 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Channel Differential ASR for Robust Wearer Speech Recognition on Smart Glasses
Sep 17, 2025With the growing adoption of wearable devices such as smart glasses for AI assistants, wearer speech recognition (WSR) is becoming increasingly critical to next-generation human-computer interfaces. However, in real environments, interference from side-talk speech remains a significant challenge to WSR and may cause accumulated errors for downstream tasks such as natural language processing. In this work, we introduce a novel multi-channel differential automatic speech recognition (ASR) method for robust WSR on smart glasses. The proposed system takes differential inputs from different frontends that complement each other to improve the robustness of WSR, including a beamformer, microphone selection, and a lightweight side-talk detection model. Evaluations on both simulated and real datasets demonstrate that the proposed system outperforms the traditional approach, achieving up to an 18.0% relative reduction in word error rate.
On Robustness to Missing Video for Audiovisual Speech Recognition
Dec 19, 2023



It has been shown that learning audiovisual features can lead to improved speech recognition performance over audio-only features, especially for noisy speech. However, in many common applications, the visual features are partially or entirely missing, e.g.~the speaker might move off screen. Multi-modal models need to be robust: missing video frames should not degrade the performance of an audiovisual model to be worse than that of a single-modality audio-only model. While there have been many attempts at building robust models, there is little consensus on how robustness should be evaluated. To address this, we introduce a framework that allows claims about robustness to be evaluated in a precise and testable way. We also conduct a systematic empirical study of the robustness of common audiovisual speech recognition architectures on a range of acoustic noise conditions and test suites. Finally, we show that an architecture-agnostic solution based on cascades can consistently achieve robustness to missing video, even in settings where existing techniques for robustness like dropout fall short.
Revisiting the Entropy Semiring for Neural Speech Recognition
Dec 19, 2023



In streaming settings, speech recognition models have to map sub-sequences of speech to text before the full audio stream becomes available. However, since alignment information between speech and text is rarely available during training, models need to learn it in a completely self-supervised way. In practice, the exponential number of possible alignments makes this extremely challenging, with models often learning peaky or sub-optimal alignments. Prima facie, the exponential nature of the alignment space makes it difficult to even quantify the uncertainty of a model's alignment distribution. Fortunately, it has been known for decades that the entropy of a probabilistic finite state transducer can be computed in time linear to the size of the transducer via a dynamic programming reduction based on semirings. In this work, we revisit the entropy semiring for neural speech recognition models, and show how alignment entropy can be used to supervise models through regularization or distillation. We also contribute an open-source implementation of CTC and RNN-T in the semiring framework that includes numerically stable and highly parallel variants of the entropy semiring. Empirically, we observe that the addition of alignment distillation improves the accuracy and latency of an already well-optimized teacher-student distillation model, achieving state-of-the-art performance on the Librispeech dataset in the streaming scenario.
Audio-visual fine-tuning of audio-only ASR models
Dec 14, 2023


Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.
Cascaded encoders for fine-tuning ASR models on overlapped speech
Jun 28, 2023



Multi-talker speech recognition (MT-ASR) has been shown to improve ASR performance on speech containing overlapping utterances from more than one speaker. Multi-talker models have typically been trained from scratch using simulated or actual overlapping speech datasets. On the other hand, the trend in ASR has been to train foundation models using massive datasets collected from a wide variety of task domains. Given the scale of these models and their ability to generalize well across a variety of domains, it makes sense to consider scenarios where a foundation model is augmented with multi-talker capability. This paper presents an MT-ASR model formed by combining a well-trained foundation model with a multi-talker mask model in a cascaded RNN-T encoder configuration. Experimental results show that the cascade configuration provides improved WER on overlapping speech utterances with respect to a baseline multi-talker model without sacrificing performance achievable by the foundation model on non-overlapping utterances.
Conformers are All You Need for Visual Speech Recogntion
Feb 17, 2023



Visual speech recognition models extract visual features in a hierarchical manner. At the lower level, there is a visual front-end with a limited temporal receptive field that processes the raw pixels depicting the lips or faces. At the higher level, there is an encoder that attends to the embeddings produced by the front-end over a large temporal receptive field. Previous work has focused on improving the visual front-end of the model to extract more useful features for speech recognition. Surprisingly, our work shows that complex visual front-ends are not necessary. Instead of allocating resources to a sophisticated visual front-end, we find that a linear visual front-end paired with a larger Conformer encoder results in lower latency, more efficient memory usage, and improved WER performance. We achieve a new state-of-the-art of $12.8\%$ WER for visual speech recognition on the TED LRS3 dataset, which rivals the performance of audio-only models from just four years ago.
End-to-End Multi-Person Audio/Visual Automatic Speech Recognition
May 11, 2022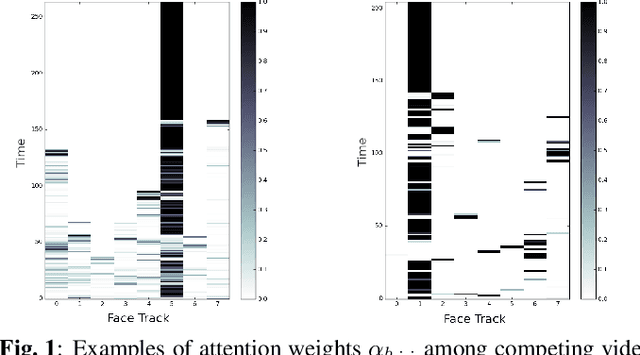

Traditionally, audio-visual automatic speech recognition has been studied under the assumption that the speaking face on the visual signal is the face matching the audio. However, in a more realistic setting, when multiple faces are potentially on screen one needs to decide which face to feed to the A/V ASR system. The present work takes the recent progress of A/V ASR one step further and considers the scenario where multiple people are simultaneously on screen (multi-person A/V ASR). We propose a fully differentiable A/V ASR model that is able to handle multiple face tracks in a video. Instead of relying on two separate models for speaker face selection and audio-visual ASR on a single face track, we introduce an attention layer to the ASR encoder that is able to soft-select the appropriate face video track. Experiments carried out on an A/V system trained on over 30k hours of YouTube videos illustrate that the proposed approach can automatically select the proper face tracks with minor WER degradation compared to an oracle selection of the speaking face while still showing benefits of employing the visual signal instead of the audio alone.
A Closer Look at Audio-Visual Multi-Person Speech Recognition and Active Speaker Selection
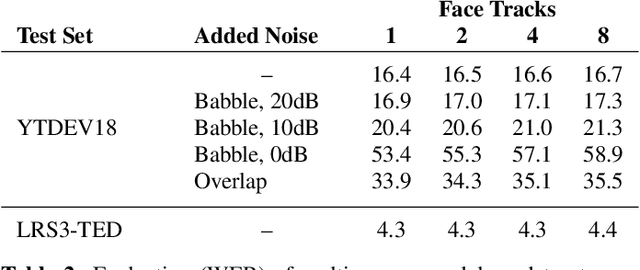
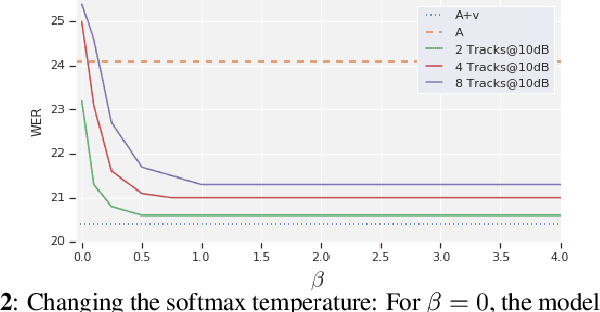
May 11, 2022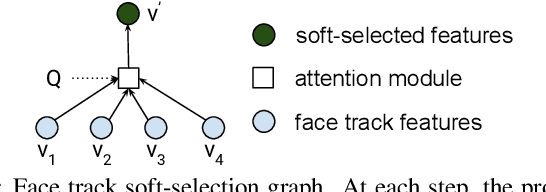
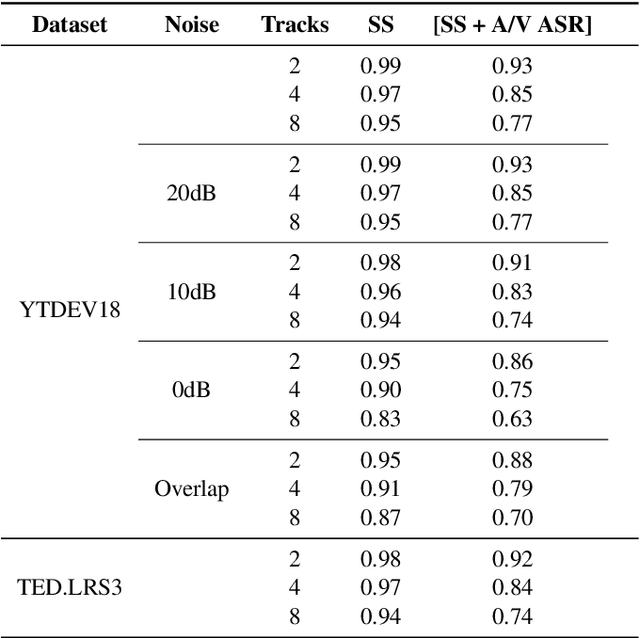
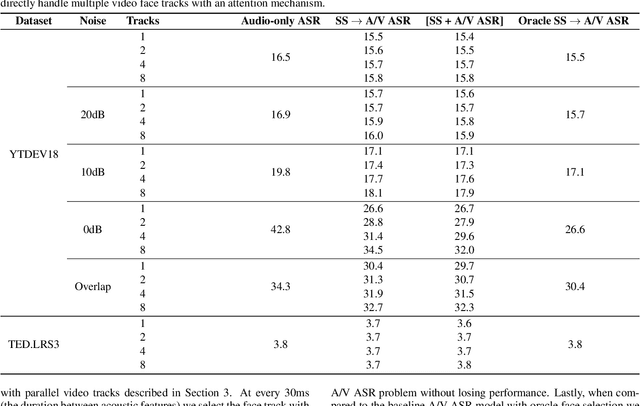
Audio-visual automatic speech recognition is a promising approach to robust ASR under noisy conditions. However, up until recently it had been traditionally studied in isolation assuming the video of a single speaking face matches the audio, and selecting the active speaker at inference time when multiple people are on screen was put aside as a separate problem. As an alternative, recent work has proposed to address the two problems simultaneously with an attention mechanism, baking the speaker selection problem directly into a fully differentiable model. One interesting finding was that the attention indirectly learns the association between the audio and the speaking face even though this correspondence is never explicitly provided at training time. In the present work we further investigate this connection and examine the interplay between the two problems. With experiments involving over 50 thousand hours of public YouTube videos as training data, we first evaluate the accuracy of the attention layer on an active speaker selection task. Secondly, we show under closer scrutiny that an end-to-end model performs at least as well as a considerably larger two-step system that utilizes a hard decision boundary under various noise conditions and number of parallel face tracks.
Best of Both Worlds: Multi-task Audio-Visual Automatic Speech Recognition and Active Speaker Detection
May 10, 2022
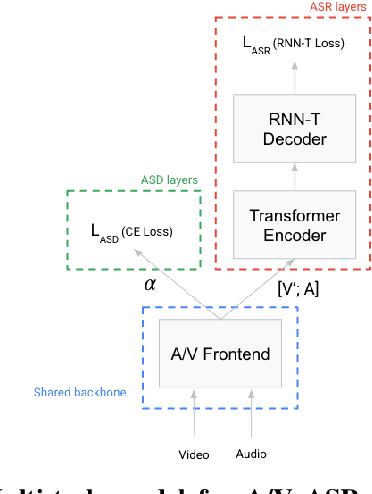
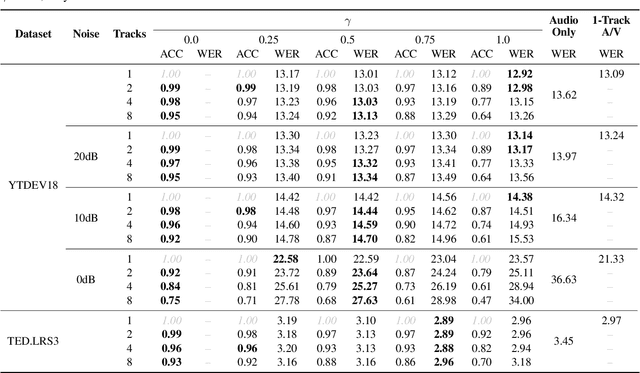
Under noisy conditions, automatic speech recognition (ASR) can greatly benefit from the addition of visual signals coming from a video of the speaker's face. However, when multiple candidate speakers are visible this traditionally requires solving a separate problem, namely active speaker detection (ASD), which entails selecting at each moment in time which of the visible faces corresponds to the audio. Recent work has shown that we can solve both problems simultaneously by employing an attention mechanism over the competing video tracks of the speakers' faces, at the cost of sacrificing some accuracy on active speaker detection. This work closes this gap in active speaker detection accuracy by presenting a single model that can be jointly trained with a multi-task loss. By combining the two tasks during training we reduce the ASD classification accuracy by approximately 25%, while simultaneously improving the ASR performance when compared to the multi-person baseline trained exclusively for ASR.
End-to-end multi-talker audio-visual ASR using an active speaker attention module
Apr 01, 2022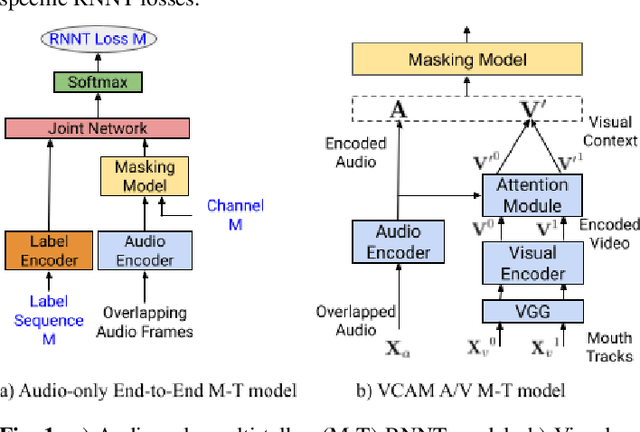
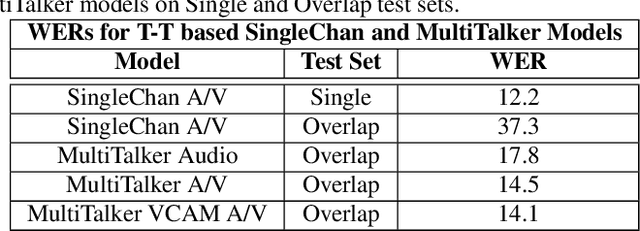
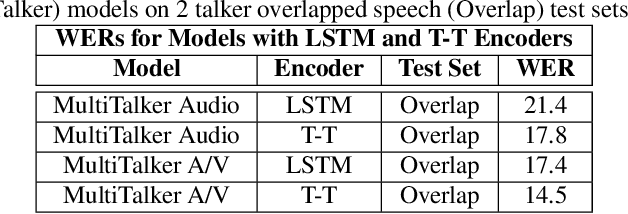
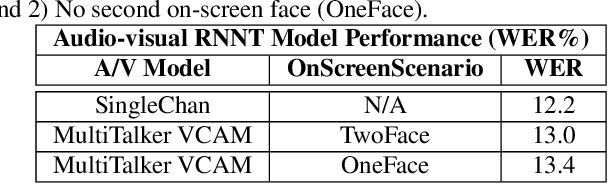
This paper presents a new approach for end-to-end audio-visual multi-talker speech recognition. The approach, referred to here as the visual context attention model (VCAM), is important because it uses the available video information to assign decoded text to one of multiple visible faces. This essentially resolves the label ambiguity issue associated with most multi-talker modeling approaches which can decode multiple label strings but cannot assign the label strings to the correct speakers. This is implemented as a transformer-transducer based end-to-end model and evaluated using a two speaker audio-visual overlapping speech dataset created from YouTube videos. It is shown in the paper that the VCAM model improves performance with respect to previously reported audio-only and audio-visual multi-talker ASR systems.