 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDash2Sim: Closed-Loop Driving Simulation from in-the-wild Dashcam Videos
Jun 05, 2026Self-driving simulations typically rely on data collected in a small number of cities or on hand-authored synthetic scenarios. Dashcam videos cover a far broader range of locations and situations, including rare or long-tailed scenarios. They are considered less usable for simulation because it is difficult to recover accurate 4D scenes from monocular in-the-wild videos. Work zones are one such class of long-tailed situations that dashcams capture. We present Dash2Sim, a framework that turns in-the-wild monocular dashcam videos into metric, geo-referenced 4D driving logs compatible with existing simulators, and verifies eachone against an independently maintained map without annotations. We apply Dash2Sim to a large video corpus to create the ROADWork4D benchmark dataset, which spans 4,244 scenes with 2.7M 3D objects across 17 cities. On a verified subset ROADWork4D-CL (2,201 scenes), we study privileged closed-loop planners and find that work zone scenarios are difficult: while rule-based and hybrid planners generalize better than learning-based ones, all fall short, failing to make the lane changes that temporary work zone channels require. Beyond planning, dense depth recovered by Dash2Sim improves novel-view synthesis quality by up to 19% on perceptual metrics, suggesting its potential to provide rich conditioning for closed-loop sensor simulation from monocular videos.
What to Test Next: Interpretable Coverage Gap Discovery in Driving VLMs
Jun 01, 2026Driving vision-language models (VLMs) must accurately understand scenes across diverse conditions defined by Operational Design Domains (ODDs), yet verification remains sparse: many slices are missing, making empirical failure rates unreliable. We propose SliceScorer, a deterministic scoring rule for missing-slice recommendation that combines (i) an exposure-based coverage prior to prioritize rare, under-tested regions, and (ii) a neighbor-failure prior that propagates risk from similar tested conditions. SliceScorer is deliberately simple - interpretable, auditable, and conservative - properties essential for safety-critical validation. For stress testing beyond the declared ODD, we embed SliceScorer within SliceNav, an LLM-orchestrated verification pipeline where the model interprets developer queries to select relevant operators (triage, scoring, acquisition, evaluation) and vocabulary extensions, composing verification workflows while keeping all scoring deterministic and auditable. Experiments on three driving VLMs (WiseAD, DriveMM, Cosmos-Reason2-2B) show that SliceNav surfaces high-risk coverage gaps more effectively than prior slice-discovery methods while maintaining diverse recommendations across the condition space. Ablations confirm both scoring components contribute, and qualitative analysis demonstrates end-to-end workflows from developer query to targeted evaluation.
HorizonWeaver: Generalizable Multi-Level Semantic Editing for Driving Scenes
Apr 06, 2026Ensuring safety in autonomous driving requires scalable generation of realistic, controllable driving scenes beyond what real-world testing provides. Yet existing instruction guided image editors, trained on object-centric or artistic data, struggle with dense, safety-critical driving layouts. We propose HorizonWeaver, which tackles three fundamental challenges in driving scene editing: (1) multi-level granularity, requiring coherent object- and scene-level edits in dense environments; (2) rich high-level semantics, preserving diverse objects while following detailed instructions; and (3) ubiquitous domain shifts, handling changes in climate, layout, and traffic across unseen environments. The core of HorizonWeaver is a set of complementary contributions across data, model, and training: (1) Data: Large-scale dataset generation, where we build a paired real/synthetic dataset from Boreas, nuScenes, and Argoverse2 to improve generalization; (2) Model: Language-Guided Masks for fine-grained editing, where semantics-enriched masks and prompts enable precise, language-guided edits; and (3) Training: Content preservation and instruction alignment, where joint losses enforce scene consistency and instruction fidelity. Together, HorizonWeaver provides a scalable framework for photorealistic, instruction-driven editing of complex driving scenes, collecting 255K images across 13 editing categories and outperforming prior methods in L1, CLIP, and DINO metrics, achieving +46.4% user preference and improving BEV segmentation IoU by +33%. Project page: https://msoroco.github.io/horizonweaver/
RAD-LAD: Rule and Language Grounded Autonomous Driving in Real-Time
Mar 31, 2026We present LAD, a real-time language--action planner with an interruptible architecture that produces a motion plan in a single forward pass (~20 Hz) or generates textual reasoning alongside a motion plan (~10 Hz). LAD is fast enough for real-time closed-loop deployment, achieving ~3x lower latency than prior driving language models while setting a new learning-based state of the art on nuPlan Test14-Hard and InterPlan. We also introduce RAD, a rule-based planner designed to address structural limitations of PDM-Closed. RAD achieves state-of-the-art performance among rule-based planners on nuPlan Test14-Hard and InterPlan. Finally, we show that combining RAD and LAD enables hybrid planning that captures the strengths of both approaches. This hybrid system demonstrates that rules and learning provide complementary capabilities: rules support reliable maneuvering, while language enables adaptive and explainable decision-making.
NERFIFY: A Multi-Agent Framework for Turning NeRF Papers into Code
Feb 28, 2026The proliferation of neural radiance field (NeRF) research requires significant efforts to reimplement papers before building upon them. We introduce NERFIFY, a multi-agent framework that reliably converts NeRF research papers into trainable Nerfstudio plugins, in contrast to generic paper-to-code methods and frontier models like GPT-5 that usually fail to produce runnable code. NERFIFY achieves domain-specific executability through six key innovations: (1) Context-free grammar (CFG): LLM synthesis is constrained by Nerfstudio formalized as a CFG, ensuring generated code satisfies architectural invariants. (2) Graph-of-Thought code synthesis: Specialized multi-file-agents generate repositories in topological dependency order, validating contracts and errors at each node. (3) Compositional citation recovery: Agents automatically retrieve and integrate components (samplers, encoders, proposal networks) from citation graphs of references. (4) Visual feedback: Artifacts are diagnosed through PSNR-minima ROI analysis, cross-view geometric validation, and VLM-guided patching to iteratively improve quality. (5) Knowledge enhancement: Beyond reproduction, methods can be improved with novel optimizations. (6) Benchmarking: An evaluation framework is designed for NeRF paper-to-code synthesis across 30 diverse papers. On papers without public implementations, NERFIFY achieves visual quality matching expert human code (+/-0.5 dB PSNR, +/-0.2 SSIM) while reducing implementation time from weeks to minutes. NERFIFY demonstrates that a domain-aware design enables code translation for complex vision papers, potentiating accelerated and democratized reproducible research. Code, data and implementations will be publicly released.
HorizonForge: Driving Scene Editing with Any Trajectories and Any Vehicles
Feb 24, 2026Controllable driving scene generation is critical for realistic and scalable autonomous driving simulation, yet existing approaches struggle to jointly achieve photorealism and precise control. We introduce HorizonForge, a unified framework that reconstructs scenes as editable Gaussian Splats and Meshes, enabling fine-grained 3D manipulation and language-driven vehicle insertion. Edits are rendered through a noise-aware video diffusion process that enforces spatial and temporal consistency, producing diverse scene variations in a single feed-forward pass without per-trajectory optimization. To standardize evaluation, we further propose HorizonSuite, a comprehensive benchmark spanning ego- and agent-level editing tasks such as trajectory modifications and object manipulation. Extensive experiments show that Gaussian-Mesh representation delivers substantially higher fidelity than alternative 3D representations, and that temporal priors from video diffusion are essential for coherent synthesis. Combining these findings, HorizonForge establishes a simple yet powerful paradigm for photorealistic, controllable driving simulation, achieving an 83.4% user-preference gain and a 25.19% FID improvement over the second best state-of-the-art method. Project page: https://horizonforge.github.io/ .
Rolling Sink: Bridging Limited-Horizon Training and Open-Ended Testing in Autoregressive Video Diffusion
Feb 08, 2026Recently, autoregressive (AR) video diffusion models has achieved remarkable performance. However, due to their limited training durations, a train-test gap emerges when testing at longer horizons, leading to rapid visual degradations. Following Self Forcing, which studies the train-test gap within the training duration, this work studies the train-test gap beyond the training duration, i.e., the gap between the limited horizons during training and open-ended horizons during testing. Since open-ended testing can extend beyond any finite training window, and long-video training is computationally expensive, we pursue a training-free solution to bridge this gap. To explore a training-free solution, we conduct a systematic analysis of AR cache maintenance. These insights lead to Rolling Sink. Built on Self Forcing (trained on only 5s clips), Rolling Sink effectively scales the AR video synthesis to ultra-long durations (e.g., 5-30 minutes at 16 FPS) at test time, with consistent subjects, stable colors, coherent structures, and smooth motions. As demonstrated by extensive experiments, Rolling Sink achieves superior long-horizon visual fidelity and temporal consistency compared to SOTA baselines. Project page: https://rolling-sink.github.io/
LangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
Dec 19, 2025

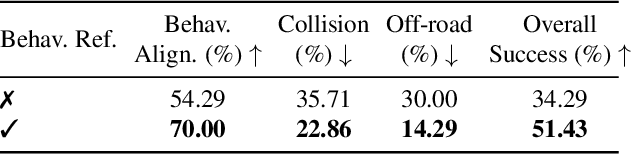

LangDriveCTRL is a natural-language-controllable framework for editing real-world driving videos to synthesize diverse traffic scenarios. It leverages explicit 3D scene decomposition to represent driving videos as a scene graph, containing static background and dynamic objects. To enable fine-grained editing and realism, it incorporates an agentic pipeline in which an Orchestrator transforms user instructions into execution graphs that coordinate specialized agents and tools. Specifically, an Object Grounding Agent establishes correspondence between free-form text descriptions and target object nodes in the scene graph; a Behavior Editing Agent generates multi-object trajectories from language instructions; and a Behavior Reviewer Agent iteratively reviews and refines the generated trajectories. The edited scene graph is rendered and then refined using a video diffusion tool to address artifacts introduced by object insertion and significant view changes. LangDriveCTRL supports both object node editing (removal, insertion and replacement) and multi-object behavior editing from a single natural-language instruction. Quantitatively, it achieves nearly $2\times$ higher instruction alignment than the previous SoTA, with superior structural preservation, photorealism, and traffic realism. Project page is available at: https://yunhe24.github.io/langdrivectrl/.
AutoScape: Geometry-Consistent Long-Horizon Scene Generation
Oct 23, 2025This paper proposes AutoScape, a long-horizon driving scene generation framework. At its core is a novel RGB-D diffusion model that iteratively generates sparse, geometrically consistent keyframes, serving as reliable anchors for the scene's appearance and geometry. To maintain long-range geometric consistency, the model 1) jointly handles image and depth in a shared latent space, 2) explicitly conditions on the existing scene geometry (i.e., rendered point clouds) from previously generated keyframes, and 3) steers the sampling process with a warp-consistent guidance. Given high-quality RGB-D keyframes, a video diffusion model then interpolates between them to produce dense and coherent video frames. AutoScape generates realistic and geometrically consistent driving videos of over 20 seconds, improving the long-horizon FID and FVD scores over the prior state-of-the-art by 48.6\% and 43.0\%, respectively.
LANGTRAJ: Diffusion Model and Dataset for Language-Conditioned Trajectory Simulation
Apr 15, 2025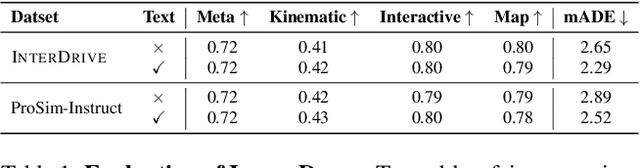
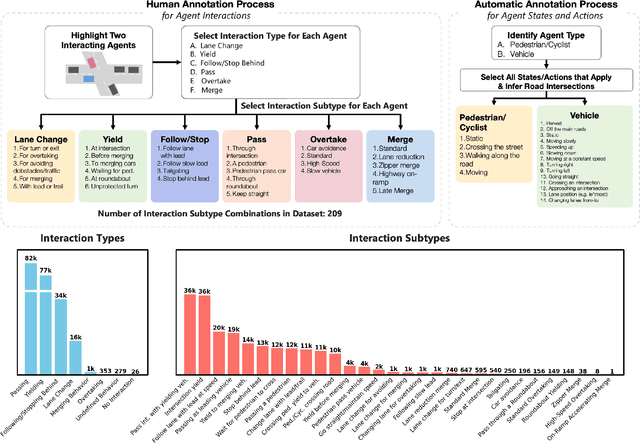
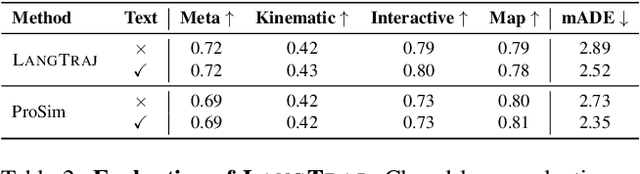
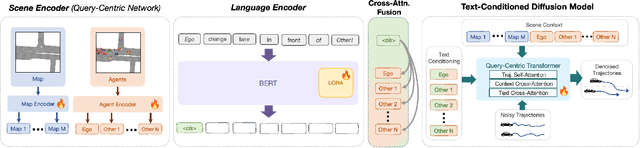
Evaluating autonomous vehicles with controllability enables scalable testing in counterfactual or structured settings, enhancing both efficiency and safety. We introduce LangTraj, a language-conditioned scene-diffusion model that simulates the joint behavior of all agents in traffic scenarios. By conditioning on natural language inputs, LangTraj provides flexible and intuitive control over interactive behaviors, generating nuanced and realistic scenarios. Unlike prior approaches that depend on domain-specific guidance functions, LangTraj incorporates language conditioning during training, facilitating more intuitive traffic simulation control. We propose a novel closed-loop training strategy for diffusion models, explicitly tailored to enhance stability and realism during closed-loop simulation. To support language-conditioned simulation, we develop Inter-Drive, a large-scale dataset with diverse and interactive labels for training language-conditioned diffusion models. Our dataset is built upon a scalable pipeline for annotating agent-agent interactions and single-agent behaviors, ensuring rich and varied supervision. Validated on the Waymo Motion Dataset, LangTraj demonstrates strong performance in realism, language controllability, and language-conditioned safety-critical simulation, establishing a new paradigm for flexible and scalable autonomous vehicle testing.