 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High-accuracy Event-based Underwater SLAM System
Jun 18, 2026While event cameras offer immense potential for underwater SLAM, existing Time Surface (TS)-based methods prove highly unreliable when deployed underwater. Fluctuating camera velocities severely degrade TS imaging quality, while wide stereo baselines and repetitive underwater textures induce critical matching failures, frequently triggering system failure. To overcome these challenges, we develop the first high-accuracy event-based underwater stereo SLAM system. A structure-aware metric for TS is designed based on structure tensor coherence and gradients to quantitatively evaluate TS structural information density. By decoupling the optimal TS generation into two distinct stages based on system initialization, Bayesian Optimization(BO) first predicts an optimal prior TS sequentially before initialization while we set an asynchronous online local searching method periodically to obtain appropriate TS in real-time during the tracking stage. We use the prior disparity to guarantee precise data association and "latest-observation-first'' triangulation mechanism to realize stable triangulation. As a benchmark for these solutions and a resource for the community, we also contribute UWE, the first high-quality real-world underwater event dataset containing variable camera motions, complex textures and different trajectory features. Extensive evaluations on public datasets and UWE show the competitive accuracy performance of the proposed SLAM system compared to the state-of-the-art event-based method. The code and data will be open-sourced.
Uni-MDTrack: Learning Decoupled Memory and Dynamic States for Parameter-Efficient Visual Tracking in All Modality
Mar 15, 2026With the advent of Transformer-based one-stream trackers that possess strong capability in inter-frame relation modeling, recent research has increasingly focused on how to introduce spatio-temporal context. However, most existing methods rely on a limited number of historical frames, which not only leads to insufficient utilization of the context, but also inevitably increases the length of input and incurs prohibitive computational overhead. Methods that query an external memory bank, on the other hand, suffer from inadequate fusion between the retrieved spatio-temporal features and the backbone. Moreover, using discrete historical frames as context overlooks the rich dynamics of the target. To address the issues, we propose Uni-MDTrack, which consists of two core components: Memory-Aware Compression Prompt (MCP) module and Dynamic State Fusion (DSF) module. MCP effectively compresses rich memory features into memory-aware prompt tokens, which deeply interact with the input throughout the entire backbone, significantly enhancing the performance while maintaining a stable computational load. DSF complements the discrete memory by capturing the continuous dynamic, progressively introducing the updated dynamic state features from shallow to deep layers, while also preserving high efficiency. Uni-MDTrack also supports unified tracking across RGB, RGB-D/T/E, and RGB-Language modalities. Experiments show that in Uni-MDTrack, training only the MCP, DSF, and prediction head, keeping the proportion of trainable parameters around 30%, yields substantial performance gains, achieves state-of-the-art results on 10 datasets spanning five modalities. Furthermore, both MCP and DSF exhibit excellent generality, functioning as plug-and-play components that can boost the performance of various baseline trackers, while significantly outperforming existing parameter-efficient training approaches.
Adaptive Confidence Gating in Multi-Agent Collaboration for Efficient and Optimized Code Generation
Jan 29, 2026While Large Language Models (LLMs) have catalyzed breakthroughs in automated code generation, Small Language Models (SLMs) often encounter reasoning bottlenecks and failure loops when addressing complex logical requirements. To overcome these challenges, we propose DebateCoder, a multi-agent collaborative framework designed to improve the reasoning ability of SLMs (e.g., Pangu-1B) in resource-constrained environments. DebateCoder uses a structured role-playing protocol with three agents: User Agent (A_UA), Technical Agent (A_TA), and Quality Assurance Agent (A_QA). It also includes an Adaptive Confidence Gating mechanism with a 95% threshold to balance accuracy and inference efficiency. In addition, we introduce a multi-turn deliberation module and a reviewer-guided analytical debugging loop for orthogonal pre-generation debate and post-generation refinement. Experiments on HumanEval and MBPP show that DebateCoder achieves 70.12% Pass@1 on HumanEval, outperforming MapCoder while reducing API overhead by about 35%. These results indicate that collaborative protocols can mitigate limitations of small-parameter models and provide a scalable, efficient approach to high-quality automated software engineering.
Lightweight Transformer via Unrolling of Mixed Graph Algorithms for Traffic Forecast
May 19, 2025



To forecast traffic with both spatial and temporal dimensions, we unroll a mixed-graph-based optimization algorithm into a lightweight and interpretable transformer-like neural net. Specifically, we construct two graphs: an undirected graph $\mathcal{G}^u$ capturing spatial correlations across geography, and a directed graph $\mathcal{G}^d$ capturing sequential relationships over time. We formulate a prediction problem for the future samples of signal $\mathbf{x}$, assuming it is "smooth" with respect to both $\mathcal{G}^u$ and $\mathcal{G}^d$, where we design new $\ell_2$ and $\ell_1$-norm variational terms to quantify and promote signal smoothness (low-frequency reconstruction) on a directed graph. We construct an iterative algorithm based on alternating direction method of multipliers (ADMM), and unroll it into a feed-forward network for data-driven parameter learning. We insert graph learning modules for $\mathcal{G}^u$ and $\mathcal{G}^d$, which are akin to the self-attention mechanism in classical transformers. Experiments show that our unrolled networks achieve competitive traffic forecast performance as state-of-the-art prediction schemes, while reducing parameter counts drastically. Our code is available in https://github.com/SingularityUndefined/Unrolling-GSP-STForecast.
OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
Dec 31, 2024



Scoring the Optical Character Recognition (OCR) capabilities of Large Multimodal Models (LMMs) has witnessed growing interest recently. Existing benchmarks have highlighted the impressive performance of LMMs in text recognition; however, their abilities on certain challenging tasks, such as text localization, handwritten content extraction, and logical reasoning, remain underexplored. To bridge this gap, we introduce OCRBench v2, a large-scale bilingual text-centric benchmark with currently the most comprehensive set of tasks (4x more tasks than the previous multi-scene benchmark OCRBench), the widest coverage of scenarios (31 diverse scenarios including street scene, receipt, formula, diagram, and so on), and thorough evaluation metrics, with a total of 10,000 human-verified question-answering pairs and a high proportion of difficult samples. After carefully benchmarking state-of-the-art LMMs on OCRBench v2, we find that 20 out of 22 LMMs score below 50 (100 in total) and suffer from five-type limitations, including less frequently encountered text recognition, fine-grained perception, layout perception, complex element parsing, and logical reasoning. The benchmark and evaluation scripts are available at https://github.com/Yuliang-liu/MultimodalOCR.
WAS: Dataset and Methods for Artistic Text Segmentation
Jul 31, 2024



Accurate text segmentation results are crucial for text-related generative tasks, such as text image generation, text editing, text removal, and text style transfer. Recently, some scene text segmentation methods have made significant progress in segmenting regular text. However, these methods perform poorly in scenarios containing artistic text. Therefore, this paper focuses on the more challenging task of artistic text segmentation and constructs a real artistic text segmentation dataset. One challenge of the task is that the local stroke shapes of artistic text are changeable with diversity and complexity. We propose a decoder with the layer-wise momentum query to prevent the model from ignoring stroke regions of special shapes. Another challenge is the complexity of the global topological structure. We further design a skeleton-assisted head to guide the model to focus on the global structure. Additionally, to enhance the generalization performance of the text segmentation model, we propose a strategy for training data synthesis, based on the large multi-modal model and the diffusion model. Experimental results show that our proposed method and synthetic dataset can significantly enhance the performance of artistic text segmentation and achieve state-of-the-art results on other public datasets.
Towards Practical Differential Privacy in Data Analysis: Understanding the Effect of Epsilon on Utility in Private ERM
Jun 06, 2022

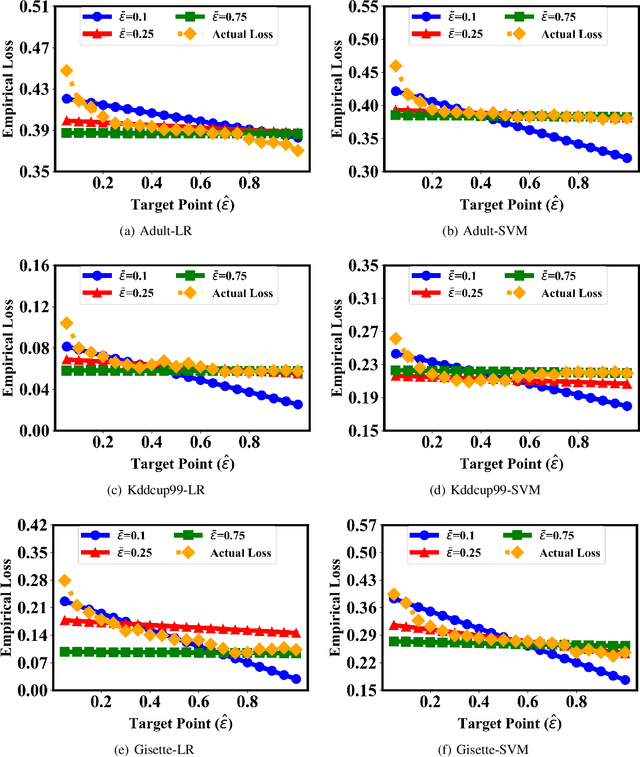

In this paper, we focus our attention on private Empirical Risk Minimization (ERM), which is one of the most commonly used data analysis method. We take the first step towards solving the above problem by theoretically exploring the effect of epsilon (the parameter of differential privacy that determines the strength of privacy guarantee) on utility of the learning model. We trace the change of utility with modification of epsilon and reveal an established relationship between epsilon and utility. We then formalize this relationship and propose a practical approach for estimating the utility under an arbitrary value of epsilon. Both theoretical analysis and experimental results demonstrate high estimation accuracy and broad applicability of our approach in practical applications. As providing algorithms with strong utility guarantees that also give privacy when possible becomes more and more accepted, our approach would have high practical value and may be likely to be adopted by companies and organizations that would like to preserve privacy but are unwilling to compromise on utility.