 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data Generation
May 19, 2025We present GrasMolmo, a generalizable open-vocabulary task-oriented grasping (TOG) model. GraspMolmo predicts semantically appropriate, stable grasps conditioned on a natural language instruction and a single RGB-D frame. For instance, given "pour me some tea", GraspMolmo selects a grasp on a teapot handle rather than its body. Unlike prior TOG methods, which are limited by small datasets, simplistic language, and uncluttered scenes, GraspMolmo learns from PRISM, a novel large-scale synthetic dataset of 379k samples featuring cluttered environments and diverse, realistic task descriptions. We fine-tune the Molmo visual-language model on this data, enabling GraspMolmo to generalize to novel open-vocabulary instructions and objects. In challenging real-world evaluations, GraspMolmo achieves state-of-the-art results, with a 70% prediction success on complex tasks, compared to the 35% achieved by the next best alternative. GraspMolmo also successfully demonstrates the ability to predict semantically correct bimanual grasps zero-shot. We release our synthetic dataset, code, model, and benchmarks to accelerate research in task-semantic robotic manipulation, which, along with videos, are available at https://abhaybd.github.io/GraspMolmo/.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
May 18, 2025Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.
VLM Q-Learning: Aligning Vision-Language Models for Interactive Decision-Making
May 06, 2025Recent research looks to harness the general knowledge and reasoning of large language models (LLMs) into agents that accomplish user-specified goals in interactive environments. Vision-language models (VLMs) extend LLMs to multi-modal data and provide agents with the visual reasoning necessary for new applications in areas such as computer automation. However, agent tasks emphasize skills where accessible open-weight VLMs lag behind their LLM equivalents. For example, VLMs are less capable of following an environment's strict output syntax requirements and are more focused on open-ended question answering. Overcoming these limitations requires supervised fine-tuning (SFT) on task-specific expert demonstrations. Our work approaches these challenges from an offline-to-online reinforcement learning (RL) perspective. RL lets us fine-tune VLMs to agent tasks while learning from the unsuccessful decisions of our own model or more capable (larger) models. We explore an off-policy RL solution that retains the stability and simplicity of the widely used SFT workflow while allowing our agent to self-improve and learn from low-quality datasets. We demonstrate this technique with two open-weight VLMs across three multi-modal agent domains.
Human-Level Competitive Pokémon via Scalable Offline Reinforcement Learning with Transformers
Apr 06, 2025Competitive Pok\'emon Singles (CPS) is a popular strategy game where players learn to exploit their opponent based on imperfect information in battles that can last more than one hundred stochastic turns. AI research in CPS has been led by heuristic tree search and online self-play, but the game may also create a platform to study adaptive policies trained offline on large datasets. We develop a pipeline to reconstruct the first-person perspective of an agent from logs saved from the third-person perspective of a spectator, thereby unlocking a dataset of real human battles spanning more than a decade that grows larger every day. This dataset enables a black-box approach where we train large sequence models to adapt to their opponent based solely on their input trajectory while selecting moves without explicit search of any kind. We study a progression from imitation learning to offline RL and offline fine-tuning on self-play data in the hardcore competitive setting of Pok\'emon's four oldest (and most partially observed) game generations. The resulting agents outperform a recent LLM Agent approach and a strong heuristic search engine. While playing anonymously in online battles against humans, our best agents climb to rankings inside the top 10% of active players.
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
Mar 31, 2025Large real-world robot datasets hold great potential to train generalist robot models, but scaling real-world human data collection is time-consuming and resource-intensive. Simulation has great potential in supplementing large-scale data, especially with recent advances in generative AI and automated data generation tools that enable scalable creation of robot behavior datasets. However, training a policy solely in simulation and transferring it to the real world often demands substantial human effort to bridge the reality gap. A compelling alternative is to co-train the policy on a mixture of simulation and real-world datasets. Preliminary studies have recently shown this strategy to substantially improve the performance of a policy over one trained on a limited amount of real-world data. Nonetheless, the community lacks a systematic understanding of sim-and-real co-training and what it takes to reap the benefits of simulation data for real-robot learning. This work presents a simple yet effective recipe for utilizing simulation data to solve vision-based robotic manipulation tasks. We derive this recipe from comprehensive experiments that validate the co-training strategy on various simulation and real-world datasets. Using two domains--a robot arm and a humanoid--across diverse tasks, we demonstrate that simulation data can enhance real-world task performance by an average of 38%, even with notable differences between the simulation and real-world data. Videos and additional results can be found at https://co-training.github.io/
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
Sim-to-Real Reinforcement Learning for Vision-Based Dexterous Manipulation on Humanoids
Feb 27, 2025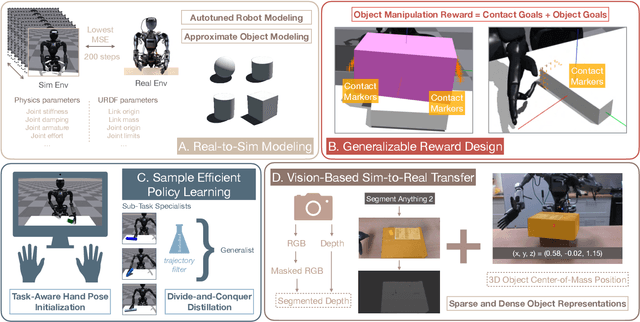

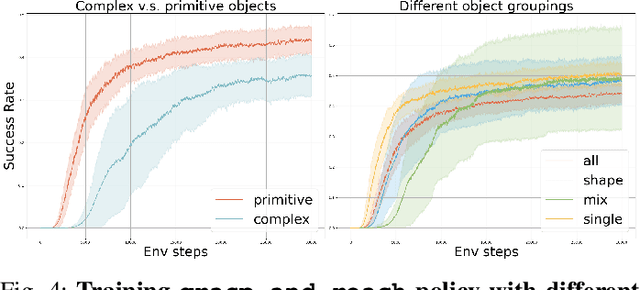
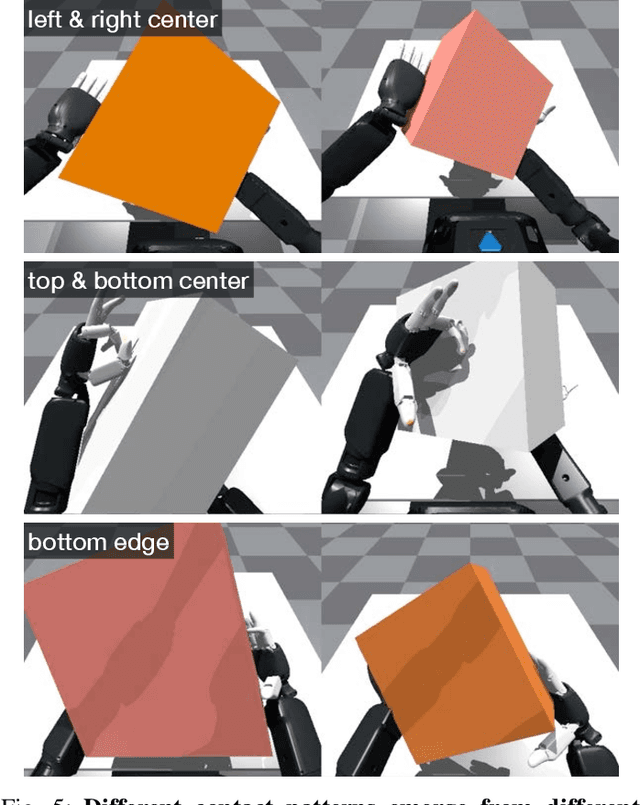
Reinforcement learning has delivered promising results in achieving human- or even superhuman-level capabilities across diverse problem domains, but success in dexterous robot manipulation remains limited. This work investigates the key challenges in applying reinforcement learning to solve a collection of contact-rich manipulation tasks on a humanoid embodiment. We introduce novel techniques to overcome the identified challenges with empirical validation. Our main contributions include an automated real-to-sim tuning module that brings the simulated environment closer to the real world, a generalized reward design scheme that simplifies reward engineering for long-horizon contact-rich manipulation tasks, a divide-and-conquer distillation process that improves the sample efficiency of hard-exploration problems while maintaining sim-to-real performance, and a mixture of sparse and dense object representations to bridge the sim-to-real perception gap. We show promising results on three humanoid dexterous manipulation tasks, with ablation studies on each technique. Our work presents a successful approach to learning humanoid dexterous manipulation using sim-to-real reinforcement learning, achieving robust generalization and high performance without the need for human demonstration.
QLIP: Text-Aligned Visual Tokenization Unifies Auto-Regressive Multimodal Understanding and Generation
Feb 07, 2025We introduce Quantized Language-Image Pretraining (QLIP), a visual tokenization method that combines state-of-the-art reconstruction quality with state-of-the-art zero-shot image understanding. QLIP trains a binary-spherical-quantization-based autoencoder with reconstruction and language-image alignment objectives. We are the first to show that the two objectives do not need to be at odds. We balance the two loss terms dynamically during training and show that a two-stage training pipeline effectively mixes the large-batch requirements of image-language pre-training with the memory bottleneck imposed by the reconstruction objective. We validate the effectiveness of QLIP for multimodal understanding and text-conditioned image generation with a single model. Specifically, QLIP serves as a drop-in replacement for the visual encoder for LLaVA and the image tokenizer for LlamaGen with comparable or even better performance. Finally, we demonstrate that QLIP enables a unified mixed-modality auto-regressive model for understanding and generation.
ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills
Feb 03, 2025Humanoid robots hold the potential for unparalleled versatility in performing human-like, whole-body skills. However, achieving agile and coordinated whole-body motions remains a significant challenge due to the dynamics mismatch between simulation and the real world. Existing approaches, such as system identification (SysID) and domain randomization (DR) methods, often rely on labor-intensive parameter tuning or result in overly conservative policies that sacrifice agility. In this paper, we present ASAP (Aligning Simulation and Real-World Physics), a two-stage framework designed to tackle the dynamics mismatch and enable agile humanoid whole-body skills. In the first stage, we pre-train motion tracking policies in simulation using retargeted human motion data. In the second stage, we deploy the policies in the real world and collect real-world data to train a delta (residual) action model that compensates for the dynamics mismatch. Then, ASAP fine-tunes pre-trained policies with the delta action model integrated into the simulator to align effectively with real-world dynamics. We evaluate ASAP across three transfer scenarios: IsaacGym to IsaacSim, IsaacGym to Genesis, and IsaacGym to the real-world Unitree G1 humanoid robot. Our approach significantly improves agility and whole-body coordination across various dynamic motions, reducing tracking error compared to SysID, DR, and delta dynamics learning baselines. ASAP enables highly agile motions that were previously difficult to achieve, demonstrating the potential of delta action learning in bridging simulation and real-world dynamics. These results suggest a promising sim-to-real direction for developing more expressive and agile humanoids.
Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning
Jan 03, 2025



Humanoid robots have great potential to perform various human-level skills. These skills involve locomotion, manipulation, and cognitive capabilities. Driven by advances in machine learning and the strength of existing model-based approaches, these capabilities have progressed rapidly, but often separately. Therefore, a timely overview of current progress and future trends in this fast-evolving field is essential. This survey first summarizes the model-based planning and control that have been the backbone of humanoid robotics for the past three decades. We then explore emerging learning-based methods, with a focus on reinforcement learning and imitation learning that enhance the versatility of loco-manipulation skills. We examine the potential of integrating foundation models with humanoid embodiments, assessing the prospects for developing generalist humanoid agents. In addition, this survey covers emerging research for whole-body tactile sensing that unlocks new humanoid skills that involve physical interactions. The survey concludes with a discussion of the challenges and future trends.