 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Doppler Shifts in Radial-Velocity Data with Deep Learning toward Earth-mass Exoplanet Detection
Jun 16, 2026Detecting the tiny Doppler shifts induced by Earth-mass planets in stellar radial-velocity measurements remains extremely challenging due to stellar activity. Many deep-learning methods performing well on simulated data remain difficult to apply reliably on real stellar spectra. The aim of this work is to develop a deep-learning framework that generalizes to real, unseen spectra and improves the detectability of Earth-mass planets in radial-velocity data. We train artificial neural networks on HARPS-N solar spectra with injected planetary signals, using physics-motivated spectral representations based on flux and line-formation temperature, together with their velocity gradients. Two training strategies are explored: hold-out testing and cross-validation. Model robustness is enhanced through genetic-algorithm-based hyperparameter optimization, and predictive uncertainty is quantified using Monte Carlo dropout. Our most precise neural network model reliably retrieves, under the cross-validation strategy, the amplitudes, phases, and orbital periods of planetary signals with amplitudes greater than or equal to 25 cm/s and periods between 10 and 550 days. In addition, in all cases tested here, the successfully recovered signals correspond to the most significant peaks in the periodograms of the Doppler-shift predictions. Temperature-based spectral-shell representations consistently outperform flux-based shells. We also release doppleriann, a Python package implementing the proposed framework. Our results demonstrate that combining physically motivated spectral representations with deep learning provides a promising pathway toward the detection of Earth-mass planets in radial-velocity data from real observations, supported by a modeling framework that is both physically grounded and statistically rigorous, incorporating uncertainty quantification and optimized training strategies.
Improving Earth-like planet detection in radial velocity using deep learning
May 21, 2024



Many novel methods have been proposed to mitigate stellar activity for exoplanet detection as the presence of stellar activity in radial velocity (RV) measurements is the current major limitation. Unlike traditional methods that model stellar activity in the RV domain, more methods are moving in the direction of disentangling stellar activity at the spectral level. The goal of this paper is to present a novel convolutional neural network-based algorithm that efficiently models stellar activity signals at the spectral level, enhancing the detection of Earth-like planets. We trained a convolutional neural network to build the correlation between the change in the spectral line profile and the corresponding RV, full width at half maximum (FWHM) and bisector span (BIS) values derived from the classical cross-correlation function. This algorithm has been tested on three intensively observed stars: Alpha Centauri B (HD128621), Tau ceti (HD10700), and the Sun. By injecting simulated planetary signals at the spectral level, we demonstrate that our machine learning algorithm can achieve, for HD128621 and HD10700, a detection threshold of 0.5 m/s in semi-amplitude for planets with periods ranging from 10 to 300 days. This threshold would correspond to the detection of a $\sim$4$\mathrm{M}_{\oplus}$ in the habitable zone of those stars. On the HARPS-N solar dataset, our algorithm is even more efficient at mitigating stellar activity signals and can reach a threshold of 0.2 m/s, which would correspond to a 2.2$\mathrm{M}_{\oplus}$ planet on the orbit of the Earth. To the best of our knowledge, it is the first time that such low detection thresholds are reported for the Sun, but also for other stars, and therefore this highlights the efficiency of our convolutional neural network-based algorithm at mitigating stellar activity in RV measurements.
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
Dec 29, 2023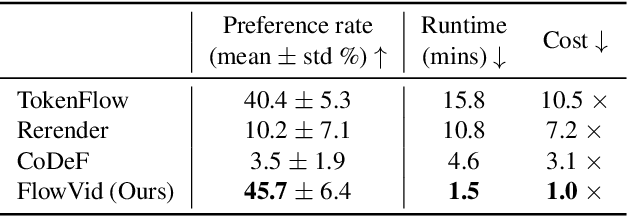

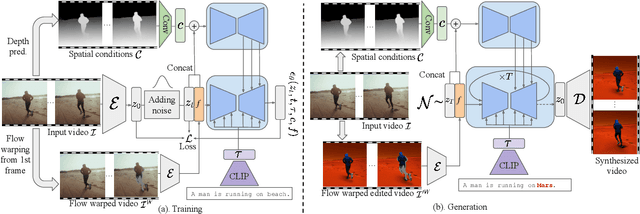

Diffusion models have transformed the image-to-image (I2I) synthesis and are now permeating into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames. This paper proposes a consistent V2V synthesis framework by jointly leveraging spatial conditions and temporal optical flow clues within the source video. Contrary to prior methods that strictly adhere to optical flow, our approach harnesses its benefits while handling the imperfection in flow estimation. We encode the optical flow via warping from the first frame and serve it as a supplementary reference in the diffusion model. This enables our model for video synthesis by editing the first frame with any prevalent I2I models and then propagating edits to successive frames. Our V2V model, FlowVid, demonstrates remarkable properties: (1) Flexibility: FlowVid works seamlessly with existing I2I models, facilitating various modifications, including stylization, object swaps, and local edits. (2) Efficiency: Generation of a 4-second video with 30 FPS and 512x512 resolution takes only 1.5 minutes, which is 3.1x, 7.2x, and 10.5x faster than CoDeF, Rerender, and TokenFlow, respectively. (3) High-quality: In user studies, our FlowVid is preferred 45.7% of the time, outperforming CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).
Discovery of Small Ultra-short-period Planets Orbiting KG Dwarfs in Kepler Survey Using GPU Phase Folding and Deep Learning Detection System
Dec 28, 2023Since the discovery of the first hot Jupiter orbiting a solar-type star, 51 Peg, in 1995, more than 4000 exoplanets have been identified using various observational techniques. The formation process of these sub-Earths remains elusive, and acquiring additional samples is essential for investigating this unique population. In our study, we employ a novel GPU Phase Folding algorithm combined with a Convolutional Neural Network, termed the GPFC method, on Kepler photometry data. This method enhances the transit search speed significantly over the traditional Box-fitting Least Squares method, allowing a complete search of the known KOI photometry data within hours using a commercial GPU card. To date, we have identified five promising sub-Earth short-period candidates: K00446.c, K01821.b, K01522.c, K03404.b, and K04978.b. A closer analysis reveals the following characteristics: K00446.c orbits a K dwarf on a 0.645091-day period. With a radius of $0.461R_\oplus$, it ranks as the second smallest USP discovered to date. K01821.b is a sub-Earth with a radius of $0.648R_\oplus$, orbiting a G dwarf over a 0.91978-day period. It is the second smallest USP among all confirmed USPs orbiting G dwarfs in the NASA Archive. K01522.c has a radius of $0.704 R_\oplus$ and completes an orbit around a Sun-like G dwarf in 0.64672 days; K03404.b, with a radius of $0.738 R_\oplus$, orbits a G dwarf on a 0.68074-day period; and K04978.b, with its planetary radius of $0.912 R_\oplus$, orbits a G dwarf, completing an orbit every 0.94197 days. Three of our finds, K01821.b, K01522.c and K03404.b, rank as the smallest planets among all confirmed USPs orbiting G dwarfs in the Kepler dataset. The discovery of these small exoplanets underscores the promising capability of the GPFC method for searching for small, new transiting exoplanets in photometry data from Kepler, TESS, and future space transit missions.
AVID: Any-Length Video Inpainting with Diffusion Model
Dec 06, 2023



Recent advances in diffusion models have successfully enabled text-guided image inpainting. While it seems straightforward to extend such editing capability into video domain, there has been fewer works regarding text-guided video inpainting. Given a video, a masked region at its initial frame, and an editing prompt, it requires a model to do infilling at each frame following the editing guidance while keeping the out-of-mask region intact. There are three main challenges in text-guided video inpainting: ($i$) temporal consistency of the edited video, ($ii$) supporting different inpainting types at different structural fidelity level, and ($iii$) dealing with variable video length. To address these challenges, we introduce Any-Length Video Inpainting with Diffusion Model, dubbed as AVID. At its core, our model is equipped with effective motion modules and adjustable structure guidance, for fixed-length video inpainting. Building on top of that, we propose a novel Temporal MultiDiffusion sampling pipeline with an middle-frame attention guidance mechanism, facilitating the generation of videos with any desired duration. Our comprehensive experiments show our model can robustly deal with various inpainting types at different video duration range, with high quality. More visualization results is made publicly available at https://zhang-zx.github.io/AVID/ .
The GPU Phase Folding and Deep Learning Method for Detecting Exoplanet Transits
Dec 04, 2023



This paper presents GPFC, a novel Graphics Processing Unit (GPU) Phase Folding and Convolutional Neural Network (CNN) system to detect exoplanets using the transit method. We devise a fast folding algorithm parallelized on a GPU to amplify low signal-to-noise ratio transit signals, allowing a search at high precision and speed. A CNN trained on two million synthetic light curves reports a score indicating the likelihood of a planetary signal at each period. GPFC improves on speed by three orders of magnitude over the predominant Box-fitting Least Squares (BLS) method. Our simulation results show GPFC achieves 97% training accuracy, higher true positive rate at the same false positive rate of detection, and higher precision at the same recall rate when compared to BLS. GPFC recovers 100% of known ultra-short-period planets in Kepler light curves from a blind search. These results highlight the promise of GPFC as an alternative approach to the traditional BLS algorithm for finding new transiting exoplanets in data taken with Kepler and other space transit missions such as K2, TESS and future PLATO and Earth 2.0.
Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
Oct 09, 2022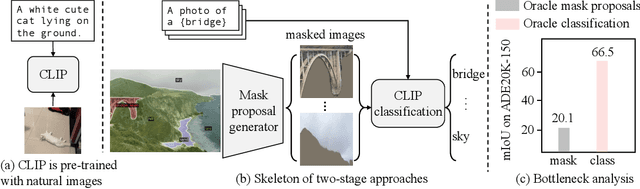
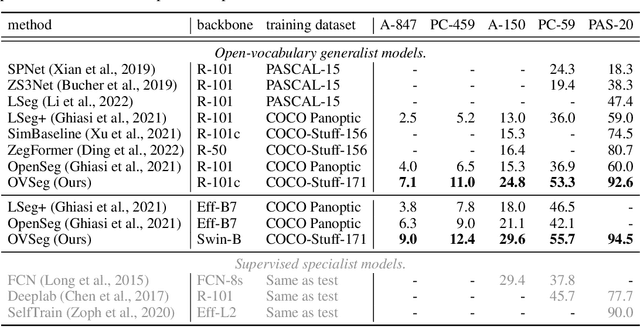
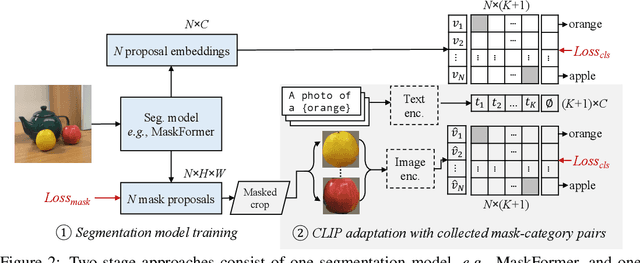
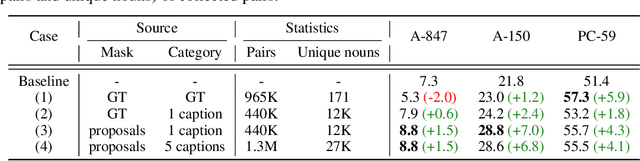
Open-vocabulary semantic segmentation aims to segment an image into semantic regions according to text descriptions, which may not have been seen during training. Recent two-stage methods first generate class-agnostic mask proposals and then leverage pre-trained vision-language models, e.g., CLIP, to classify masked regions. We identify the performance bottleneck of this paradigm to be the pre-trained CLIP model, since it does not perform well on masked images. To address this, we propose to finetune CLIP on a collection of masked image regions and their corresponding text descriptions. We collect training data by mining an existing image-caption dataset (e.g., COCO Captions), using CLIP to match masked image regions to nouns in the image captions. Compared with the more precise and manually annotated segmentation labels with fixed classes (e.g., COCO-Stuff), we find our noisy but diverse dataset can better retain CLIP's generalization ability. Along with finetuning the entire model, we utilize the "blank" areas in masked images using a method we dub mask prompt tuning. Experiments demonstrate mask prompt tuning brings significant improvement without modifying any weights of CLIP, and it can further improve a fully finetuned model. In particular, when trained on COCO and evaluated on ADE20K-150, our best model achieves 29.6% mIoU, which is +8.5% higher than the previous state-of-the-art. For the first time, open-vocabulary generalist models match the performance of supervised specialist models in 2017 without dataset-specific adaptations.
Human Behavior Recognition Method Based on CEEMD-ES Radar Selection
Jun 06, 2022
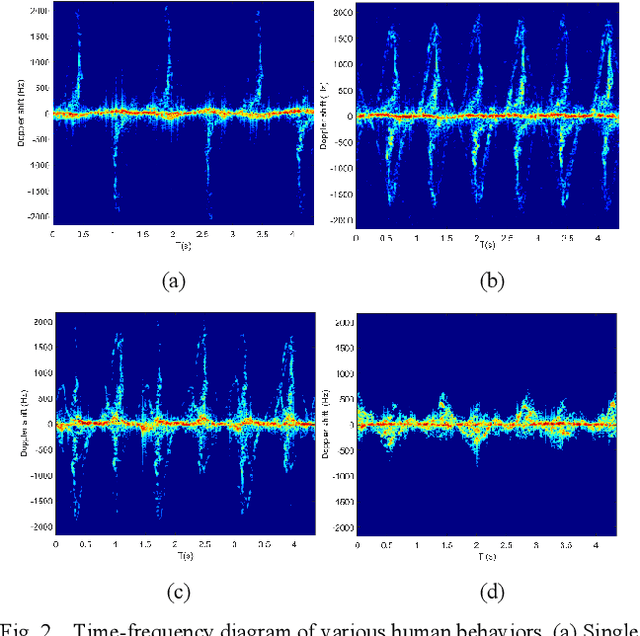
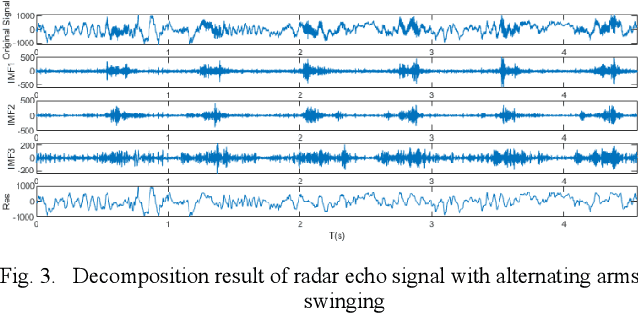
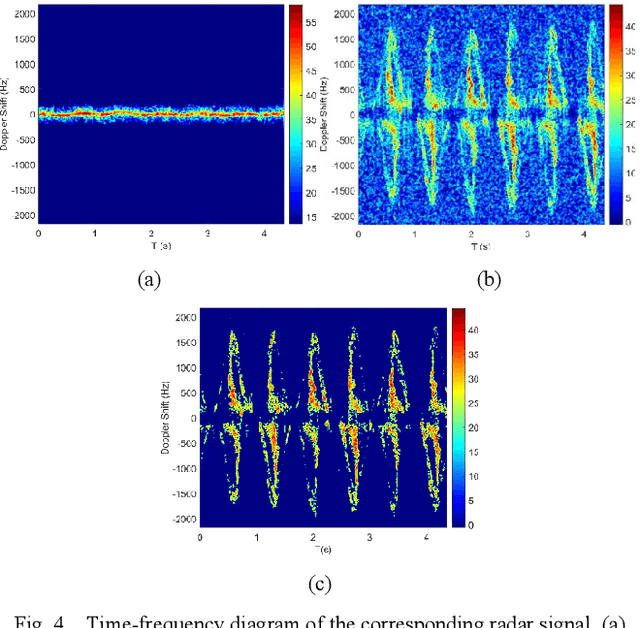
In recent years, the millimeter-wave radar to identify human behavior has been widely used in medical,security, and other fields. When multiple radars are performing detection tasks, the validity of the features contained in each radar is difficult to guarantee. In addition, processing multiple radar data also requires a lot of time and computational cost. The Complementary Ensemble Empirical Mode Decomposition-Energy Slice (CEEMD-ES) multistatic radar selection method is proposed to solve these problems. First, this method decomposes and reconstructs the radar signal according to the difference in the reflected echo frequency between the limbs and the trunk of the human body. Then, the radar is selected according to the difference between the ratio of echo energy of limbs and trunk and the theoretical value. The time domain, frequency domain and various entropy features of the selected radar are extracted. Finally, the Extreme Learning Machine (ELM) recognition model of the ReLu core is established. Experiments show that this method can effectively select the radar, and the recognition rate of three kinds of human actions is 98.53%.
Generalized Few-Shot Semantic Segmentation: All You Need is Fine-Tuning
Dec 21, 2021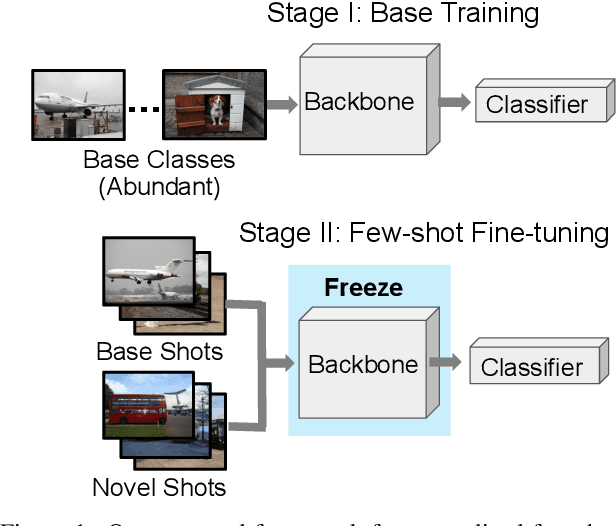
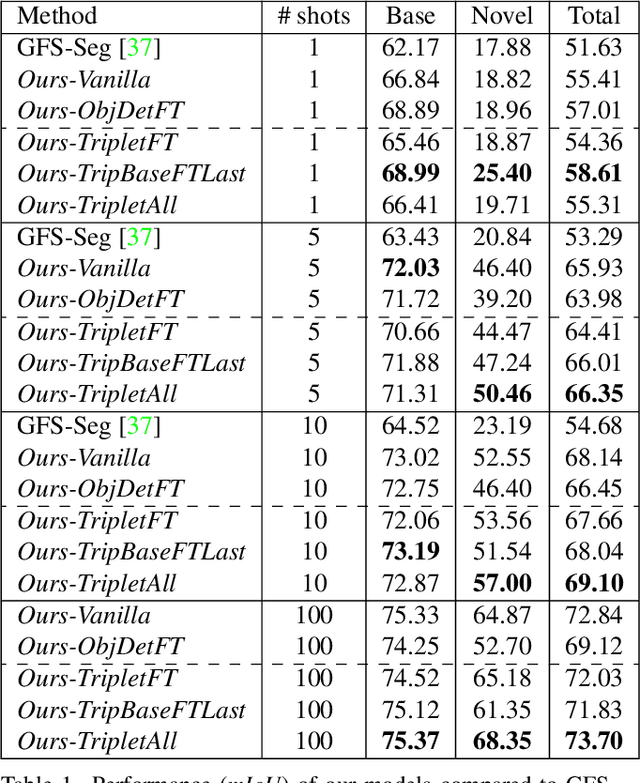
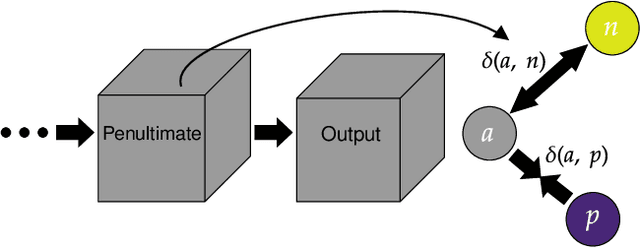
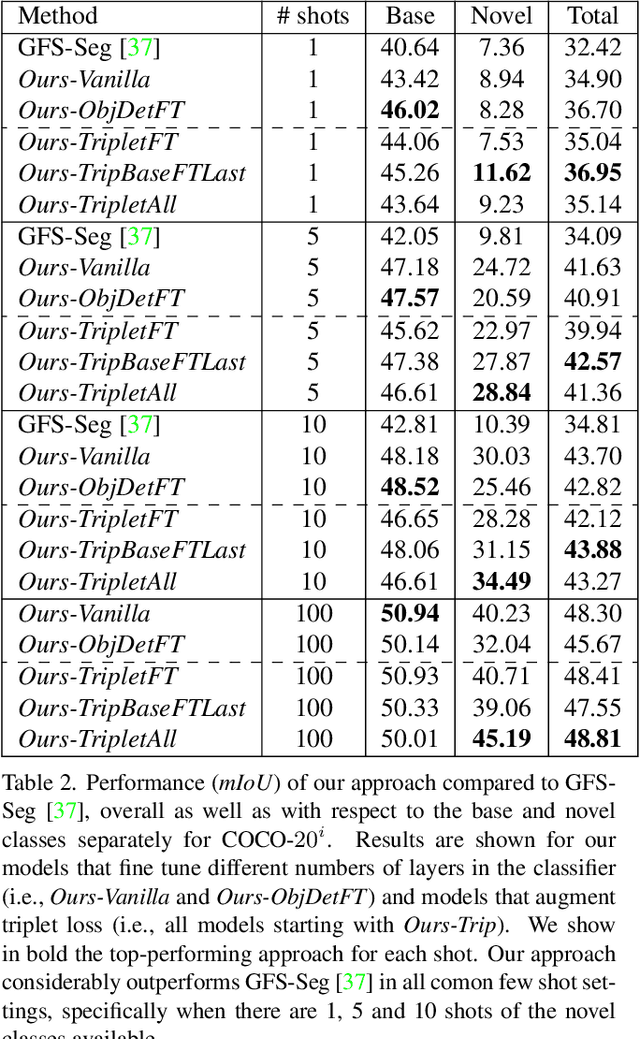
Generalized few-shot semantic segmentation was introduced to move beyond only evaluating few-shot segmentation models on novel classes to include testing their ability to remember base classes. While all approaches currently are based on meta-learning, they perform poorly and saturate in learning after observing only a few shots. We propose the first fine-tuning solution, and demonstrate that it addresses the saturation problem while achieving state-of-art results on two datasets, PASCAL-$5^i$ and COCO-$20^i$. We also show it outperforms existing methods whether fine-tuning multiple final layers or only the final layer. Finally, we present a triplet loss regularization that shows how to redistribute the balance of performance between novel and base categories so that there is a smaller gap between them.
A novel partially-decoupled translational parallel manipulator with symbolic kinematics, singularity identification and workspace determination
Jun 08, 2021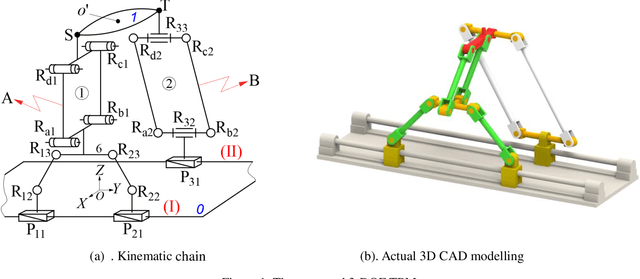

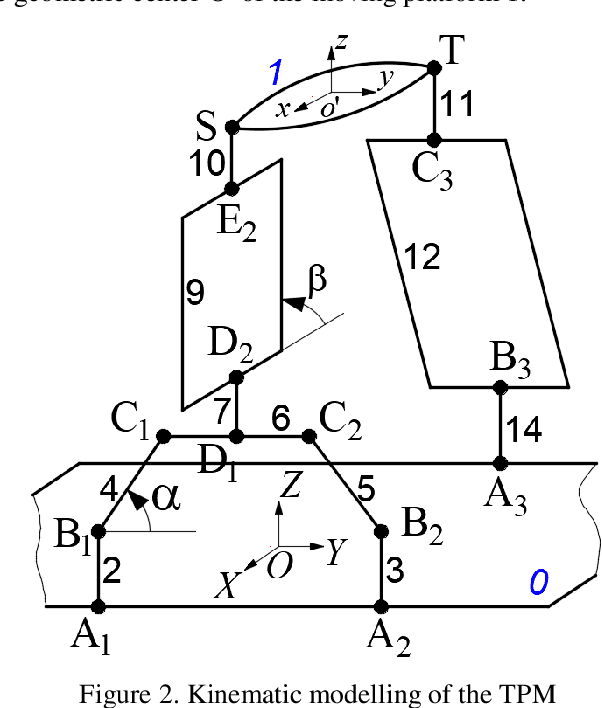
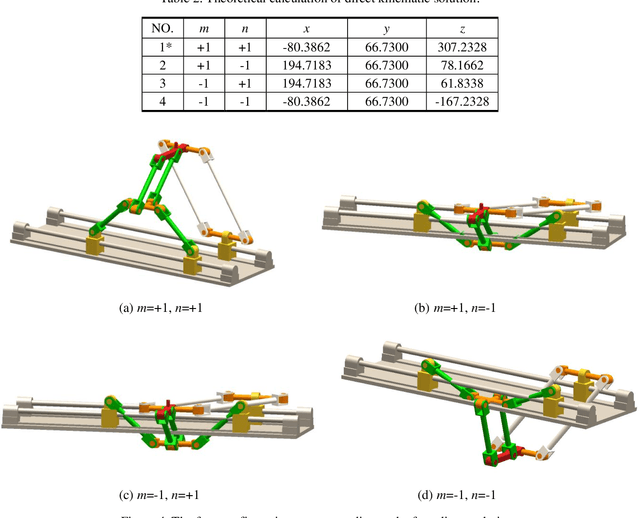
This paper presents a novel three-degree-of-freedom (3-DOF) translational parallel manipulator (TPM) by using a topological design method of parallel mechanism (PM) based on position and orientation characteristic (POC) equations. The proposed PM is only composed of lower-mobility joints and actuated prismatic joints, together with the investigations on three kinematic issues of importance. The first aspect pertains to geometric modeling of the TPM in connection with its topological characteristics, such as the POC, degree of freedom and coupling degree, from which its symbolic direct kinematic solutions are readily obtained. Moreover, the decoupled properties of input-output motions are directly evaluated without Jacobian analysis. Sequentially, based upon the inverse kinematics, the singular configurations of the TPM are identified, wherein the singular surfaces are visualized by means of a Gr{\"o}bner based elimination operation. Finally, the workspace of the TPM is evaluated with a geometric approach. This 3-DOF TPM features less joints and links compared with the well-known Delta robot, which reduces the structural complexity. Its symbolic direct kinematics and partially-decoupled property will ease path planning and dynamic analysis. The TPM can be used for manufacturing large work pieces.