 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAC-DMVC: Reliability-Aware Contrastive Deep Multi-View Clustering under Multi-Source Noise
Nov 17, 2025



Multi-view clustering (MVC), which aims to separate the multi-view data into distinct clusters in an unsupervised manner, is a fundamental yet challenging task. To enhance its applicability in real-world scenarios, this paper addresses a more challenging task: MVC under multi-source noises, including missing noise and observation noise. To this end, we propose a novel framework, Reliability-Aware Contrastive Deep Multi-View Clustering (RAC-DMVC), which constructs a reliability graph to guide robust representation learning under noisy environments. Specifically, to address observation noise, we introduce a cross-view reconstruction to enhances robustness at the data level, and a reliability-aware noise contrastive learning to mitigates bias in positive and negative pairs selection caused by noisy representations. To handle missing noise, we design a dual-attention imputation to capture shared information across views while preserving view-specific features. In addition, a self-supervised cluster distillation module further refines the learned representations and improves the clustering performance. Extensive experiments on five benchmark datasets demonstrate that RAC-DMVC outperforms SOTA methods on multiple evaluation metrics and maintains excellent performance under varying ratios of noise.
Enabling Wireless Power Transfer (WPT) in Pinching Antenna Systems (PASS)
Nov 14, 2025A novel pinching antenna system (PASS) enabled wireless power transfer (WPT) framework is proposed, where energy harvesting receivers (EHRs) and information decoding receivers (IDRs) coexist. By activating pinching antennas (PAs) near both receivers and flexibly adjusting PAs' power radiation ratios, both energy harvesting efficiency and communication quality can be enhanced. A bi-level optimization problem is formulated to overcome the strong coupling between optimization variables. The upper level jointly optimizes transmit beamforming, PA positions, and feasible interval of power radiation ratios for power conversion efficiency (PCE) maximization under rate requirements, while the lower level refines power radiation ratio for the sum rate maximization. Efficient solutions are developed for both two-user and multi-user scenarios. 1) For the two-user case, where an EHR and an IDR coexist, the alternating optimization (AO)-based and weighted minimum mean square error (WMMSE)-based algorithms are developed to achieve the stationary solutions of transmit beamforming, PA positions, and power radiation ratios. 2) For the multi-user case, a quadratic transform-Lagrangian dual transform (QT-LDT) algorithm is proposed to iteratively update PCE and sum rate by optimizing PA positions and power radiation ratios individually. Closed-form solutions are derived for both maximization problems. Numerical simulation results demonstrate that the proposed PASS-WPT framework significantly outperforms conventional MIMO and the baseline PASS with fixed power radiation, which demonstrates that: i) Compared to the conventional MIMO and baseline PASS, the proposed PASS-WPT framework achieves 81.45% and 43.19% improvements in PCE of EHRs, and ii) also increases the sum rate by 77.81% and 31.91% for IDRs.
GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025



As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
CRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025



Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
SCRIBES: Web-Scale Script-Based Semi-Structured Data Extraction with Reinforcement Learning
Oct 02, 2025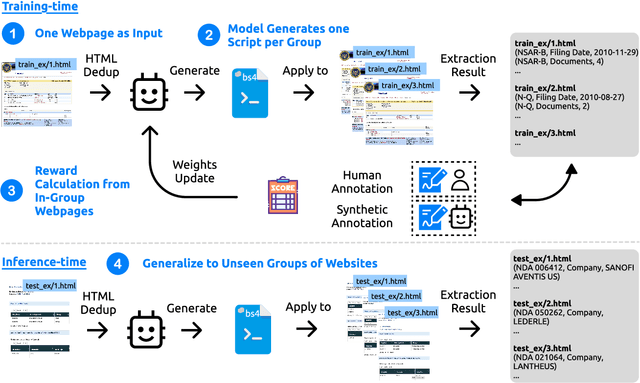
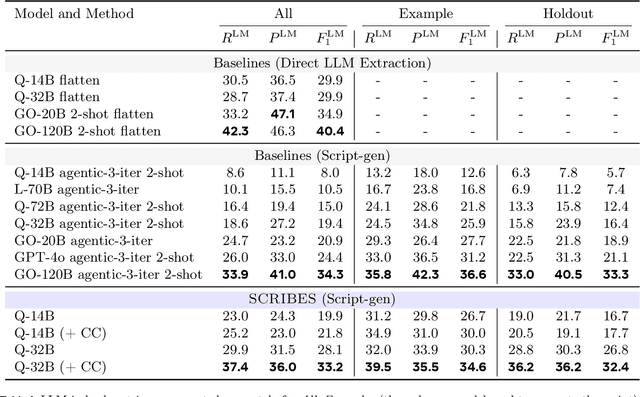
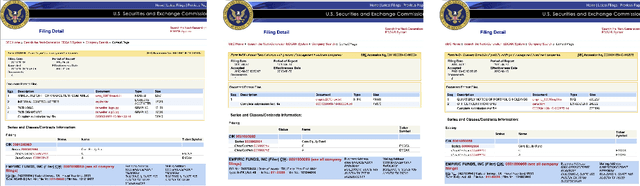

Semi-structured content in HTML tables, lists, and infoboxes accounts for a substantial share of factual data on the web, yet the formatting complicates usage, and reliably extracting structured information from them remains challenging. Existing methods either lack generalization or are resource-intensive due to per-page LLM inference. In this paper, we introduce SCRIBES (SCRIpt-Based Semi-Structured Content Extraction at Web-Scale), a novel reinforcement learning framework that leverages layout similarity across webpages within the same site as a reward signal. Instead of processing each page individually, SCRIBES generates reusable extraction scripts that can be applied to groups of structurally similar webpages. Our approach further improves by iteratively training on synthetic annotations from in-the-wild CommonCrawl data. Experiments show that our approach outperforms strong baselines by over 13% in script quality and boosts downstream question answering accuracy by more than 4% for GPT-4o, enabling scalable and resource-efficient web information extraction.
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage
Oct 02, 2025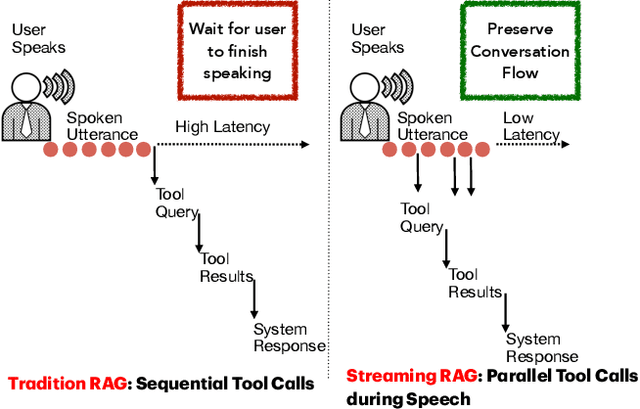
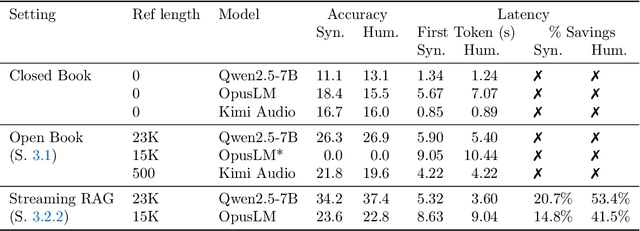
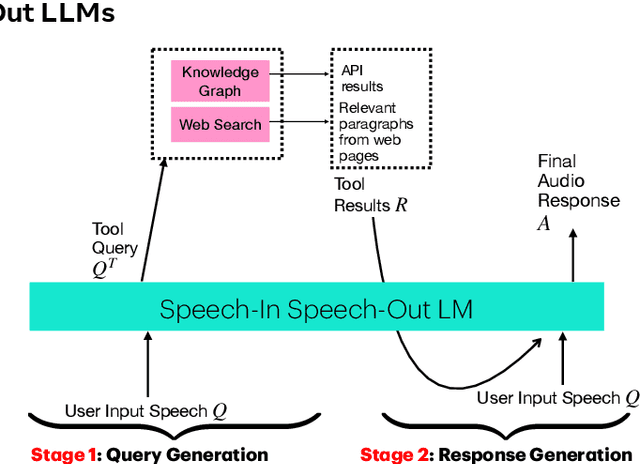
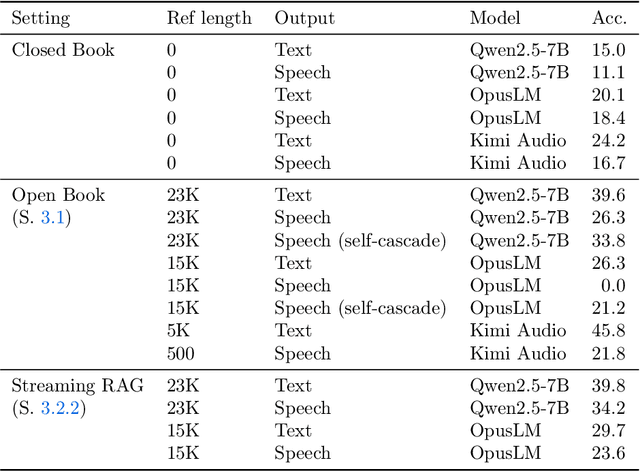
End-to-end speech-in speech-out dialogue systems are emerging as a powerful alternative to traditional ASR-LLM-TTS pipelines, generating more natural, expressive responses with significantly lower latency. However, these systems remain prone to hallucinations due to limited factual grounding. While text-based dialogue systems address this challenge by integrating tools such as web search and knowledge graph APIs, we introduce the first approach to extend tool use directly into speech-in speech-out systems. A key challenge is that tool integration substantially increases response latency, disrupting conversational flow. To mitigate this, we propose Streaming Retrieval-Augmented Generation (Streaming RAG), a novel framework that reduces user-perceived latency by predicting tool queries in parallel with user speech, even before the user finishes speaking. Specifically, we develop a post-training pipeline that teaches the model when to issue tool calls during ongoing speech and how to generate spoken summaries that fuse audio queries with retrieved text results, thereby improving both accuracy and responsiveness. To evaluate our approach, we construct AudioCRAG, a benchmark created by converting queries from the publicly available CRAG dataset into speech form. Experimental results demonstrate that our streaming RAG approach increases QA accuracy by up to 200% relative (from 11.1% to 34.2% absolute) and further enhances user experience by reducing tool use latency by 20%. Importantly, our streaming RAG approach is modality-agnostic and can be applied equally to typed input, paving the way for more agentic, real-time AI assistants.
Comprehend and Talk: Text to Speech Synthesis via Dual Language Modeling
Sep 26, 2025Existing Large Language Model (LLM) based autoregressive (AR) text-to-speech (TTS) systems, while achieving state-of-the-art quality, still face critical challenges. The foundation of this LLM-based paradigm is the discretization of the continuous speech waveform into a sequence of discrete tokens by neural audio codec. However, single codebook modeling is well suited to text LLMs, but suffers from significant information loss; hierarchical acoustic tokens, typically generated via Residual Vector Quantization (RVQ), often lack explicit semantic structure, placing a heavy learning burden on the model. Furthermore, the autoregressive process is inherently susceptible to error accumulation, which can degrade generation stability. To address these limitations, we propose CaT-TTS, a novel framework for robust and semantically-grounded zero-shot synthesis. First, we introduce S3Codec, a split RVQ codec that injects explicit linguistic features into its primary codebook via semantic distillation from a state-of-the-art ASR model, providing a structured representation that simplifies the learning task. Second, we propose an ``Understand-then-Generate'' dual-Transformer architecture that decouples comprehension from rendering. An initial ``Understanding'' Transformer models the cross-modal relationship between text and the audio's semantic tokens to form a high-level utterance plan. A subsequent ``Generation'' Transformer then executes this plan, autoregressively synthesizing hierarchical acoustic tokens. Finally, to enhance generation stability, we introduce Masked Audio Parallel Inference (MAPI), a nearly parameter-free inference strategy that dynamically guides the decoding process to mitigate local errors.
Multi-Channel Differential ASR for Robust Wearer Speech Recognition on Smart Glasses
Sep 17, 2025With the growing adoption of wearable devices such as smart glasses for AI assistants, wearer speech recognition (WSR) is becoming increasingly critical to next-generation human-computer interfaces. However, in real environments, interference from side-talk speech remains a significant challenge to WSR and may cause accumulated errors for downstream tasks such as natural language processing. In this work, we introduce a novel multi-channel differential automatic speech recognition (ASR) method for robust WSR on smart glasses. The proposed system takes differential inputs from different frontends that complement each other to improve the robustness of WSR, including a beamformer, microphone selection, and a lightweight side-talk detection model. Evaluations on both simulated and real datasets demonstrate that the proposed system outperforms the traditional approach, achieving up to an 18.0% relative reduction in word error rate.
"My productivity is boosted, but ..." Demystifying Users' Perception on AI Coding Assistants
Aug 17, 2025This paper aims to explore fundamental questions in the era when AI coding assistants like GitHub Copilot are widely adopted: what do developers truly value and criticize in AI coding assistants, and what does this reveal about their needs and expectations in real-world software development? Unlike previous studies that conduct observational research in controlled and simulated environments, we analyze extensive, first-hand user reviews of AI coding assistants, which capture developers' authentic perspectives and experiences drawn directly from their actual day-to-day work contexts. We identify 1,085 AI coding assistants from the Visual Studio Code Marketplace. Although they only account for 1.64% of all extensions, we observe a surge in these assistants: over 90% of them are released within the past two years. We then manually analyze the user reviews sampled from 32 AI coding assistants that have sufficient installations and reviews to construct a comprehensive taxonomy of user concerns and feedback about these assistants. We manually annotate each review's attitude when mentioning certain aspects of coding assistants, yielding nuanced insights into user satisfaction and dissatisfaction regarding specific features, concerns, and overall tool performance. Built on top of the findings-including how users demand not just intelligent suggestions but also context-aware, customizable, and resource-efficient interactions-we propose five practical implications and suggestions to guide the enhancement of AI coding assistants that satisfy user needs.
VisualTrans: A Benchmark for Real-World Visual Transformation Reasoning
Aug 06, 2025Visual transformation reasoning (VTR) is a vital cognitive capability that empowers intelligent agents to understand dynamic scenes, model causal relationships, and predict future states, and thereby guiding actions and laying the foundation for advanced intelligent systems. However, existing benchmarks suffer from a sim-to-real gap, limited task complexity, and incomplete reasoning coverage, limiting their practical use in real-world scenarios. To address these limitations, we introduce VisualTrans, the first comprehensive benchmark specifically designed for VTR in real-world human-object interaction scenarios. VisualTrans encompasses 12 semantically diverse manipulation tasks and systematically evaluates three essential reasoning dimensions - spatial, procedural, and quantitative - through 6 well-defined subtask types. The benchmark features 472 high-quality question-answer pairs in various formats, including multiple-choice, open-ended counting, and target enumeration. We introduce a scalable data construction pipeline built upon first-person manipulation videos, which integrates task selection, image pair extraction, automated metadata annotation with large multimodal models, and structured question generation. Human verification ensures the final benchmark is both high-quality and interpretable. Evaluations of various state-of-the-art vision-language models show strong performance in static spatial tasks. However, they reveal notable shortcomings in dynamic, multi-step reasoning scenarios, particularly in areas like intermediate state recognition and transformation sequence planning. These findings highlight fundamental weaknesses in temporal modeling and causal reasoning, providing clear directions for future research aimed at developing more capable and generalizable VTR systems. The dataset and code are available at https://github.com/WangYipu2002/VisualTrans.