 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlazeEdit: Generalist Image Editing on Mobile Devices with Image-to-Image Diffusion Models
May 27, 2026The remarkable generation quality of modern diffusion models often comes at the cost of massive parameter counts, which necessitate server-side inference with significant computational costs and potential privacy risks. Consequently, there is growing momentum toward developing efficient on-device alternatives. While recent efforts have optimized text-to-image models for mobile hardware, they remain relatively bulky, typically ranging from 0.5B to 1B parameters. We present BlazeEdit, a highly efficient, generalist image-to-image diffusion model tailored for on-device deployment. By identifying that many practical image editing tasks do not require text-based guidance, we eliminate the text-conditioning components and develop a multi-task architecture that consolidates object removal, outpainting, tone correction, relighting, and sticker generation into a single, compact model of only 195M parameters. BlazeEdit achieves a substantial reduction in download size and memory overhead while maintaining competitive generation quality. It completes a full inference pass in just 290ms on a Pixel 10, delivering a seamless, privacy-preserving, and lightning-fast experience for generalist image editing on the edge.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Mobile-VTON: High-Fidelity On-Device Virtual Try-On
Mar 03, 2026Virtual try-on (VTON) has recently achieved impressive visual fidelity, but most existing systems require uploading personal photos to cloud-based GPUs, raising privacy concerns and limiting on-device deployment. To address this, we present Mobile-VTON, a high-quality, privacy-preserving framework that enables fully offline virtual try-on on commodity mobile devices using only a single user image and a garment image. Mobile-VTON introduces a modular TeacherNet-GarmentNet-TryonNet (TGT) architecture that integrates knowledge distillation, garment-conditioned generation, and garment alignment into a unified pipeline optimized for on-device efficiency. Within this framework, we propose a Feature-Guided Adversarial (FGA) Distillation strategy that combines teacher supervision with adversarial learning to better match real-world image distributions. GarmentNet is trained with a trajectory-consistency loss to preserve garment semantics across diffusion steps, while TryonNet uses latent concatenation and lightweight cross-modal conditioning to enable robust garment-to-person alignment without large-scale pretraining. By combining these components, Mobile-VTON achieves high-fidelity generation with low computational overhead. Experiments on VITON-HD and DressCode at 1024 x 768 show that it matches or outperforms strong server-based baselines while running entirely offline. These results demonstrate that high-quality VTON is not only feasible but also practical on-device, offering a secure solution for real-world applications.
* The project page is available at: https://zhenchenwan.github.io/Mobile-VTON/
FCMBench: A Comprehensive Financial Credit Multimodal Benchmark for Real-world Applications
Jan 06, 2026As multimodal AI becomes widely used for credit risk assessment and document review, a domain-specific benchmark is urgently needed that (1) reflects documents and workflows specific to financial credit applications, (2) includes credit-specific understanding and real-world robustness, and (3) preserves privacy compliance without sacrificing practical utility. Here, we introduce FCMBench-V1.0 -- a large-scale financial credit multimodal benchmark for real-world applications, covering 18 core certificate types, with 4,043 privacy-compliant images and 8,446 QA samples. The FCMBench evaluation framework consists of three dimensions: Perception, Reasoning, and Robustness, including 3 foundational perception tasks, 4 credit-specific reasoning tasks that require decision-oriented understanding of visual evidence, and 10 real-world acquisition artifact types for robustness stress testing. To reconcile compliance with realism, we construct all samples via a closed synthesis-capture pipeline: we manually synthesize document templates with virtual content and capture scenario-aware images in-house. This design also mitigates pre-training data leakage by avoiding web-sourced or publicly released images. FCMBench can effectively discriminate performance disparities and robustness across modern vision-language models. Extensive experiments were conducted on 23 state-of-the-art vision-language models (VLMs) from 14 top AI companies and research institutes. Among them, Gemini 3 Pro achieves the best F1(\%) score as a commercial model (64.61), Qwen3-VL-235B achieves the best score as an open-source baseline (57.27), and our financial credit-specific model, Qfin-VL-Instruct, achieves the top overall score (64.92). Robustness evaluations show that even top-performing models suffer noticeable performance drops under acquisition artifacts.
Rethinking Diffusion-Based Image Generators for Fundus Fluorescein Angiography Synthesis on Limited Data
Dec 17, 2024Fundus imaging is a critical tool in ophthalmology, with different imaging modalities offering unique advantages. For instance, fundus fluorescein angiography (FFA) can accurately identify eye diseases. However, traditional invasive FFA involves the injection of sodium fluorescein, which can cause discomfort and risks. Generating corresponding FFA images from non-invasive fundus images holds significant practical value but also presents challenges. First, limited datasets constrain the performance and effectiveness of models. Second, previous studies have primarily focused on generating FFA for single diseases or single modalities, often resulting in poor performance for patients with various ophthalmic conditions. To address these issues, we propose a novel latent diffusion model-based framework, Diffusion, which introduces a fine-tuning protocol to overcome the challenge of limited medical data and unleash the generative capabilities of diffusion models. Furthermore, we designed a new approach to tackle the challenges of generating across different modalities and disease types. On limited datasets, our framework achieves state-of-the-art results compared to existing methods, offering significant potential to enhance ophthalmic diagnostics and patient care. Our code will be released soon to support further research in this field.
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
Dec 13, 2024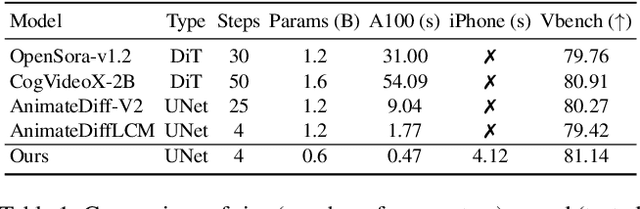
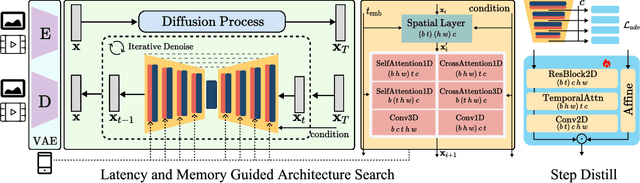
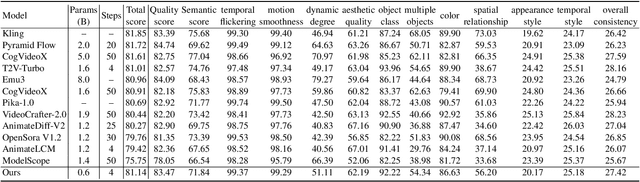
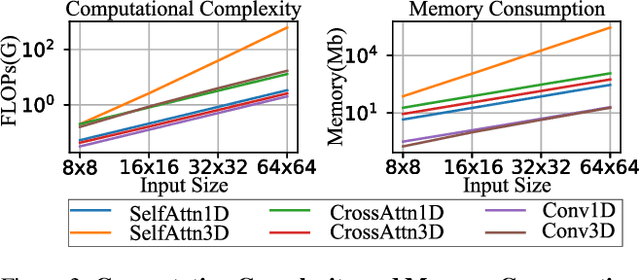
We have witnessed the unprecedented success of diffusion-based video generation over the past year. Recently proposed models from the community have wielded the power to generate cinematic and high-resolution videos with smooth motions from arbitrary input prompts. However, as a supertask of image generation, video generation models require more computation and are thus hosted mostly on cloud servers, limiting broader adoption among content creators. In this work, we propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. From the network architecture scope, we initialize from a compact image backbone and search out the design and arrangement of temporal layers to maximize hardware efficiency. In addition, we propose a dedicated adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. Compared to server-side models that take minutes on powerful GPUs to generate a single video, we accelerate the generation by magnitudes while delivering on-par quality.
Precision-Enhanced Human-Object Contact Detection via Depth-Aware Perspective Interaction and Object Texture Restoration
Dec 13, 2024



Human-object contact (HOT) is designed to accurately identify the areas where humans and objects come into contact. Current methods frequently fail to account for scenarios where objects are frequently blocking the view, resulting in inaccurate identification of contact areas. To tackle this problem, we suggest using a perspective interaction HOT detector called PIHOT, which utilizes a depth map generation model to offer depth information of humans and objects related to the camera, thereby preventing false interaction detection. Furthermore, we use mask dilatation and object restoration techniques to restore the texture details in covered areas, improve the boundaries between objects, and enhance the perception of humans interacting with objects. Moreover, a spatial awareness perception is intended to concentrate on the characteristic features close to the points of contact. The experimental results show that the PIHOT algorithm achieves state-of-the-art performance on three benchmark datasets for HOT detection tasks. Compared to the most recent DHOT, our method enjoys an average improvement of 13%, 27.5%, 16%, and 18.5% on SC-Acc., C-Acc., mIoU, and wIoU metrics, respectively.
Semi-IIN: Semi-supervised Intra-inter modal Interaction Learning Network for Multimodal Sentiment Analysis
Dec 13, 2024



Despite multimodal sentiment analysis being a fertile research ground that merits further investigation, current approaches take up high annotation cost and suffer from label ambiguity, non-amicable to high-quality labeled data acquisition. Furthermore, choosing the right interactions is essential because the significance of intra- or inter-modal interactions can differ among various samples. To this end, we propose Semi-IIN, a Semi-supervised Intra-inter modal Interaction learning Network for multimodal sentiment analysis. Semi-IIN integrates masked attention and gating mechanisms, enabling effective dynamic selection after independently capturing intra- and inter-modal interactive information. Combined with the self-training approach, Semi-IIN fully utilizes the knowledge learned from unlabeled data. Experimental results on two public datasets, MOSI and MOSEI, demonstrate the effectiveness of Semi-IIN, establishing a new state-of-the-art on several metrics. Code is available at https://github.com/flow-ljh/Semi-IIN.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
TED-VITON: Transformer-Empowered Diffusion Models for Virtual Try-On
Nov 26, 2024



Recent advancements in Virtual Try-On (VTO) have demonstrated exceptional efficacy in generating realistic images and preserving garment details, largely attributed to the robust generative capabilities of text-to-image (T2I) diffusion backbones. However, the T2I models that underpin these methods have become outdated, thereby limiting the potential for further improvement in VTO. Additionally, current methods face notable challenges in accurately rendering text on garments without distortion and preserving fine-grained details, such as textures and material fidelity. The emergence of Diffusion Transformer (DiT) based T2I models has showcased impressive performance and offers a promising opportunity for advancing VTO. Directly applying existing VTO techniques to transformer-based T2I models is ineffective due to substantial architectural differences, which hinder their ability to fully leverage the models' advanced capabilities for improved text generation. To address these challenges and unlock the full potential of DiT-based T2I models for VTO, we propose TED-VITON, a novel framework that integrates a Garment Semantic (GS) Adapter for enhancing garment-specific features, a Text Preservation Loss to ensure accurate and distortion-free text rendering, and a constraint mechanism to generate prompts by optimizing Large Language Model (LLM). These innovations enable state-of-the-art (SOTA) performance in visual quality and text fidelity, establishing a new benchmark for VTO task.