 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleGuardian: A Framework for Automatic RespiratorySound classification Based on Improved Deep clustering and Contrastive Learning
Feb 02, 2025Auscultation plays a pivotal role in early respiratory and pulmonary disease diagnosis. Despite the emergence of deep learning-based methods for automatic respiratory sound classification post-Covid-19, limited datasets impede performance enhancement. Distinguishing between normal and abnormal respiratory sounds poses challenges due to the coexistence of normal respiratory components and noise components in both types. Moreover, different abnormal respiratory sounds exhibit similar anomalous features, hindering their differentiation. Besides, existing state-of-the-art models suffer from excessive parameter size, impeding deployment on resource-constrained mobile platforms. To address these issues, we design a lightweight network CycleGuardian and propose a framework based on an improved deep clustering and contrastive learning. We first generate a hybrid spectrogram for feature diversity and grouping spectrograms to facilitating intermittent abnormal sound capture.Then, CycleGuardian integrates a deep clustering module with a similarity-constrained clustering component to improve the ability to capture abnormal features and a contrastive learning module with group mixing for enhanced abnormal feature discernment. Multi-objective optimization enhances overall performance during training. In experiments we use the ICBHI2017 dataset, following the official split method and without any pre-trained weights, our method achieves Sp: 82.06 $\%$, Se: 44.47$\%$, and Score: 63.26$\%$ with a network model size of 38M, comparing to the current model, our method leads by nearly 7$\%$, achieving the current best performances. Additionally, we deploy the network on Android devices, showcasing a comprehensive intelligent respiratory sound auscultation system.
OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
Dec 31, 2024



Scoring the Optical Character Recognition (OCR) capabilities of Large Multimodal Models (LMMs) has witnessed growing interest recently. Existing benchmarks have highlighted the impressive performance of LMMs in text recognition; however, their abilities on certain challenging tasks, such as text localization, handwritten content extraction, and logical reasoning, remain underexplored. To bridge this gap, we introduce OCRBench v2, a large-scale bilingual text-centric benchmark with currently the most comprehensive set of tasks (4x more tasks than the previous multi-scene benchmark OCRBench), the widest coverage of scenarios (31 diverse scenarios including street scene, receipt, formula, diagram, and so on), and thorough evaluation metrics, with a total of 10,000 human-verified question-answering pairs and a high proportion of difficult samples. After carefully benchmarking state-of-the-art LMMs on OCRBench v2, we find that 20 out of 22 LMMs score below 50 (100 in total) and suffer from five-type limitations, including less frequently encountered text recognition, fine-grained perception, layout perception, complex element parsing, and logical reasoning. The benchmark and evaluation scripts are available at https://github.com/Yuliang-liu/MultimodalOCR.
SceneGenAgent: Precise Industrial Scene Generation with Coding Agent
Oct 29, 2024The modeling of industrial scenes is essential for simulations in industrial manufacturing. While large language models (LLMs) have shown significant progress in generating general 3D scenes from textual descriptions, generating industrial scenes with LLMs poses a unique challenge due to their demand for precise measurements and positioning, requiring complex planning over spatial arrangement. To address this challenge, we introduce SceneGenAgent, an LLM-based agent for generating industrial scenes through C# code. SceneGenAgent ensures precise layout planning through a structured and calculable format, layout verification, and iterative refinement to meet the quantitative requirements of industrial scenarios. Experiment results demonstrate that LLMs powered by SceneGenAgent exceed their original performance, reaching up to 81.0% success rate in real-world industrial scene generation tasks and effectively meeting most scene generation requirements. To further enhance accessibility, we construct SceneInstruct, a dataset designed for fine-tuning open-source LLMs to integrate into SceneGenAgent. Experiments show that fine-tuning open-source LLMs on SceneInstruct yields significant performance improvements, with Llama3.1-70B approaching the capabilities of GPT-4o. Our code and data are available at https://github.com/THUDM/SceneGenAgent .
Dataset and Benchmark for Urdu Natural Scenes Text Detection, Recognition and Visual Question Answering
May 21, 2024The development of Urdu scene text detection, recognition, and Visual Question Answering (VQA) technologies is crucial for advancing accessibility, information retrieval, and linguistic diversity in digital content, facilitating better understanding and interaction with Urdu-language visual data. This initiative seeks to bridge the gap between textual and visual comprehension. We propose a new multi-task Urdu scene text dataset comprising over 1000 natural scene images, which can be used for text detection, recognition, and VQA tasks. We provide fine-grained annotations for text instances, addressing the limitations of previous datasets for facing arbitrary-shaped texts. By incorporating additional annotation points, this dataset facilitates the development and assessment of methods that can handle diverse text layouts, intricate shapes, and non-standard orientations commonly encountered in real-world scenarios. Besides, the VQA annotations make it the first benchmark for the Urdu Text VQA method, which can prompt the development of Urdu scene text understanding. The proposed dataset is available at: https://github.com/Hiba-MeiRuan/Urdu-VQA-Dataset-/tree/main
The First Swahili Language Scene Text Detection and Recognition Dataset
May 19, 2024



Scene text recognition is essential in many applications, including automated translation, information retrieval, driving assistance, and enhancing accessibility for individuals with visual impairments. Much research has been done to improve the accuracy and performance of scene text detection and recognition models. However, most of this research has been conducted in the most common languages, English and Chinese. There is a significant gap in low-resource languages, especially the Swahili Language. Swahili is widely spoken in East African countries but is still an under-explored language in scene text recognition. No studies have been focused explicitly on Swahili natural scene text detection and recognition, and no dataset for Swahili language scene text detection and recognition is publicly available. We propose a comprehensive dataset of Swahili scene text images and evaluate the dataset on different scene text detection and recognition models. The dataset contains 976 images collected in different places and under various circumstances. Each image has its annotation at the word level. The proposed dataset can also serve as a benchmark dataset specific to the Swahili language for evaluating and comparing different approaches and fostering future research endeavors. The dataset is available on GitHub via this link: https://github.com/FadilaW/Swahili-STR-Dataset
Enhancing Scene Text Detectors with Realistic Text Image Synthesis Using Diffusion Models
Nov 28, 2023



Scene text detection techniques have garnered significant attention due to their wide-ranging applications. However, existing methods have a high demand for training data, and obtaining accurate human annotations is labor-intensive and time-consuming. As a solution, researchers have widely adopted synthetic text images as a complementary resource to real text images during pre-training. Yet there is still room for synthetic datasets to enhance the performance of scene text detectors. We contend that one main limitation of existing generation methods is the insufficient integration of foreground text with the background. To alleviate this problem, we present the Diffusion Model based Text Generator (DiffText), a pipeline that utilizes the diffusion model to seamlessly blend foreground text regions with the background's intrinsic features. Additionally, we propose two strategies to generate visually coherent text with fewer spelling errors. With fewer text instances, our produced text images consistently surpass other synthetic data in aiding text detectors. Extensive experiments on detecting horizontal, rotated, curved, and line-level texts demonstrate the effectiveness of DiffText in producing realistic text images.
Toward Understanding WordArt: Corner-Guided Transformer for Scene Text Recognition
Jul 31, 2022
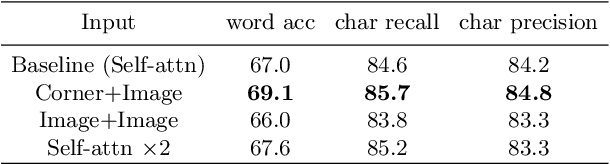
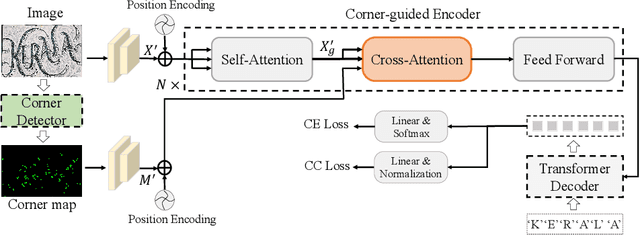
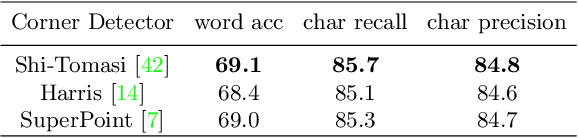
Artistic text recognition is an extremely challenging task with a wide range of applications. However, current scene text recognition methods mainly focus on irregular text while have not explored artistic text specifically. The challenges of artistic text recognition include the various appearance with special-designed fonts and effects, the complex connections and overlaps between characters, and the severe interference from background patterns. To alleviate these problems, we propose to recognize the artistic text at three levels. Firstly, corner points are applied to guide the extraction of local features inside characters, considering the robustness of corner structures to appearance and shape. In this way, the discreteness of the corner points cuts off the connection between characters, and the sparsity of them improves the robustness for background interference. Secondly, we design a character contrastive loss to model the character-level feature, improving the feature representation for character classification. Thirdly, we utilize Transformer to learn the global feature on image-level and model the global relationship of the corner points, with the assistance of a corner-query cross-attention mechanism. Besides, we provide an artistic text dataset to benchmark the performance. Experimental results verify the significant superiority of our proposed method on artistic text recognition and also achieve state-of-the-art performance on several blurred and perspective datasets.