 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models Abilities for Addressee, Turn-change, and Next Speaker Prediction in Meetings
Jun 16, 2026We investigate turn-taking in multimodal multi-party conversations using large language models (LLMs). We construct an evaluation framework for three tasks: addressee detection, turn-change prediction, and next speaker prediction. We compare supervised models trained for these tasks, text-based LLMs, multimodal LLMs (MM-LLMs), and human subjects. Experiments on the AMI corpus showed that LLMs outperformed supervised models and humans in next speaker prediction, despite not being trained on the target domain and without access to audio or visual information. An MM-LLM performed better than text-based LLMs on addressee detection and turn-change prediction but remained below human performance, indicating difficulty leveraging raw audio-visual signals. Ablation analyses revealed that conversational context was critical, particularly for next speaker prediction. We observed that human and LLM prediction patterns were similar, and intervals with frequent turn changes were difficult for both.
Bagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Feb 05, 2026Current audio foundation models typically rely on rigid, task-specific supervision, addressing isolated factors of audio rather than the whole. In contrast, human intelligence processes audio holistically, seamlessly bridging physical signals with abstract cognitive concepts to execute complex tasks. Grounded in this philosophy, we introduce Bagpiper, an 8B audio foundation model that interprets physical audio via rich captions, i.e., comprehensive natural language descriptions that encapsulate the critical cognitive concepts inherent in the signal (e.g., transcription, audio events). By pre-training on a massive corpus of 600B tokens, the model establishes a robust bidirectional mapping between raw audio and this high-level conceptual space. During fine-tuning, Bagpiper adopts a caption-then-process workflow, simulating an intermediate cognitive reasoning step to solve diverse tasks without task-specific priors. Experimentally, Bagpiper outperforms Qwen-2.5-Omni on MMAU and AIRBench for audio understanding and surpasses CosyVoice3 and TangoFlux in generation quality, capable of synthesizing arbitrary compositions of speech, music, and sound effects. To the best of our knowledge, Bagpiper is among the first works that achieve unified understanding generation for general audio. Model, data, and code are available at Bagpiper Home Page.
Optimizing Conversational Quality in Spoken Dialogue Systems with Reinforcement Learning from AI Feedback
Jan 27, 2026Reinforcement learning from human or AI feedback (RLHF/RLAIF) for speech-in/speech-out dialogue systems (SDS) remains underexplored, with prior work largely limited to single semantic rewards applied at the utterance level. Such setups overlook the multi-dimensional and multi-modal nature of conversational quality, which encompasses semantic coherence, audio naturalness, speaker consistency, emotion alignment, and turn-taking behavior. Moreover, they are fundamentally mismatched with duplex spoken dialogue systems that generate responses incrementally, where agents must make decisions based on partial utterances. We address these limitations with the first multi-reward RLAIF framework for SDS, combining semantic, audio-quality, and emotion-consistency rewards. To align utterance-level preferences with incremental, blockwise decoding in duplex models, we apply turn-level preference sampling and aggregate per-block log-probabilities within a single DPO objective. We present the first systematic study of preference learning for improving SDS quality in both multi-turn Chain-of-Thought and blockwise duplex models, and release a multi-reward DPO dataset to support reproducible research. Experiments show that single-reward RLAIF selectively improves its targeted metric, while joint multi-reward training yields consistent gains across semantic quality and audio naturalness. These results highlight the importance of holistic, multi-reward alignment for practical conversational SDS.
WearVox: An Egocentric Multichannel Voice Assistant Benchmark for Wearables
Dec 25, 2025Wearable devices such as AI glasses are transforming voice assistants into always-available, hands-free collaborators that integrate seamlessly with daily life, but they also introduce challenges like egocentric audio affected by motion and noise, rapid micro-interactions, and the need to distinguish device-directed speech from background conversations. Existing benchmarks largely overlook these complexities, focusing instead on clean or generic conversational audio. To bridge this gap, we present WearVox, the first benchmark designed to rigorously evaluate voice assistants in realistic wearable scenarios. WearVox comprises 3,842 multi-channel, egocentric audio recordings collected via AI glasses across five diverse tasks including Search-Grounded QA, Closed-Book QA, Side-Talk Rejection, Tool Calling, and Speech Translation, spanning a wide range of indoor and outdoor environments and acoustic conditions. Each recording is accompanied by rich metadata, enabling nuanced analysis of model performance under real-world constraints. We benchmark leading proprietary and open-source speech Large Language Models (SLLMs) and find that most real-time SLLMs achieve accuracies on WearVox ranging from 29% to 59%, with substantial performance degradation on noisy outdoor audio, underscoring the difficulty and realism of the benchmark. Additionally, we conduct a case study with two new SLLMs that perform inference with single-channel and multi-channel audio, demonstrating that multi-channel audio inputs significantly enhance model robustness to environmental noise and improve discrimination between device-directed and background speech. Our results highlight the critical importance of spatial audio cues for context-aware voice assistants and establish WearVox as a comprehensive testbed for advancing wearable voice AI research.
Full-Duplex-Bench-v2: A Multi-Turn Evaluation Framework for Duplex Dialogue Systems with an Automated Examiner
Oct 09, 2025While full-duplex speech agents enable natural, low-latency interaction by speaking and listening simultaneously, their consistency and task performance in multi-turn settings remain underexplored. We introduce Full-Duplex-Bench-v2 (FDB-v2), a streaming framework that integrates with an automated examiner that enforces staged goals under two pacing setups (Fast vs. Slow). FDB-v2 covers four task families: daily, correction, entity tracking, and safety. We report turn-taking fluency, multi-turn instruction following, and task-specific competence. The framework is extensible, supporting both commercial APIs and open source models. When we test full-duplex systems with FDB-v2, they often get confused when people talk at the same time, struggle to handle corrections smoothly, and sometimes lose track of who or what is being talked about. Through an open-sourced, standardized streaming protocol and a task set, FDB-v2 makes it easy to extend to new task families, allowing the community to tailor and accelerate evaluation of multi-turn full-duplex systems.
Chain-of-Thought Reasoning in Streaming Full-Duplex End-to-End Spoken Dialogue Systems
Oct 02, 2025Most end-to-end (E2E) spoken dialogue systems (SDS) rely on voice activity detection (VAD) for turn-taking, but VAD fails to distinguish between pauses and turn completions. Duplex SDS models address this by predicting output continuously, including silence tokens, thus removing the need for explicit VAD. However, they often have complex dual-channel architecture and lag behind cascaded models in semantic reasoning. To overcome these challenges, we propose SCoT: a Streaming Chain-of-Thought (CoT) framework for Duplex SDS, alternating between processing fixed-duration user input and generating responses in a blockwise manner. Using frame-level alignments, we create intermediate targets-aligned user transcripts and system responses for each block. Experiments show that our approach produces more coherent and interpretable responses than existing duplex methods while supporting lower-latency and overlapping interactions compared to turn-by-turn systems.
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage
Oct 02, 2025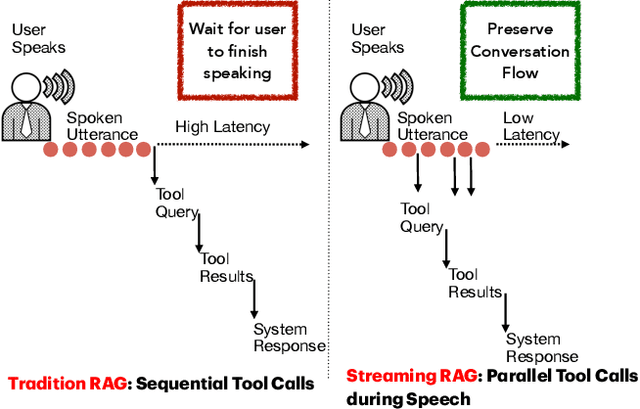
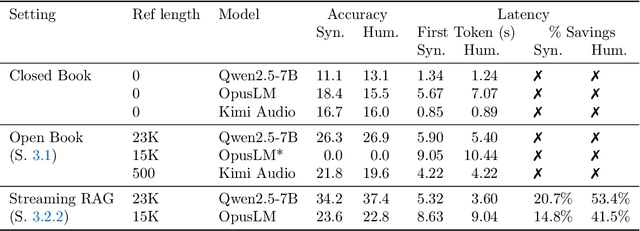
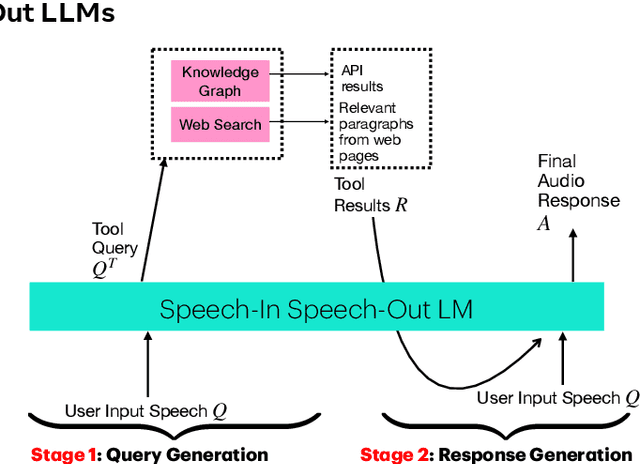
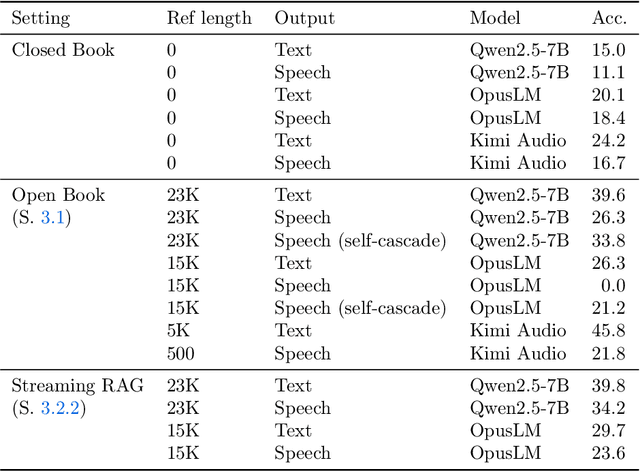
End-to-end speech-in speech-out dialogue systems are emerging as a powerful alternative to traditional ASR-LLM-TTS pipelines, generating more natural, expressive responses with significantly lower latency. However, these systems remain prone to hallucinations due to limited factual grounding. While text-based dialogue systems address this challenge by integrating tools such as web search and knowledge graph APIs, we introduce the first approach to extend tool use directly into speech-in speech-out systems. A key challenge is that tool integration substantially increases response latency, disrupting conversational flow. To mitigate this, we propose Streaming Retrieval-Augmented Generation (Streaming RAG), a novel framework that reduces user-perceived latency by predicting tool queries in parallel with user speech, even before the user finishes speaking. Specifically, we develop a post-training pipeline that teaches the model when to issue tool calls during ongoing speech and how to generate spoken summaries that fuse audio queries with retrieved text results, thereby improving both accuracy and responsiveness. To evaluate our approach, we construct AudioCRAG, a benchmark created by converting queries from the publicly available CRAG dataset into speech form. Experimental results demonstrate that our streaming RAG approach increases QA accuracy by up to 200% relative (from 11.1% to 34.2% absolute) and further enhances user experience by reducing tool use latency by 20%. Importantly, our streaming RAG approach is modality-agnostic and can be applied equally to typed input, paving the way for more agentic, real-time AI assistants.
Scheduled Interleaved Speech-Text Training for Speech-to-Speech Translation with LLMs
Jun 12, 2025



Speech-to-speech translation (S2ST) has been advanced with large language models (LLMs), which are fine-tuned on discrete speech units. In such approaches, modality adaptation from text to speech has been an issue. LLMs are trained on text-only data, which presents challenges to adapt them to speech modality with limited speech-to-speech data. To address the training difficulty, we propose scheduled interleaved speech--text training in this study. We use interleaved speech--text units instead of speech units during training, where aligned text tokens are interleaved at the word level. We gradually decrease the ratio of text as training progresses, to facilitate progressive modality adaptation from text to speech. We conduct experimental evaluations by fine-tuning LLaMA3.2-1B for S2ST on the CVSS dataset. We show that the proposed method consistently improves the translation performances, especially for languages with limited training data.
ARECHO: Autoregressive Evaluation via Chain-Based Hypothesis Optimization for Speech Multi-Metric Estimation
May 30, 2025Speech signal analysis poses significant challenges, particularly in tasks such as speech quality evaluation and profiling, where the goal is to predict multiple perceptual and objective metrics. For instance, metrics like PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility), and MOS (Mean Opinion Score) each capture different aspects of speech quality. However, these metrics often have different scales, assumptions, and dependencies, making joint estimation non-trivial. To address these issues, we introduce ARECHO (Autoregressive Evaluation via Chain-based Hypothesis Optimization), a chain-based, versatile evaluation system for speech assessment grounded in autoregressive dependency modeling. ARECHO is distinguished by three key innovations: (1) a comprehensive speech information tokenization pipeline; (2) a dynamic classifier chain that explicitly captures inter-metric dependencies; and (3) a two-step confidence-oriented decoding algorithm that enhances inference reliability. Experiments demonstrate that ARECHO significantly outperforms the baseline framework across diverse evaluation scenarios, including enhanced speech analysis, speech generation evaluation, and noisy speech evaluation. Furthermore, its dynamic dependency modeling improves interpretability by capturing inter-metric relationships.
BLAB: Brutally Long Audio Bench
May 05, 2025Developing large audio language models (LMs) capable of understanding diverse spoken interactions is essential for accommodating the multimodal nature of human communication and can increase the accessibility of language technologies across different user populations. Recent work on audio LMs has primarily evaluated their performance on short audio segments, typically under 30 seconds, with limited exploration of long-form conversational speech segments that more closely reflect natural user interactions with these models. We introduce Brutally Long Audio Bench (BLAB), a challenging long-form audio benchmark that evaluates audio LMs on localization, duration estimation, emotion, and counting tasks using audio segments averaging 51 minutes in length. BLAB consists of 833+ hours of diverse, full-length audio clips, each paired with human-annotated, text-based natural language questions and answers. Our audio data were collected from permissively licensed sources and underwent a human-assisted filtering process to ensure task compliance. We evaluate six open-source and proprietary audio LMs on BLAB and find that all of them, including advanced models such as Gemini 2.0 Pro and GPT-4o, struggle with the tasks in BLAB. Our comprehensive analysis reveals key insights into the trade-offs between task difficulty and audio duration. In general, we find that audio LMs struggle with long-form speech, with performance declining as duration increases. They perform poorly on localization, temporal reasoning, counting, and struggle to understand non-phonemic information, relying more on prompts than audio content. BLAB serves as a challenging evaluation framework to develop audio LMs with robust long-form audio understanding capabilities.