 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleMoMa: A Modular and Versatile Teleoperation System for Mobile Manipulation
Mar 12, 2024



A critical bottleneck limiting imitation learning in robotics is the lack of data. This problem is more severe in mobile manipulation, where collecting demonstrations is harder than in stationary manipulation due to the lack of available and easy-to-use teleoperation interfaces. In this work, we demonstrate TeleMoMa, a general and modular interface for whole-body teleoperation of mobile manipulators. TeleMoMa unifies multiple human interfaces including RGB and depth cameras, virtual reality controllers, keyboard, joysticks, etc., and any combination thereof. In its more accessible version, TeleMoMa works using simply vision (e.g., an RGB-D camera), lowering the entry bar for humans to provide mobile manipulation demonstrations. We demonstrate the versatility of TeleMoMa by teleoperating several existing mobile manipulators - PAL Tiago++, Toyota HSR, and Fetch - in simulation and the real world. We demonstrate the quality of the demonstrations collected with TeleMoMa by training imitation learning policies for mobile manipulation tasks involving synchronized whole-body motion. Finally, we also show that TeleMoMa's teleoperation channel enables teleoperation on site, looking at the robot, or remote, sending commands and observations through a computer network, and perform user studies to evaluate how easy it is for novice users to learn to collect demonstrations with different combinations of human interfaces enabled by our system. We hope TeleMoMa becomes a helpful tool for the community enabling researchers to collect whole-body mobile manipulation demonstrations. For more information and video results, https://robin-lab.cs.utexas.edu/telemoma-web.
Symbolic State Space Optimization for Long Horizon Mobile Manipulation Planning
Jul 21, 2023



In existing task and motion planning (TAMP) research, it is a common assumption that experts manually specify the state space for task-level planning. A well-developed state space enables the desirable distribution of limited computational resources between task planning and motion planning. However, developing such task-level state spaces can be non-trivial in practice. In this paper, we consider a long horizon mobile manipulation domain including repeated navigation and manipulation. We propose Symbolic State Space Optimization (S3O) for computing a set of abstracted locations and their 2D geometric groundings for generating task-motion plans in such domains. Our approach has been extensively evaluated in simulation and demonstrated on a real mobile manipulator working on clearing up dining tables. Results show the superiority of the proposed method over TAMP baselines in task completion rate and execution time.
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
May 05, 2023Large language models (LLMs) have demonstrated remarkable zero-shot generalization abilities: state-of-the-art chatbots can provide plausible answers to many common questions that arise in daily life. However, so far, LLMs cannot reliably solve long-horizon planning problems. By contrast, classical planners, once a problem is given in a formatted way, can use efficient search algorithms to quickly identify correct, or even optimal, plans. In an effort to get the best of both worlds, this paper introduces LLM+P, the first framework that incorporates the strengths of classical planners into LLMs. LLM+P takes in a natural language description of a planning problem, then returns a correct (or optimal) plan for solving that problem in natural language. LLM+P does so by first converting the language description into a file written in the planning domain definition language (PDDL), then leveraging classical planners to quickly find a solution, and then translating the found solution back into natural language. Along with LLM+P, we define a diverse set of different benchmark problems taken from common planning scenarios. Via a comprehensive set of experiments on these benchmark problems, we find that LLM+P is able to provide optimal solutions for most problems, while LLMs fail to provide even feasible plans for most problems.\footnote{The code and results are publicly available at https://github.com/Cranial-XIX/llm-pddl.git.
Language-Informed Transfer Learning for Embodied Household Activities
Jan 12, 2023



For service robots to become general-purpose in everyday household environments, they need not only a large library of primitive skills, but also the ability to quickly learn novel tasks specified by users. Fine-tuning neural networks on a variety of downstream tasks has been successful in many vision and language domains, but research is still limited on transfer learning between diverse long-horizon tasks. We propose that, compared to reinforcement learning for a new household activity from scratch, home robots can benefit from transferring the value and policy networks trained for similar tasks. We evaluate this idea in the BEHAVIOR simulation benchmark which includes a large number of household activities and a set of action primitives. For easy mapping between state spaces of different tasks, we provide a text-based representation and leverage language models to produce a common embedding space. The results show that the selection of similar source activities can be informed by the semantic similarity of state and goal descriptions with the target task. We further analyze the results and discuss ways to overcome the problem of catastrophic forgetting.
Temporal-Logic-Based Reward Shaping for Continuing Learning Tasks
Jul 03, 2020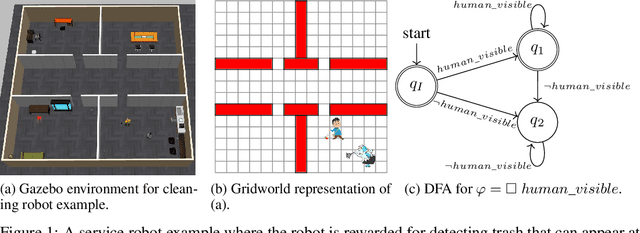
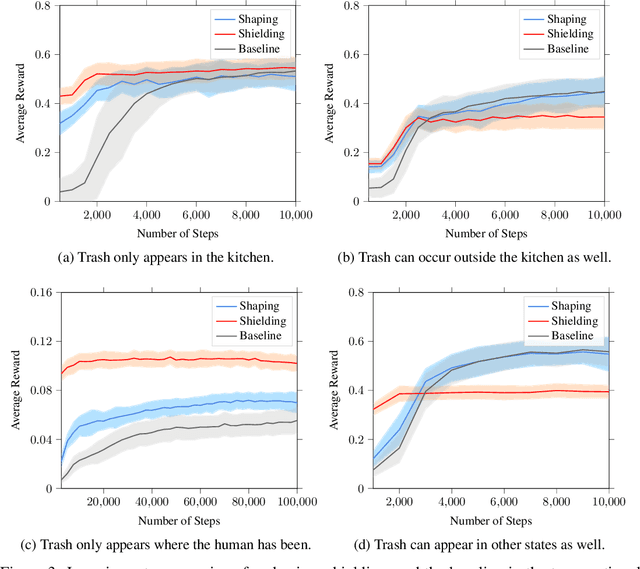
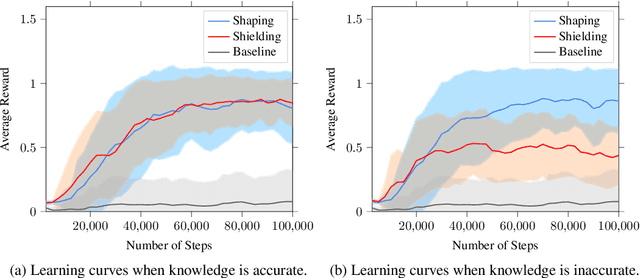
In continuing tasks, average-reward reinforcement learning may be a more appropriate problem formulation than the more common discounted reward formulation. As usual, learning an optimal policy in this setting typically requires a large amount of training experiences. Reward shaping is a common approach for incorporating domain knowledge into reinforcement learning in order to speed up convergence to an optimal policy. However, to the best of our knowledge, the theoretical properties of reward shaping have thus far only been established in the discounted setting. This paper presents the first reward shaping framework for average-reward learning and proves that, under standard assumptions, the optimal policy under the original reward function can be recovered. In order to avoid the need for manual construction of the shaping function, we introduce a method for utilizing domain knowledge expressed as a temporal logic formula. The formula is automatically translated to a shaping function that provides additional reward throughout the learning process. We evaluate the proposed method on three continuing tasks. In all cases, shaping speeds up the average-reward learning rate without any reduction in the performance of the learned policy compared to relevant baselines.
Deep R-Learning for Continual Area Sweeping
May 31, 2020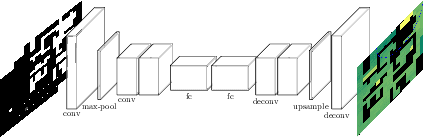


Coverage path planning is a well-studied problem in robotics in which a robot must plan a path that passes through every point in a given area repeatedly, usually with a uniform frequency. To address the scenario in which some points need to be visited more frequently than others, this problem has been extended to non-uniform coverage planning. This paper considers the variant of non-uniform coverage in which the robot does not know the distribution of relevant events beforehand and must nevertheless learn to maximize the rate of detecting events of interest. This continual area sweeping problem has been previously formalized in a way that makes strong assumptions about the environment, and to date only a greedy approach has been proposed. We generalize the continual area sweeping formulation to include fewer environmental constraints, and propose a novel approach based on reinforcement learning in a Semi-Markov Decision Process. This approach is evaluated in an abstract simulation and in a high fidelity Gazebo simulation. These evaluations show significant improvement upon the existing approach in general settings, which is especially relevant in the growing area of service robotics.
Solving Service Robot Tasks: UT Austin Villa@Home 2019 Team Report
Sep 14, 2019
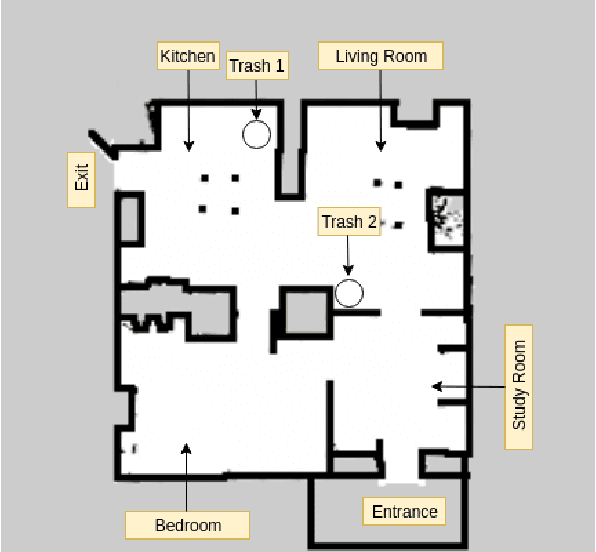
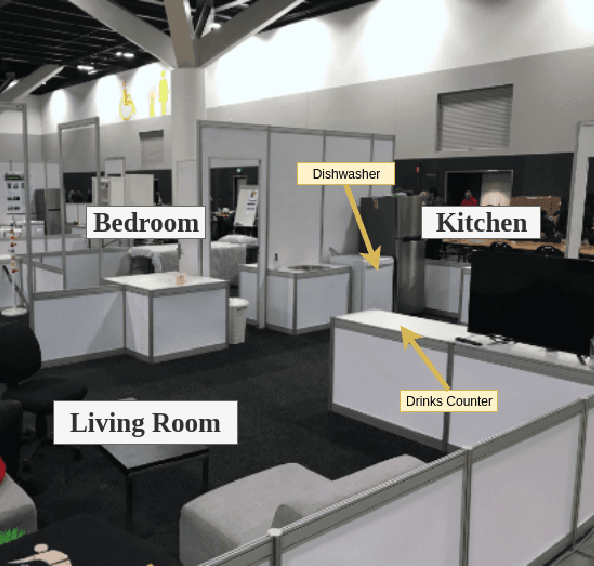

RoboCup@Home is an international robotics competition based on domestic tasks requiring autonomous capabilities pertaining to a large variety of AI technologies. Research challenges are motivated by these tasks both at the level of individual technologies and the integration of subsystems into a fully functional, robustly autonomous system. We describe the progress made by the UT Austin Villa 2019 RoboCup@Home team which represents a significant step forward in AI-based HRI due to the breadth of tasks accomplished within a unified system. Presented are the competition tasks, component technologies they rely on, our initial approaches both to the components and their integration, and directions for future research.
Desiderata for Planning Systems in General-Purpose Service Robots
Jul 04, 2019
General-purpose service robots are expected to undertake a broad range of tasks at the request of users. Knowledge representation and planning systems are essential to flexible autonomous robots, but the field lacks a unified perspective on which features are essential for general-purpose service robots. Progress towards planning and reasoning for general-purpose service robots is hindered by differing assumptions about users, the environment, and the overall robot system. In this position paper, we propose desiderata for planning and reasoning systems to promote general-purpose service robots. Each proposed item draws on our experience with research on service robots in the office and home and on the demands of these environments. Our desiderata emphasize support for natural human-interfaces as well as for robust fallback methods when interactions with humans and the environment fail. We highlight relevant work towards these goals.
Improving Grounded Natural Language Understanding through Human-Robot Dialog
Mar 01, 2019

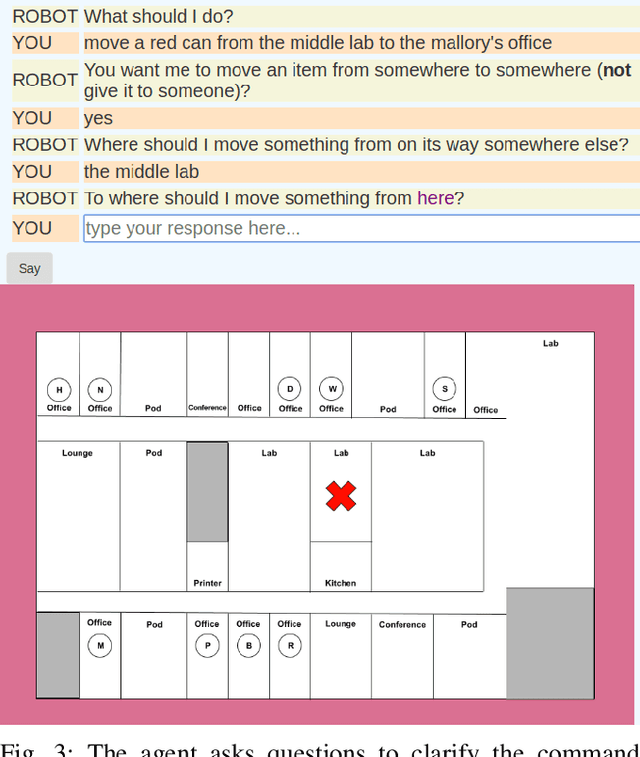

Natural language understanding for robotics can require substantial domain- and platform-specific engineering. For example, for mobile robots to pick-and-place objects in an environment to satisfy human commands, we can specify the language humans use to issue such commands, and connect concept words like red can to physical object properties. One way to alleviate this engineering for a new domain is to enable robots in human environments to adapt dynamically---continually learning new language constructions and perceptual concepts. In this work, we present an end-to-end pipeline for translating natural language commands to discrete robot actions, and use clarification dialogs to jointly improve language parsing and concept grounding. We train and evaluate this agent in a virtual setting on Amazon Mechanical Turk, and we transfer the learned agent to a physical robot platform to demonstrate it in the real world.
Integrating Task-Motion Planning with Reinforcement Learning for Robust Decision Making in Mobile Robots
Nov 21, 2018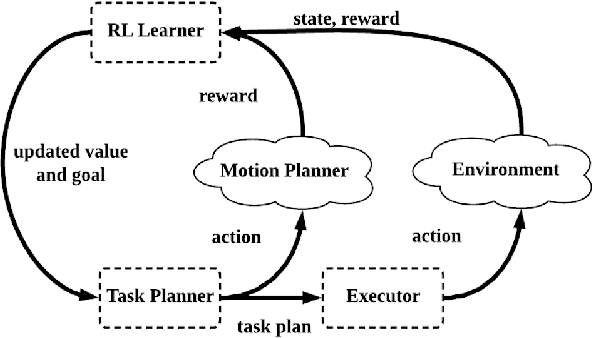

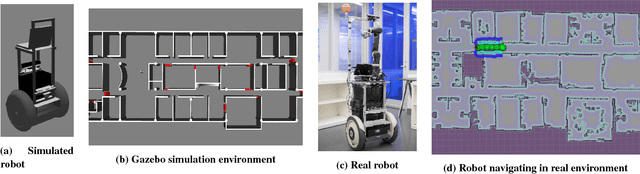
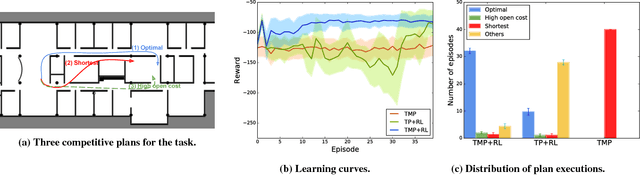
Task-motion planning (TMP) addresses the problem of efficiently generating executable and low-cost task plans in a discrete space such that the (initially unknown) action costs are determined by motion plans in a corresponding continuous space. However, a task-motion plan can be sensitive to unexpected domain uncertainty and changes, leading to suboptimal behaviors or execution failures. In this paper, we propose a novel framework, TMP-RL, which is an integration of TMP and reinforcement learning (RL) from the execution experience, to solve the problem of robust task-motion planning in dynamic and uncertain domains. TMP-RL features two nested planning-learning loops. In the inner TMP loop, the robot generates a low-cost, feasible task-motion plan by iteratively planning in the discrete space and updating relevant action costs evaluated by the motion planner in continuous space. In the outer loop, the plan is executed, and the robot learns from the execution experience via model-free RL, to further improve its task-motion plans. RL in the outer loop is more accurate to the current domain but also more expensive, and using less costly task and motion planning leads to a jump-start for learning in the real world. Our approach is evaluated on a mobile service robot conducting navigation tasks in an office area. Results show that TMP-RL approach significantly improves adaptability and robustness (in comparison to TMP methods) and leads to rapid convergence (in comparison to task planning (TP)-RL methods). We also show that TMP-RL can reuse learned values to smoothly adapt to new scenarios during long-term deployments.