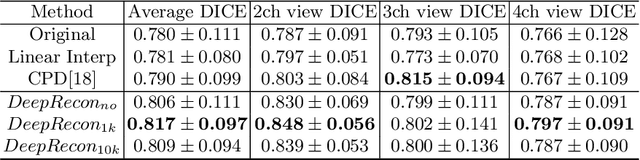
Joint 2D cardiac segmentation and 3D volume reconstruction are fundamental to building statistical cardiac anatomy models and understanding functional mechanisms from motion patterns. However, due to the low through-plane resolution of cine MR and high inter-subject variance, accurately segmenting cardiac images and reconstructing the 3D volume are challenging. In this study, we propose an end-to-end latent-space-based framework, DeepRecon, that generates multiple clinically essential outcomes, including accurate image segmentation, synthetic high-resolution 3D image, and 3D reconstructed volume. Our method identifies the optimal latent representation of the cine image that contains accurate semantic information for cardiac structures. In particular, our model jointly generates synthetic images with accurate semantic information and segmentation of the cardiac structures using the optimal latent representation. We further explore downstream applications of 3D shape reconstruction and 4D motion pattern adaptation by the different latent-space manipulation strategies.The simultaneously generated high-resolution images present a high interpretable value to assess the cardiac shape and motion.Experimental results demonstrate the effectiveness of our approach on multiple fronts including 2D segmentation, 3D reconstruction, downstream 4D motion pattern adaption performance.
TransFusion: Multi-view Divergent Fusion for Medical Image Segmentation with Transformers
Mar 21, 2022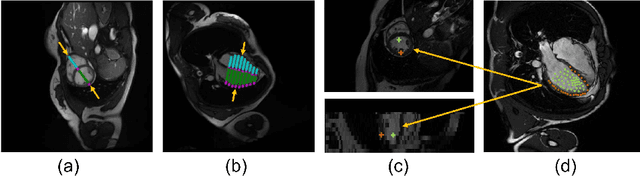
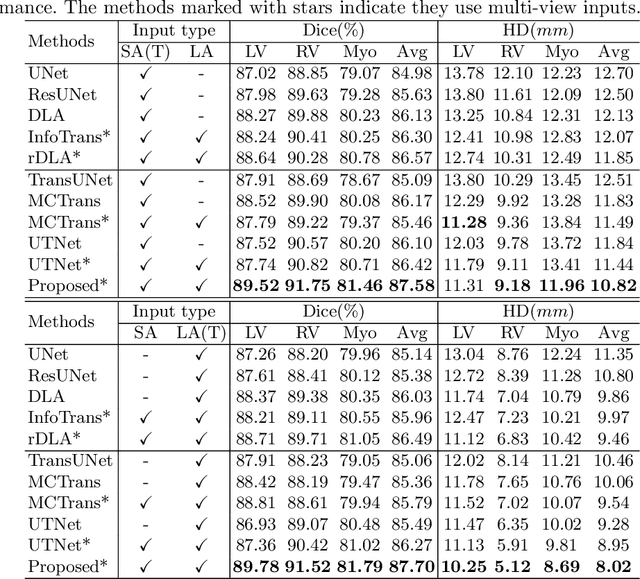
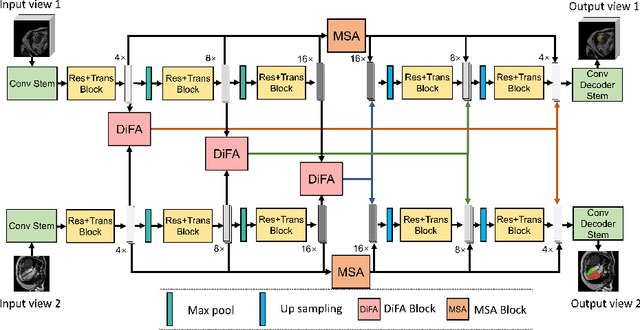
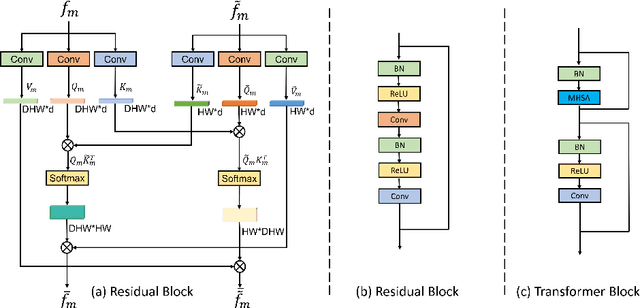
Combining information from multi-view images is crucial to improve the performance and robustness of automated methods for disease diagnosis. However, due to the non-alignment characteristics of multi-view images, building correlation and data fusion across views largely remain an open problem. In this study, we present TransFusion, a Transformer-based architecture to merge divergent multi-view imaging information using convolutional layers and powerful attention mechanisms. In particular, the Divergent Fusion Attention (DiFA) module is proposed for rich cross-view context modeling and semantic dependency mining, addressing the critical issue of capturing long-range correlations between unaligned data from different image views. We further propose the Multi-Scale Attention (MSA) to collect global correspondence of multi-scale feature representations. We evaluate TransFusion on the Multi-Disease, Multi-View \& Multi-Center Right Ventricular Segmentation in Cardiac MRI (M\&Ms-2) challenge cohort. TransFusion demonstrates leading performance against the state-of-the-art methods and opens up new perspectives for multi-view imaging integration towards robust medical image segmentation.
Region Proposal Rectification Towards Robust Instance Segmentation of Biological Images
Mar 06, 2022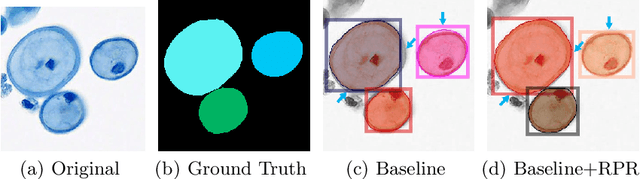
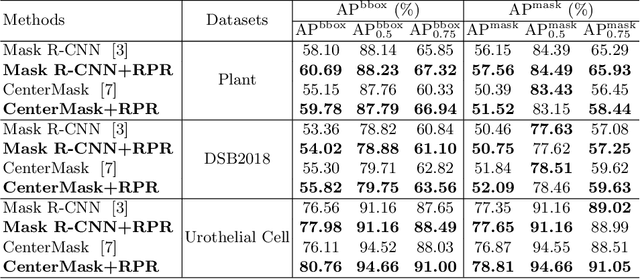
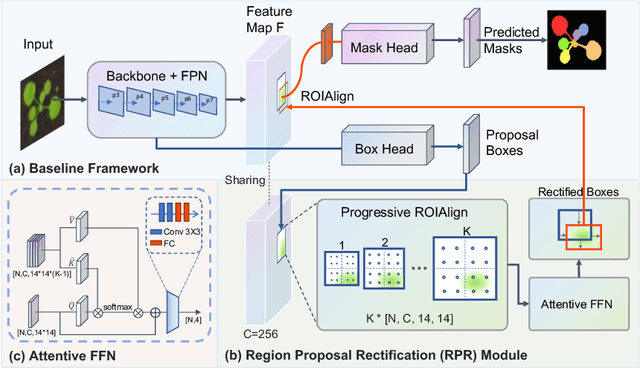
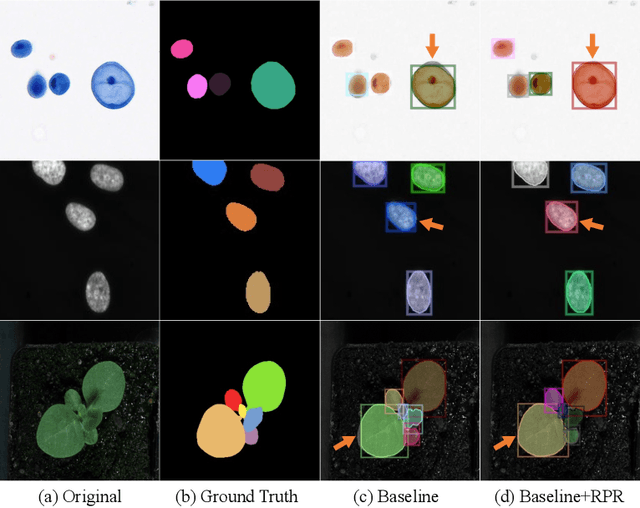
Top-down instance segmentation framework has shown its superiority in object detection compared to the bottom-up framework. While it is efficient in addressing over-segmentation, top-down instance segmentation suffers from over-crop problem. However, a complete segmentation mask is crucial for biological image analysis as it delivers important morphological properties such as shapes and volumes. In this paper, we propose a region proposal rectification (RPR) module to address this challenging incomplete segmentation problem. In particular, we offer a progressive ROIAlign module to introduce neighbor information into a series of ROIs gradually. The ROI features are fed into an attentive feed-forward network (FFN) for proposal box regression. With additional neighbor information, the proposed RPR module shows significant improvement in correction of region proposal locations and thereby exhibits favorable instance segmentation performances on three biological image datasets compared to state-of-the-art baseline methods. Experimental results demonstrate that the proposed RPR module is effective in both anchor-based and anchor-free top-down instance segmentation approaches, suggesting the proposed method can be applied to general top-down instance segmentation of biological images.