 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonstandard Errors in AI Agents
Mar 17, 2026We study whether state-of-the-art AI coding agents, given the same data and research question, produce the same empirical results. Deploying 150 autonomous Claude Code agents to independently test six hypotheses about market quality trends in NYSE TAQ data for SPY (2015--2024), we find that AI agents exhibit sizable \textit{nonstandard errors} (NSEs), that is, uncertainty from agent-to-agent variation in analytical choices, analogous to those documented among human researchers. AI agents diverge substantially on measure choice (e.g., autocorrelation vs.\ variance ratio, dollar vs.\ share volume). Different model families (Sonnet 4.6 vs.\ Opus 4.6) exhibit stable ``empirical styles,'' reflecting systematic differences in methodological preferences. In a three-stage feedback protocol, AI peer review (written critiques) has minimal effect on dispersion, whereas exposure to top-rated exemplar papers reduces the interquartile range of estimates by 80--99\% within \textit{converging} measure families. Convergence occurs both through within-family estimation tightening and through agents switching measure families entirely, but convergence reflects imitation rather than understanding. These findings have implications for the growing use of AI in automated policy evaluation and empirical research.
LIBRA: Language Model Informed Bandit Recourse Algorithm for Personalized Treatment Planning
Jan 17, 2026We introduce a unified framework that seamlessly integrates algorithmic recourse, contextual bandits, and large language models (LLMs) to support sequential decision-making in high-stakes settings such as personalized medicine. We first introduce the recourse bandit problem, where a decision-maker must select both a treatment action and a feasible, minimal modification to mutable patient features. To address this problem, we develop the Generalized Linear Recourse Bandit (GLRB) algorithm. Building on this foundation, we propose LIBRA, a Language Model-Informed Bandit Recourse Algorithm that strategically combines domain knowledge from LLMs with the statistical rigor of bandit learning. LIBRA offers three key guarantees: (i) a warm-start guarantee, showing that LIBRA significantly reduces initial regret when LLM recommendations are near-optimal; (ii) an LLM-effort guarantee, proving that the algorithm consults the LLM only $O(\log^2 T)$ times, where $T$ is the time horizon, ensuring long-term autonomy; and (iii) a robustness guarantee, showing that LIBRA never performs worse than a pure bandit algorithm even when the LLM is unreliable. We further establish matching lower bounds that characterize the fundamental difficulty of the recourse bandit problem and demonstrate the near-optimality of our algorithms. Experiments on synthetic environments and a real hypertension-management case study confirm that GLRB and LIBRA improve regret, treatment quality, and sample efficiency compared with standard contextual bandits and LLM-only benchmarks. Our results highlight the promise of recourse-aware, LLM-assisted bandit algorithms for trustworthy LLM-bandits collaboration in personalized high-stakes decision-making.
Beyond Demand Estimation: Consumer Surplus Evaluation via Cumulative Propensity Weights
Jan 03, 2026This paper develops a practical framework for using observational data to audit the consumer surplus effects of AI-driven decisions, specifically in targeted pricing and algorithmic lending. Traditional approaches first estimate demand functions and then integrate to compute consumer surplus, but these methods can be challenging to implement in practice due to model misspecification in parametric demand forms and the large data requirements and slow convergence of flexible nonparametric or machine learning approaches. Instead, we exploit the randomness inherent in modern algorithmic pricing, arising from the need to balance exploration and exploitation, and introduce an estimator that avoids explicit estimation and numerical integration of the demand function. Each observed purchase outcome at a randomized price is an unbiased estimate of demand and by carefully reweighting purchase outcomes using novel cumulative propensity weights (CPW), we are able to reconstruct the integral. Building on this idea, we introduce a doubly robust variant named the augmented cumulative propensity weighting (ACPW) estimator that only requires one of either the demand model or the historical pricing policy distribution to be correctly specified. Furthermore, this approach facilitates the use of flexible machine learning methods for estimating consumer surplus, since it achieves fast convergence rates by incorporating an estimate of demand, even when the machine learning estimate has slower convergence rates. Neither of these estimators is a standard application of off-policy evaluation techniques as the target estimand, consumer surplus, is unobserved. To address fairness, we extend this framework to an inequality-aware surplus measure, allowing regulators and firms to quantify the profit-equity trade-off. Finally, we validate our methods through comprehensive numerical studies.
HR-Bandit: Human-AI Collaborated Linear Recourse Bandit
Oct 18, 2024



Human doctors frequently recommend actionable recourses that allow patients to modify their conditions to access more effective treatments. Inspired by such healthcare scenarios, we propose the Recourse Linear UCB ($\textsf{RLinUCB}$) algorithm, which optimizes both action selection and feature modifications by balancing exploration and exploitation. We further extend this to the Human-AI Linear Recourse Bandit ($\textsf{HR-Bandit}$), which integrates human expertise to enhance performance. $\textsf{HR-Bandit}$ offers three key guarantees: (i) a warm-start guarantee for improved initial performance, (ii) a human-effort guarantee to minimize required human interactions, and (iii) a robustness guarantee that ensures sublinear regret even when human decisions are suboptimal. Empirical results, including a healthcare case study, validate its superior performance against existing benchmarks.
Adjusting Regression Models for Conditional Uncertainty Calibration
Sep 26, 2024Conformal Prediction methods have finite-sample distribution-free marginal coverage guarantees. However, they generally do not offer conditional coverage guarantees, which can be important for high-stakes decisions. In this paper, we propose a novel algorithm to train a regression function to improve the conditional coverage after applying the split conformal prediction procedure. We establish an upper bound for the miscoverage gap between the conditional coverage and the nominal coverage rate and propose an end-to-end algorithm to control this upper bound. We demonstrate the efficacy of our method empirically on synthetic and real-world datasets.
Nonparametric Discrete Choice Experiments with Machine Learning Guided Adaptive Design
Oct 18, 2023Designing products to meet consumers' preferences is essential for a business's success. We propose the Gradient-based Survey (GBS), a discrete choice experiment for multiattribute product design. The experiment elicits consumer preferences through a sequence of paired comparisons for partial profiles. GBS adaptively constructs paired comparison questions based on the respondents' previous choices. Unlike the traditional random utility maximization paradigm, GBS is robust to model misspecification by not requiring a parametric utility model. Cross-pollinating the machine learning and experiment design, GBS is scalable to products with hundreds of attributes and can design personalized products for heterogeneous consumers. We demonstrate the advantage of GBS in accuracy and sample efficiency compared to the existing parametric and nonparametric methods in simulations.
Confounding-Robust Policy Improvement with Human-AI Teams
Oct 13, 2023



Human-AI collaboration has the potential to transform various domains by leveraging the complementary strengths of human experts and Artificial Intelligence (AI) systems. However, unobserved confounding can undermine the effectiveness of this collaboration, leading to biased and unreliable outcomes. In this paper, we propose a novel solution to address unobserved confounding in human-AI collaboration by employing the marginal sensitivity model (MSM). Our approach combines domain expertise with AI-driven statistical modeling to account for potential confounders that may otherwise remain hidden. We present a deferral collaboration framework for incorporating the MSM into policy learning from observational data, enabling the system to control for the influence of unobserved confounding factors. In addition, we propose a personalized deferral collaboration system to leverage the diverse expertise of different human decision-makers. By adjusting for potential biases, our proposed solution enhances the robustness and reliability of collaborative outcomes. The empirical and theoretical analyses demonstrate the efficacy of our approach in mitigating unobserved confounding and improving the overall performance of human-AI collaborations.
Improving Tuning-Free Real Image Editing with Proximal Guidance
Jun 29, 2023



DDIM inversion has revealed the remarkable potential of real image editing within diffusion-based methods. However, the accuracy of DDIM reconstruction degrades as larger classifier-free guidance (CFG) scales being used for enhanced editing. Null-text inversion (NTI) optimizes null embeddings to align the reconstruction and inversion trajectories with larger CFG scales, enabling real image editing with cross-attention control. Negative-prompt inversion (NPI) further offers a training-free closed-form solution of NTI. However, it may introduce artifacts and is still constrained by DDIM reconstruction quality. To overcome these limitations, we propose proximal guidance and incorporate it to NPI with cross-attention control. We enhance NPI with a regularization term and reconstruction guidance, which reduces artifacts while capitalizing on its training-free nature. Additionally, we extend the concepts to incorporate mutual self-attention control, enabling geometry and layout alterations in the editing process. Our method provides an efficient and straightforward approach, effectively addressing real image editing tasks with minimal computational overhead.
Learning Complementary Policies for Human-AI Teams
Feb 06, 2023



Human-AI complementarity is important when neither the algorithm nor the human yields dominant performance across all instances in a given context. Recent work that explored human-AI collaboration has considered decisions that correspond to classification tasks. However, in many important contexts where humans can benefit from AI complementarity, humans undertake course of action. In this paper, we propose a framework for a novel human-AI collaboration for selecting advantageous course of action, which we refer to as Learning Complementary Policy for Human-AI teams (\textsc{lcp-hai}). Our solution aims to exploit the human-AI complementarity to maximize decision rewards by learning both an algorithmic policy that aims to complement humans by a routing model that defers decisions to either a human or the AI to leverage the resulting complementarity. We then extend our approach to leverage opportunities and mitigate risks that arise in important contexts in practice: 1) when a team is composed of multiple humans with differential and potentially complementary abilities, 2) when the observational data includes consistent deterministic actions, and 3) when the covariate distribution of future decisions differ from that in the historical data. We demonstrate the effectiveness of our proposed methods using data on real human responses and semi-synthetic, and find that our methods offer reliable and advantageous performance across setting, and that it is superior to when either the algorithm or the AI make decisions on their own. We also find that the extensions we propose effectively improve the robustness of the human-AI collaboration performance in the presence of different challenging settings.
Probabilistic Conformal Prediction Using Conditional Random Samples
Jun 20, 2022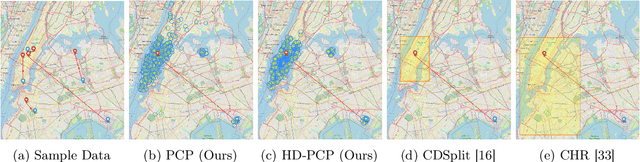
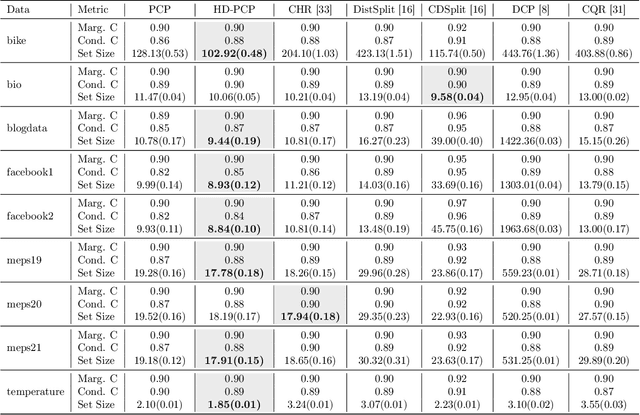
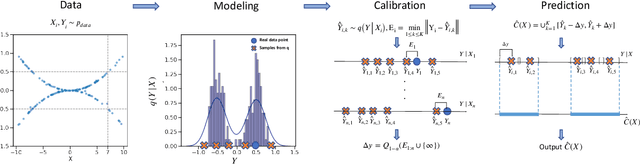

This paper proposes probabilistic conformal prediction (PCP), a predictive inference algorithm that estimates a target variable by a discontinuous predictive set. Given inputs, PCP construct the predictive set based on random samples from an estimated generative model. It is efficient and compatible with either explicit or implicit conditional generative models. Theoretically, we show that PCP guarantees correct marginal coverage with finite samples. Empirically, we study PCP on a variety of simulated and real datasets. Compared to existing methods for conformal inference, PCP provides sharper predictive sets.