 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
Apr 24, 2025Autoregressive (AR) models, long dominant in language generation, are increasingly applied to image synthesis but are often considered less competitive than Diffusion-based models. A primary limitation is the substantial number of image tokens required for AR models, which constrains both training and inference efficiency, as well as image resolution. To address this, we present Token-Shuffle, a novel yet simple method that reduces the number of image tokens in Transformer. Our key insight is the dimensional redundancy of visual vocabularies in Multimodal Large Language Models (MLLMs), where low-dimensional visual codes from visual encoder are directly mapped to high-dimensional language vocabularies. Leveraging this, we consider two key operations: token-shuffle, which merges spatially local tokens along channel dimension to decrease the input token number, and token-unshuffle, which untangles the inferred tokens after Transformer blocks to restore the spatial arrangement for output. Jointly training with textual prompts, our strategy requires no additional pretrained text-encoder and enables MLLMs to support extremely high-resolution image synthesis in a unified next-token prediction way while maintaining efficient training and inference. For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. In GenAI-benchmark, our 2.7B model achieves 0.77 overall score on hard prompts, outperforming AR models LlamaGen by 0.18 and diffusion models LDM by 0.15. Exhaustive large-scale human evaluations also demonstrate our prominent image generation ability in terms of text-alignment, visual flaw, and visual appearance. We hope that Token-Shuffle can serve as a foundational design for efficient high-resolution image generation within MLLMs.
MoCha: Towards Movie-Grade Talking Character Synthesis
Mar 30, 2025



Recent advancements in video generation have achieved impressive motion realism, yet they often overlook character-driven storytelling, a crucial task for automated film, animation generation. We introduce Talking Characters, a more realistic task to generate talking character animations directly from speech and text. Unlike talking head, Talking Characters aims at generating the full portrait of one or more characters beyond the facial region. In this paper, we propose MoCha, the first of its kind to generate talking characters. To ensure precise synchronization between video and speech, we propose a speech-video window attention mechanism that effectively aligns speech and video tokens. To address the scarcity of large-scale speech-labeled video datasets, we introduce a joint training strategy that leverages both speech-labeled and text-labeled video data, significantly improving generalization across diverse character actions. We also design structured prompt templates with character tags, enabling, for the first time, multi-character conversation with turn-based dialogue-allowing AI-generated characters to engage in context-aware conversations with cinematic coherence. Extensive qualitative and quantitative evaluations, including human preference studies and benchmark comparisons, demonstrate that MoCha sets a new standard for AI-generated cinematic storytelling, achieving superior realism, expressiveness, controllability and generalization.
Learnings from Scaling Visual Tokenizers for Reconstruction and Generation
Jan 16, 2025



Visual tokenization via auto-encoding empowers state-of-the-art image and video generative models by compressing pixels into a latent space. Although scaling Transformer-based generators has been central to recent advances, the tokenizer component itself is rarely scaled, leaving open questions about how auto-encoder design choices influence both its objective of reconstruction and downstream generative performance. Our work aims to conduct an exploration of scaling in auto-encoders to fill in this blank. To facilitate this exploration, we replace the typical convolutional backbone with an enhanced Vision Transformer architecture for Tokenization (ViTok). We train ViTok on large-scale image and video datasets far exceeding ImageNet-1K, removing data constraints on tokenizer scaling. We first study how scaling the auto-encoder bottleneck affects both reconstruction and generation -- and find that while it is highly correlated with reconstruction, its relationship with generation is more complex. We next explored the effect of separately scaling the auto-encoders' encoder and decoder on reconstruction and generation performance. Crucially, we find that scaling the encoder yields minimal gains for either reconstruction or generation, while scaling the decoder boosts reconstruction but the benefits for generation are mixed. Building on our exploration, we design ViTok as a lightweight auto-encoder that achieves competitive performance with state-of-the-art auto-encoders on ImageNet-1K and COCO reconstruction tasks (256p and 512p) while outperforming existing auto-encoders on 16-frame 128p video reconstruction for UCF-101, all with 2-5x fewer FLOPs. When integrated with Diffusion Transformers, ViTok demonstrates competitive performance on image generation for ImageNet-1K and sets new state-of-the-art benchmarks for class-conditional video generation on UCF-101.
DirectorLLM for Human-Centric Video Generation
Dec 19, 2024



In this paper, we introduce DirectorLLM, a novel video generation model that employs a large language model (LLM) to orchestrate human poses within videos. As foundational text-to-video models rapidly evolve, the demand for high-quality human motion and interaction grows. To address this need and enhance the authenticity of human motions, we extend the LLM from a text generator to a video director and human motion simulator. Utilizing open-source resources from Llama 3, we train the DirectorLLM to generate detailed instructional signals, such as human poses, to guide video generation. This approach offloads the simulation of human motion from the video generator to the LLM, effectively creating informative outlines for human-centric scenes. These signals are used as conditions by the video renderer, facilitating more realistic and prompt-following video generation. As an independent LLM module, it can be applied to different video renderers, including UNet and DiT, with minimal effort. Experiments on automatic evaluation benchmarks and human evaluations show that our model outperforms existing ones in generating videos with higher human motion fidelity, improved prompt faithfulness, and enhanced rendered subject naturalness.
LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity
Dec 13, 2024



Text-to-video generation enhances content creation but is highly computationally intensive: The computational cost of Diffusion Transformers (DiTs) scales quadratically in the number of pixels. This makes minute-length video generation extremely expensive, limiting most existing models to generating videos of only 10-20 seconds length. We propose a Linear-complexity text-to-video Generation (LinGen) framework whose cost scales linearly in the number of pixels. For the first time, LinGen enables high-resolution minute-length video generation on a single GPU without compromising quality. It replaces the computationally-dominant and quadratic-complexity block, self-attention, with a linear-complexity block called MATE, which consists of an MA-branch and a TE-branch. The MA-branch targets short-to-long-range correlations, combining a bidirectional Mamba2 block with our token rearrangement method, Rotary Major Scan, and our review tokens developed for long video generation. The TE-branch is a novel TEmporal Swin Attention block that focuses on temporal correlations between adjacent tokens and medium-range tokens. The MATE block addresses the adjacency preservation issue of Mamba and improves the consistency of generated videos significantly. Experimental results show that LinGen outperforms DiT (with a 75.6% win rate) in video quality with up to 15$\times$ (11.5$\times$) FLOPs (latency) reduction. Furthermore, both automatic metrics and human evaluation demonstrate our LinGen-4B yields comparable video quality to state-of-the-art models (with a 50.5%, 52.1%, 49.1% win rate with respect to Gen-3, LumaLabs, and Kling, respectively). This paves the way to hour-length movie generation and real-time interactive video generation. We provide 68s video generation results and more examples in our project website: https://lineargen.github.io/.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Pixel-Space Post-Training of Latent Diffusion Models
Sep 26, 2024



Latent diffusion models (LDMs) have made significant advancements in the field of image generation in recent years. One major advantage of LDMs is their ability to operate in a compressed latent space, allowing for more efficient training and deployment. However, despite these advantages, challenges with LDMs still remain. For example, it has been observed that LDMs often generate high-frequency details and complex compositions imperfectly. We hypothesize that one reason for these flaws is due to the fact that all pre- and post-training of LDMs are done in latent space, which is typically $8 \times 8$ lower spatial-resolution than the output images. To address this issue, we propose adding pixel-space supervision in the post-training process to better preserve high-frequency details. Experimentally, we show that adding a pixel-space objective significantly improves both supervised quality fine-tuning and preference-based post-training by a large margin on a state-of-the-art DiT transformer and U-Net diffusion models in both visual quality and visual flaw metrics, while maintaining the same text alignment quality.
Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation
May 08, 2024Diffusion models are a powerful generative framework, but come with expensive inference. Existing acceleration methods often compromise image quality or fail under complex conditioning when operating in an extremely low-step regime. In this work, we propose a novel distillation framework tailored to enable high-fidelity, diverse sample generation using just one to three steps. Our approach comprises three key components: (i) Backward Distillation, which mitigates training-inference discrepancies by calibrating the student on its own backward trajectory; (ii) Shifted Reconstruction Loss that dynamically adapts knowledge transfer based on the current time step; and (iii) Noise Correction, an inference-time technique that enhances sample quality by addressing singularities in noise prediction. Through extensive experiments, we demonstrate that our method outperforms existing competitors in quantitative metrics and human evaluations. Remarkably, it achieves performance comparable to the teacher model using only three denoising steps, enabling efficient high-quality generation.
Animated Stickers: Bringing Stickers to Life with Video Diffusion
Feb 08, 2024



We introduce animated stickers, a video diffusion model which generates an animation conditioned on a text prompt and static sticker image. Our model is built on top of the state-of-the-art Emu text-to-image model, with the addition of temporal layers to model motion. Due to the domain gap, i.e. differences in visual and motion style, a model which performed well on generating natural videos can no longer generate vivid videos when applied to stickers. To bridge this gap, we employ a two-stage finetuning pipeline: first with weakly in-domain data, followed by human-in-the-loop (HITL) strategy which we term ensemble-of-teachers. It distills the best qualities of multiple teachers into a smaller student model. We show that this strategy allows us to specifically target improvements to motion quality while maintaining the style from the static image. With inference optimizations, our model is able to generate an eight-frame video with high-quality, interesting, and relevant motion in under one second.
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
Dec 29, 2023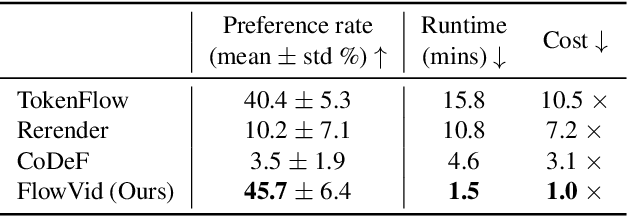

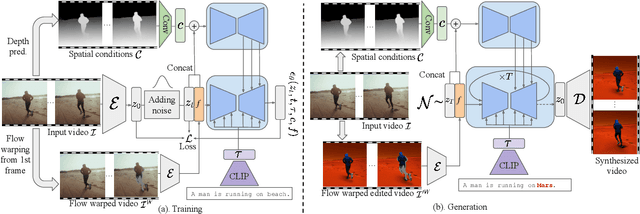

Diffusion models have transformed the image-to-image (I2I) synthesis and are now permeating into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames. This paper proposes a consistent V2V synthesis framework by jointly leveraging spatial conditions and temporal optical flow clues within the source video. Contrary to prior methods that strictly adhere to optical flow, our approach harnesses its benefits while handling the imperfection in flow estimation. We encode the optical flow via warping from the first frame and serve it as a supplementary reference in the diffusion model. This enables our model for video synthesis by editing the first frame with any prevalent I2I models and then propagating edits to successive frames. Our V2V model, FlowVid, demonstrates remarkable properties: (1) Flexibility: FlowVid works seamlessly with existing I2I models, facilitating various modifications, including stylization, object swaps, and local edits. (2) Efficiency: Generation of a 4-second video with 30 FPS and 512x512 resolution takes only 1.5 minutes, which is 3.1x, 7.2x, and 10.5x faster than CoDeF, Rerender, and TokenFlow, respectively. (3) High-quality: In user studies, our FlowVid is preferred 45.7% of the time, outperforming CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).