 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuliang Liu
Progressive Evolution from Single-Point to Polygon for Scene Text
Dec 21, 2023
The advancement of text shape representations towards compactness has enhanced text detection and spotting performance, but at a high annotation cost. Current models use single-point annotations to reduce costs, yet they lack sufficient localization information for downstream applications. To overcome this limitation, we introduce Point2Polygon, which can efficiently transform single-points into compact polygons. Our method uses a coarse-to-fine process, starting with creating and selecting anchor points based on recognition confidence, then vertically and horizontally refining the polygon using recognition information to optimize its shape. We demonstrate the accuracy of the generated polygons through extensive experiments: 1) By creating polygons from ground truth points, we achieved an accuracy of 82.0% on ICDAR 2015; 2) In training detectors with polygons generated by our method, we attained 86% of the accuracy relative to training with ground truth (GT); 3) Additionally, the proposed Point2Polygon can be seamlessly integrated to empower single-point spotters to generate polygons. This integration led to an impressive 82.5% accuracy for the generated polygons. It is worth mentioning that our method relies solely on synthetic recognition information, eliminating the need for any manual annotation beyond single points.
Toward Real Text Manipulation Detection: New Dataset and New Solution
Dec 12, 2023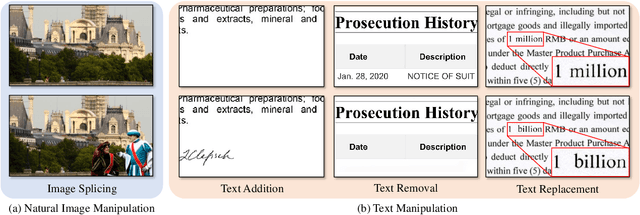
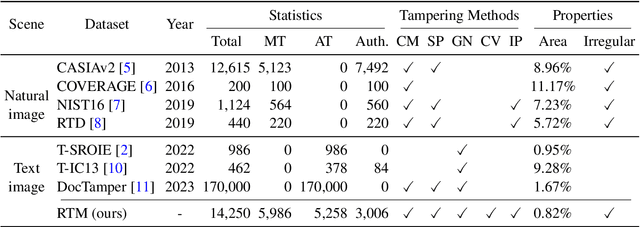

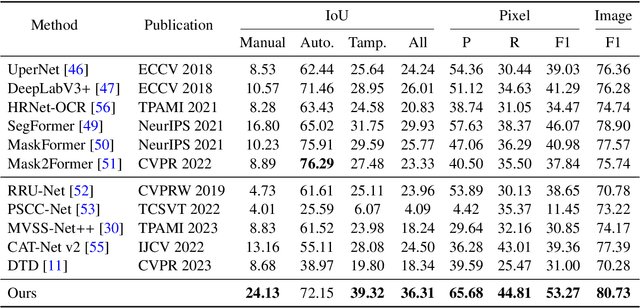
With the surge in realistic text tampering, detecting fraudulent text in images has gained prominence for maintaining information security. However, the high costs associated with professional text manipulation and annotation limit the availability of real-world datasets, with most relying on synthetic tampering, which inadequately replicates real-world tampering attributes. To address this issue, we present the Real Text Manipulation (RTM) dataset, encompassing 14,250 text images, which include 5,986 manually and 5,258 automatically tampered images, created using a variety of techniques, alongside 3,006 unaltered text images for evaluating solution stability. Our evaluations indicate that existing methods falter in text forgery detection on the RTM dataset. We propose a robust baseline solution featuring a Consistency-aware Aggregation Hub and a Gated Cross Neighborhood-attention Fusion module for efficient multi-modal information fusion, supplemented by a Tampered-Authentic Contrastive Learning module during training, enriching feature representation distinction. This framework, extendable to other dual-stream architectures, demonstrated notable localization performance improvements of 7.33% and 6.38% on manual and overall manipulations, respectively. Our contributions aim to propel advancements in real-world text tampering detection. Code and dataset will be made available at https://github.com/DrLuo/RTM
Enhancing Scene Text Detectors with Realistic Text Image Synthesis Using Diffusion Models
Nov 28, 2023Scene text detection techniques have garnered significant attention due to their wide-ranging applications. However, existing methods have a high demand for training data, and obtaining accurate human annotations is labor-intensive and time-consuming. As a solution, researchers have widely adopted synthetic text images as a complementary resource to real text images during pre-training. Yet there is still room for synthetic datasets to enhance the performance of scene text detectors. We contend that one main limitation of existing generation methods is the insufficient integration of foreground text with the background. To alleviate this problem, we present the Diffusion Model based Text Generator (DiffText), a pipeline that utilizes the diffusion model to seamlessly blend foreground text regions with the background's intrinsic features. Additionally, we propose two strategies to generate visually coherent text with fewer spelling errors. With fewer text instances, our produced text images consistently surpass other synthetic data in aiding text detectors. Extensive experiments on detecting horizontal, rotated, curved, and line-level texts demonstrate the effectiveness of DiffText in producing realistic text images.
Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
Nov 24, 2023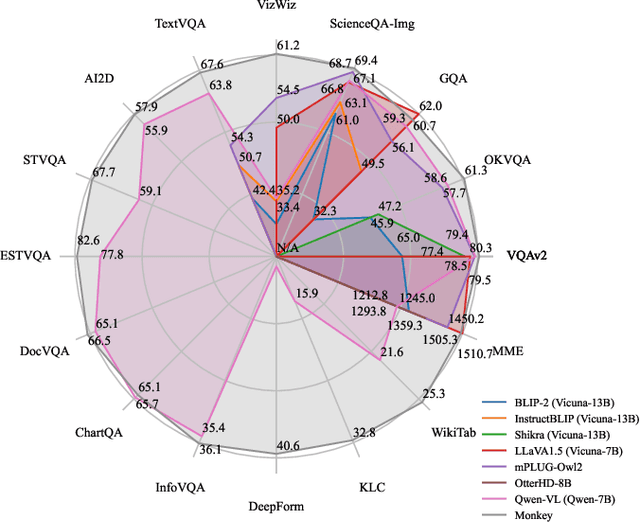
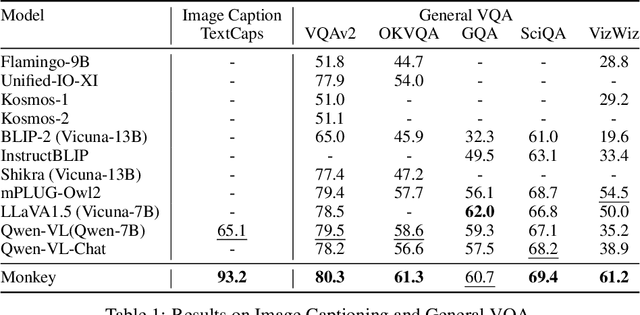
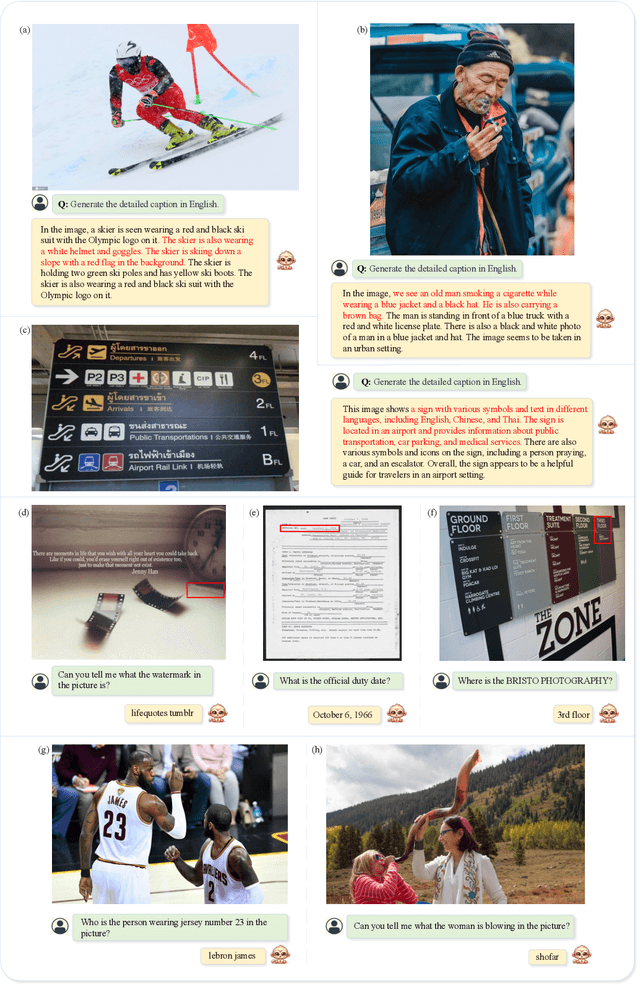
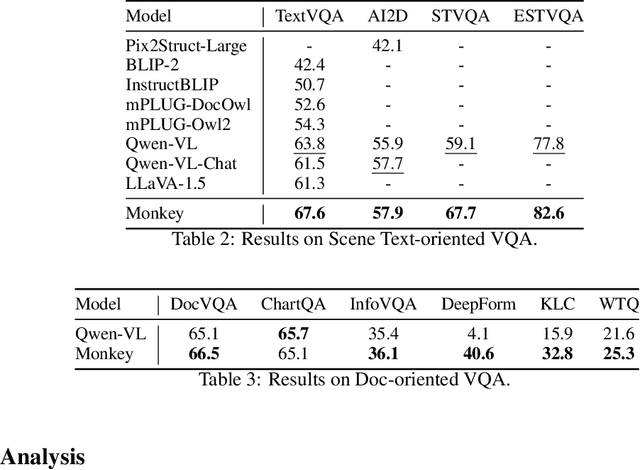
Large Multimodal Models (LMMs) have shown promise in vision-language tasks but struggle with high-resolution input and detailed scene understanding. Addressing these challenges, we introduce Monkey to enhance LMM capabilities. Firstly, Monkey processes input images by dividing them into uniform patches, each matching the size (e.g., 448x448) used in the original training of the well-trained vision encoder. Equipped with individual adapter for each patch, Monkey can handle higher resolutions up to 1344x896 pixels, enabling the detailed capture of complex visual information. Secondly, it employs a multi-level description generation method, enriching the context for scene-object associations. This two-part strategy ensures more effective learning from generated data: the higher resolution allows for a more detailed capture of visuals, which in turn enhances the effectiveness of comprehensive descriptions. Extensive ablative results validate the effectiveness of our designs. Additionally, experiments on 18 datasets further demonstrate that Monkey surpasses existing LMMs in many tasks like Image Captioning and various Visual Question Answering formats. Specially, in qualitative tests focused on dense text question answering, Monkey has exhibited encouraging results compared with GPT4V. Code is available at https://github.com/Yuliang-Liu/Monkey.
ML-Bench: Large Language Models Leverage Open-source Libraries for Machine Learning Tasks
Nov 16, 2023Large language models have shown promising performance in code generation benchmarks. However, a considerable divide exists between these benchmark achievements and their practical applicability, primarily attributed to real-world programming's reliance on pre-existing libraries. Instead of evaluating LLMs to code from scratch, this work aims to propose a new evaluation setup where LLMs use open-source libraries to finish machine learning tasks. Therefore, we propose ML-Bench, an expansive benchmark developed to assess the effectiveness of LLMs in leveraging existing functions in open-source libraries. Consisting of 10044 samples spanning 130 tasks over 14 notable machine learning GitHub repositories. In this setting, given a specific machine learning task instruction and the accompanying README in a codebase, an LLM is tasked to generate code to accomplish the task. This necessitates the comprehension of long and language-code interleaved documents, as well as the understanding of complex cross-file code structures, introducing new challenges. Notably, while GPT-4 exhibits remarkable improvement over other LLMs, it manages to accomplish only 39.73\% of the tasks, leaving a huge space for improvement. We address these challenges by proposing ML-Agent, designed to effectively navigate the codebase, locate documentation, retrieve code, and generate executable code. Empirical results demonstrate that ML-Agent, built upon GPT-4, results in further improvements. Code, data, and models are available at \url{https://ml-bench.github.io/}.
KwaiYiiMath: Technical Report
Oct 19, 2023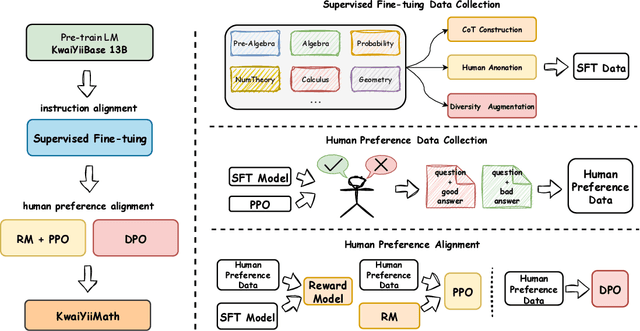
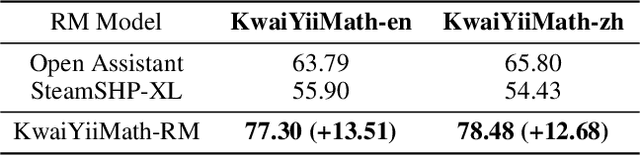
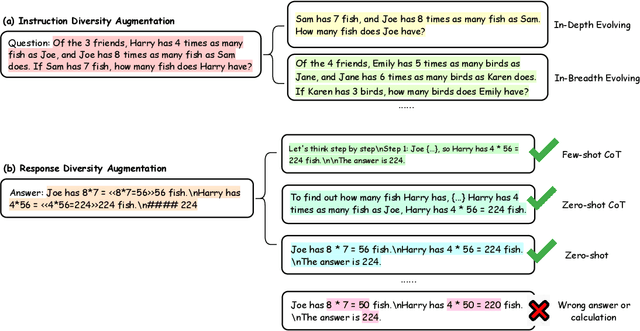

Recent advancements in large language models (LLMs) have demonstrated remarkable abilities in handling a variety of natural language processing (NLP) downstream tasks, even on mathematical tasks requiring multi-step reasoning. In this report, we introduce the KwaiYiiMath which enhances the mathematical reasoning abilities of KwaiYiiBase1, by applying Supervised Fine-Tuning (SFT) and Reinforced Learning from Human Feedback (RLHF), including on both English and Chinese mathematical tasks. Meanwhile, we also constructed a small-scale Chinese primary school mathematics test set (named KMath), consisting of 188 examples to evaluate the correctness of the problem-solving process generated by the models. Empirical studies demonstrate that KwaiYiiMath can achieve state-of-the-art (SOTA) performance on GSM8k, CMath, and KMath compared with the similar size models, respectively.
Turning a CLIP Model into a Scene Text Spotter
Aug 21, 2023
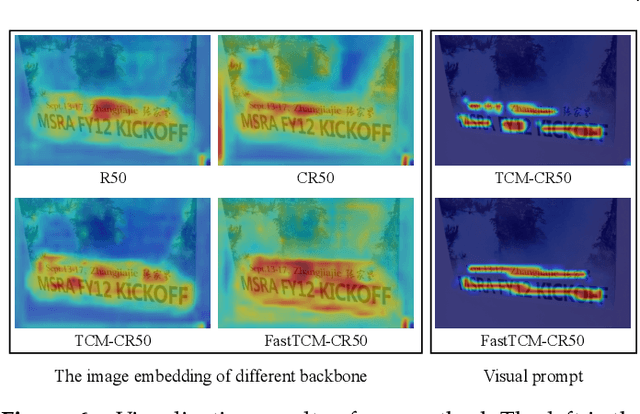
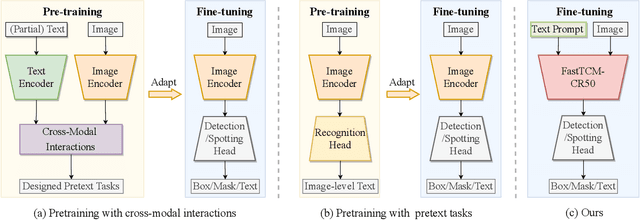
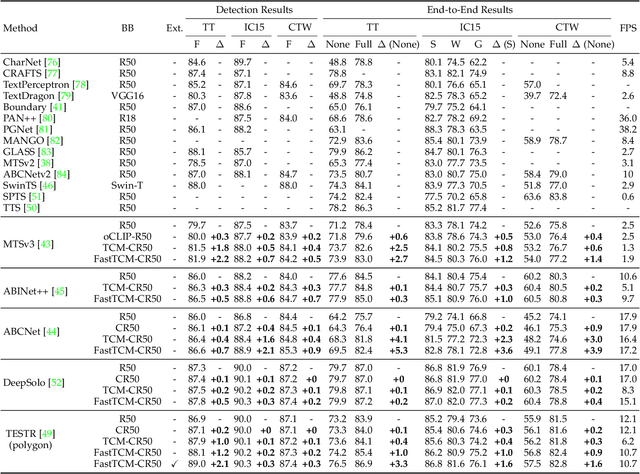
We exploit the potential of the large-scale Contrastive Language-Image Pretraining (CLIP) model to enhance scene text detection and spotting tasks, transforming it into a robust backbone, FastTCM-CR50. This backbone utilizes visual prompt learning and cross-attention in CLIP to extract image and text-based prior knowledge. Using predefined and learnable prompts, FastTCM-CR50 introduces an instance-language matching process to enhance the synergy between image and text embeddings, thereby refining text regions. Our Bimodal Similarity Matching (BSM) module facilitates dynamic language prompt generation, enabling offline computations and improving performance. FastTCM-CR50 offers several advantages: 1) It can enhance existing text detectors and spotters, improving performance by an average of 1.7% and 1.5%, respectively. 2) It outperforms the previous TCM-CR50 backbone, yielding an average improvement of 0.2% and 0.56% in text detection and spotting tasks, along with a 48.5% increase in inference speed. 3) It showcases robust few-shot training capabilities. Utilizing only 10% of the supervised data, FastTCM-CR50 improves performance by an average of 26.5% and 5.5% for text detection and spotting tasks, respectively. 4) It consistently enhances performance on out-of-distribution text detection and spotting datasets, particularly the NightTime-ArT subset from ICDAR2019-ArT and the DOTA dataset for oriented object detection. The code is available at https://github.com/wenwenyu/TCM.
ESTextSpotter: Towards Better Scene Text Spotting with Explicit Synergy in Transformer
Aug 20, 2023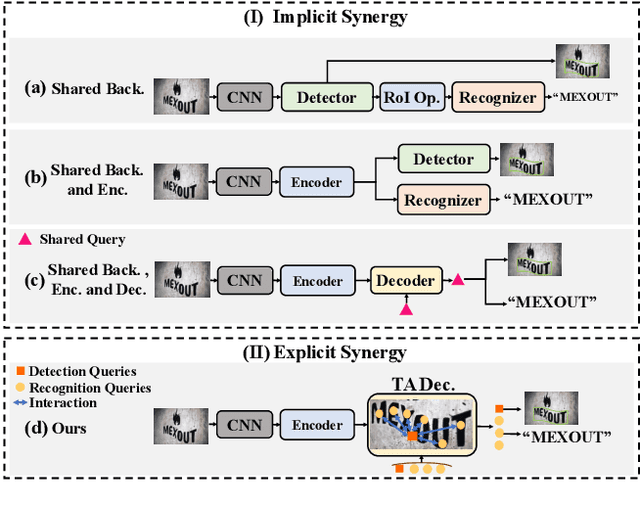
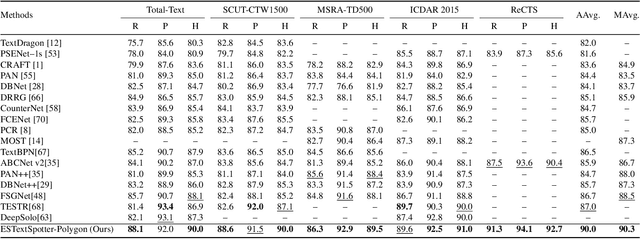
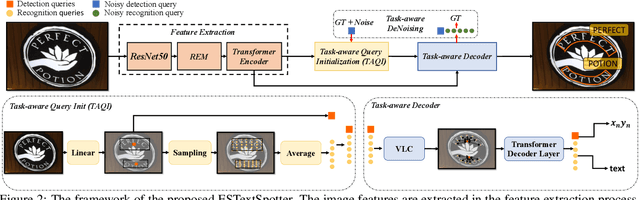
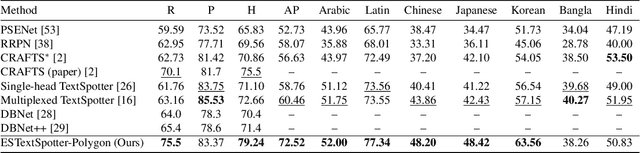
In recent years, end-to-end scene text spotting approaches are evolving to the Transformer-based framework. While previous studies have shown the crucial importance of the intrinsic synergy between text detection and recognition, recent advances in Transformer-based methods usually adopt an implicit synergy strategy with shared query, which can not fully realize the potential of these two interactive tasks. In this paper, we argue that the explicit synergy considering distinct characteristics of text detection and recognition can significantly improve the performance text spotting. To this end, we introduce a new model named Explicit Synergy-based Text Spotting Transformer framework (ESTextSpotter), which achieves explicit synergy by modeling discriminative and interactive features for text detection and recognition within a single decoder. Specifically, we decompose the conventional shared query into task-aware queries for text polygon and content, respectively. Through the decoder with the proposed vision-language communication module, the queries interact with each other in an explicit manner while preserving discriminative patterns of text detection and recognition, thus improving performance significantly. Additionally, we propose a task-aware query initialization scheme to ensure stable training. Experimental results demonstrate that our model significantly outperforms previous state-of-the-art methods. Code is available at https://github.com/mxin262/ESTextSpotter.