 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Pruned Key-Value Attention: Learning When to Write by Predicting Future Utility
May 13, 2026Under modern test-time compute and agentic paradigms, language models process ever-longer sequences. Efficient text generation with transformer architectures is increasingly constrained by the Key-Value cache memory footprint and bandwidth. To address this limitation, we introduce Self-Pruned Key-Value Attention (SP-KV), a mechanism designed to predict future KV utility in order to reduce the size of the long-term KV cache. This strategy operates at a fine granularity: a lightweight utility predictor scores each key-value pair, and while recent KVs are always available via a local window, older pairs are written in the cache and used in global attention only if their predicted utility surpasses a given threshold. The LLM and the utility predictor are trained jointly end-to-end exclusively through next-token prediction loss, and are adapted from pretrained LLM checkpoints. Rather than enforcing a fixed compression ratio, SP-KV performs dynamic sparsification: the mechanism adapts to the input and typically reduces the KV cache size by a factor of $3$ to $10\times$, longer sequences often being more compressible. This leads to vast improvements in memory usage and decoding speed, with little to no degradation of validation loss nor performance on a broad set of downstream tasks. Beyond serving as an effective KV-cache reduction mechanism, our method reveals structured layer- and head-specific sparsity patterns that we can use to guide the design of hybrid local-global attention architectures.
Procedural Knowledge at Scale Improves Reasoning
Apr 01, 2026Test-time scaling has emerged as an effective way to improve language models on challenging reasoning tasks. However, most existing methods treat each problem in isolation and do not systematically reuse knowledge from prior reasoning trajectories. In particular, they underutilize procedural knowledge: how to reframe a problem, choose an approach, and verify or backtrack when needed. We introduce Reasoning Memory, a retrieval-augmented generation (RAG) framework for reasoning models that explicitly retrieves and reuses procedural knowledge at scale. Starting from existing corpora of step-by-step reasoning trajectories, we decompose each trajectory into self-contained subquestion-subroutine pairs, yielding a datastore of 32 million compact procedural knowledge entries. At inference time, a lightweight in-thought prompt lets the model verbalize the core subquestion, retrieve relevant subroutines within its reasoning trace, and reason under diverse retrieved subroutines as implicit procedural priors. Across six math, science, and coding benchmarks, Reasoning Memory consistently outperforms RAG with document, trajectory, and template knowledge, as well as a compute-matched test-time scaling baseline. With a higher inference budget, it improves over no retrieval by up to 19.2% and over the strongest compute-matched baseline by 7.9% across task types. Ablation studies show that these gains come from two key factors: the broad procedural coverage of the source trajectories and our decomposition and retrieval design, which together enable effective extraction and reuse of procedural knowledge.
Anchored Decoding: Provably Reducing Copyright Risk for Any Language Model
Feb 06, 2026Modern language models (LMs) tend to memorize portions of their training data and emit verbatim spans. When the underlying sources are sensitive or copyright-protected, such reproduction raises issues of consent and compensation for creators and compliance risks for developers. We propose Anchored Decoding, a plug-and-play inference-time method for suppressing verbatim copying: it enables decoding from any risky LM trained on mixed-license data by keeping generation in bounded proximity to a permissively trained safe LM. Anchored Decoding adaptively allocates a user-chosen information budget over the generation trajectory and enforces per-step constraints that yield a sequence-level guarantee, enabling a tunable risk-utility trade-off. To make Anchored Decoding practically useful, we introduce a new permissively trained safe model (TinyComma 1.8B), as well as Anchored$_{\mathrm{Byte}}$ Decoding, a byte-level variant of our method that enables cross-vocabulary fusion via the ByteSampler framework (Hayase et al., 2025). We evaluate our methods across six model pairs on long-form evaluations of copyright risk and utility. Anchored and Anchored$_{\mathrm{Byte}}$ Decoding define a new Pareto frontier, preserving near-original fluency and factuality while eliminating up to 75% of the measurable copying gap (averaged over six copying metrics) between the risky baseline and a safe reference, at a modest inference overhead.
CRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025



Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
SCRIBES: Web-Scale Script-Based Semi-Structured Data Extraction with Reinforcement Learning
Oct 02, 2025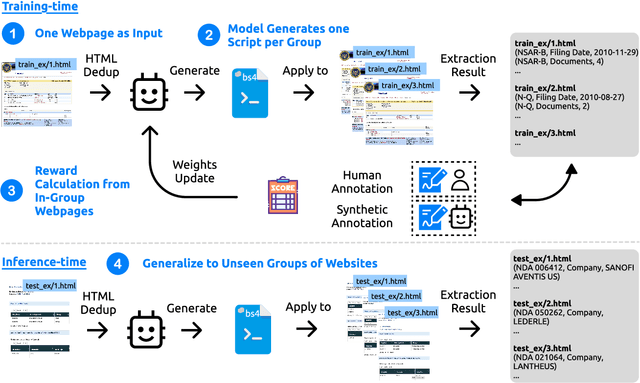
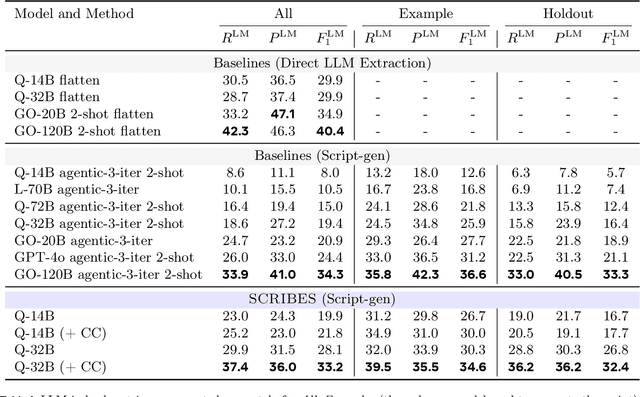
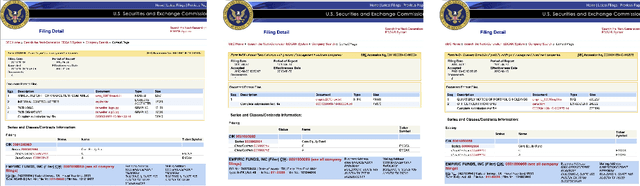

Semi-structured content in HTML tables, lists, and infoboxes accounts for a substantial share of factual data on the web, yet the formatting complicates usage, and reliably extracting structured information from them remains challenging. Existing methods either lack generalization or are resource-intensive due to per-page LLM inference. In this paper, we introduce SCRIBES (SCRIpt-Based Semi-Structured Content Extraction at Web-Scale), a novel reinforcement learning framework that leverages layout similarity across webpages within the same site as a reward signal. Instead of processing each page individually, SCRIBES generates reusable extraction scripts that can be applied to groups of structurally similar webpages. Our approach further improves by iteratively training on synthetic annotations from in-the-wild CommonCrawl data. Experiments show that our approach outperforms strong baselines by over 13% in script quality and boosts downstream question answering accuracy by more than 4% for GPT-4o, enabling scalable and resource-efficient web information extraction.
Learning to Reason for Factuality
Aug 07, 2025Reasoning Large Language Models (R-LLMs) have significantly advanced complex reasoning tasks but often struggle with factuality, generating substantially more hallucinations than their non-reasoning counterparts on long-form factuality benchmarks. However, extending online Reinforcement Learning (RL), a key component in recent R-LLM advancements, to the long-form factuality setting poses several unique challenges due to the lack of reliable verification methods. Previous work has utilized automatic factuality evaluation frameworks such as FActScore to curate preference data in the offline RL setting, yet we find that directly leveraging such methods as the reward in online RL leads to reward hacking in multiple ways, such as producing less detailed or relevant responses. We propose a novel reward function that simultaneously considers the factual precision, response detail level, and answer relevance, and applies online RL to learn high quality factual reasoning. Evaluated on six long-form factuality benchmarks, our factual reasoning model achieves an average reduction of 23.1 percentage points in hallucination rate, a 23% increase in answer detail level, and no degradation in the overall response helpfulness.
MetaCLIP 2: A Worldwide Scaling Recipe
Jul 29, 2025
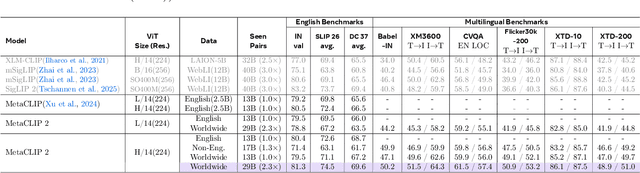


Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP's training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., "curse of multilinguality" that is common in LLMs. Here, we present MetaCLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, MetaCLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
FlexOlmo: Open Language Models for Flexible Data Use
Jul 09, 2025



We introduce FlexOlmo, a new class of language models (LMs) that supports (1) distributed training without data sharing, where different model parameters are independently trained on closed datasets, and (2) data-flexible inference, where these parameters along with their associated data can be flexibly included or excluded from model inferences with no further training. FlexOlmo employs a mixture-of-experts (MoE) architecture where each expert is trained independently on closed datasets and later integrated through a new domain-informed routing without any joint training. FlexOlmo is trained on FlexMix, a corpus we curate comprising publicly available datasets alongside seven domain-specific sets, representing realistic approximations of closed sets. We evaluate models with up to 37 billion parameters (20 billion active) on 31 diverse downstream tasks. We show that a general expert trained on public data can be effectively combined with independently trained experts from other data owners, leading to an average 41% relative improvement while allowing users to opt out of certain data based on data licensing or permission requirements. Our approach also outperforms prior model merging methods by 10.1% on average and surpasses the standard MoE trained without data restrictions using the same training FLOPs. Altogether, this research presents a solution for both data owners and researchers in regulated industries with sensitive or protected data. FlexOlmo enables benefiting from closed data while respecting data owners' preferences by keeping their data local and supporting fine-grained control of data access during inference.
ConfQA: Answer Only If You Are Confident
Jun 08, 2025



Can we teach Large Language Models (LLMs) to refrain from hallucinating factual statements? In this paper we present a fine-tuning strategy that we call ConfQA, which can reduce hallucination rate from 20-40% to under 5% across multiple factuality benchmarks. The core idea is simple: when the LLM answers a question correctly, it is trained to continue with the answer; otherwise, it is trained to admit "I am unsure". But there are two key factors that make the training highly effective. First, we introduce a dampening prompt "answer only if you are confident" to explicitly guide the behavior, without which hallucination remains high as 15%-25%. Second, we leverage simple factual statements, specifically attribute values from knowledge graphs, to help LLMs calibrate the confidence, resulting in robust generalization across domains and question types. Building on this insight, we propose the Dual Neural Knowledge framework, which seamlessly select between internally parameterized neural knowledge and externally recorded symbolic knowledge based on ConfQA's confidence. The framework enables potential accuracy gains to beyond 95%, while reducing unnecessary external retrievals by over 30%.
ReasonIR: Training Retrievers for Reasoning Tasks
Apr 29, 2025We present ReasonIR-8B, the first retriever specifically trained for general reasoning tasks. Existing retrievers have shown limited gains on reasoning tasks, in part because existing training datasets focus on short factual queries tied to documents that straightforwardly answer them. We develop a synthetic data generation pipeline that, for each document, our pipeline creates a challenging and relevant query, along with a plausibly related but ultimately unhelpful hard negative. By training on a mixture of our synthetic data and existing public data, ReasonIR-8B achieves a new state-of-the-art of 29.9 nDCG@10 without reranker and 36.9 nDCG@10 with reranker on BRIGHT, a widely-used reasoning-intensive information retrieval (IR) benchmark. When applied to RAG tasks, ReasonIR-8B improves MMLU and GPQA performance by 6.4% and 22.6% respectively, relative to the closed-book baseline, outperforming other retrievers and search engines. In addition, ReasonIR-8B uses test-time compute more effectively: on BRIGHT, its performance consistently increases with longer and more information-rich rewritten queries; it continues to outperform other retrievers when combined with an LLM reranker. Our training recipe is general and can be easily extended to future LLMs; to this end, we open-source our code, data, and model.