 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios
Sep 26, 2025Large language model (LLM) powered code agents are rapidly transforming software engineering by automating tasks such as testing, debugging, and repairing, yet the security risks of their generated code have become a critical concern. Existing benchmarks have offered valuable insights but remain insufficient: they often overlook the genuine context in which vulnerabilities were introduced or adopt narrow evaluation protocols that fail to capture either functional correctness or newly introduced vulnerabilities. We therefore introduce SecureAgentBench, a benchmark of 105 coding tasks designed to rigorously evaluate code agents' capabilities in secure code generation. Each task includes (i) realistic task settings that require multi-file edits in large repositories, (ii) aligned contexts based on real-world open-source vulnerabilities with precisely identified introduction points, and (iii) comprehensive evaluation that combines functionality testing, vulnerability checking through proof-of-concept exploits, and detection of newly introduced vulnerabilities using static analysis. We evaluate three representative agents (SWE-agent, OpenHands, and Aider) with three state-of-the-art LLMs (Claude 3.7 Sonnet, GPT-4.1, and DeepSeek-V3.1). Results show that (i) current agents struggle to produce secure code, as even the best-performing one, SWE-agent supported by DeepSeek-V3.1, achieves merely 15.2% correct-and-secure solutions, (ii) some agents produce functionally correct code but still introduce vulnerabilities, including new ones not previously recorded, and (iii) adding explicit security instructions for agents does not significantly improve secure coding, underscoring the need for further research. These findings establish SecureAgentBench as a rigorous benchmark for secure code generation and a step toward more reliable software development with LLMs.
"My productivity is boosted, but ..." Demystifying Users' Perception on AI Coding Assistants
Aug 17, 2025This paper aims to explore fundamental questions in the era when AI coding assistants like GitHub Copilot are widely adopted: what do developers truly value and criticize in AI coding assistants, and what does this reveal about their needs and expectations in real-world software development? Unlike previous studies that conduct observational research in controlled and simulated environments, we analyze extensive, first-hand user reviews of AI coding assistants, which capture developers' authentic perspectives and experiences drawn directly from their actual day-to-day work contexts. We identify 1,085 AI coding assistants from the Visual Studio Code Marketplace. Although they only account for 1.64% of all extensions, we observe a surge in these assistants: over 90% of them are released within the past two years. We then manually analyze the user reviews sampled from 32 AI coding assistants that have sufficient installations and reviews to construct a comprehensive taxonomy of user concerns and feedback about these assistants. We manually annotate each review's attitude when mentioning certain aspects of coding assistants, yielding nuanced insights into user satisfaction and dissatisfaction regarding specific features, concerns, and overall tool performance. Built on top of the findings-including how users demand not just intelligent suggestions but also context-aware, customizable, and resource-efficient interactions-we propose five practical implications and suggestions to guide the enhancement of AI coding assistants that satisfy user needs.
Mind Your Data! Hiding Backdoors in Offline Reinforcement Learning Datasets
Oct 07, 2022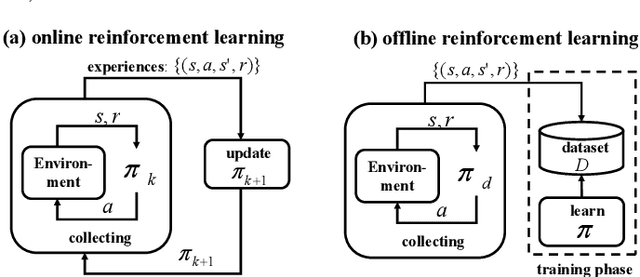

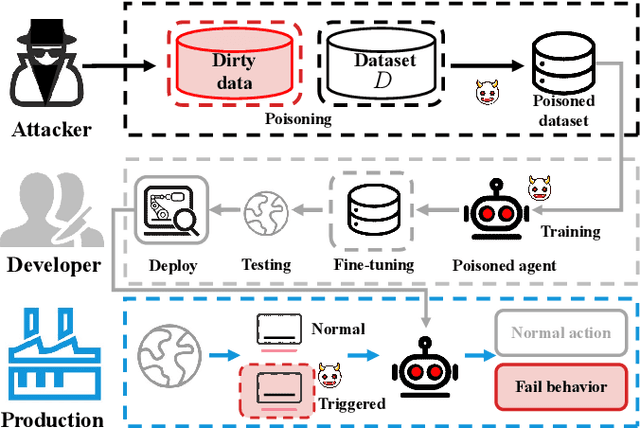
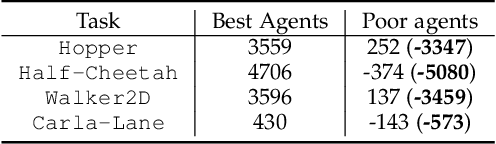
A growing body of research works has focused on the Offline Reinforcement Learning (RL) paradigm. Data providers share large pre-collected datasets on which others can train high-quality agents without interacting with the environments. Such an offline RL paradigm has demonstrated effectiveness in many critical tasks, including robot control, autonomous driving, etc. A well-trained agent can be regarded as a software system. However, less attention is paid to investigating the security threats to the offline RL system. In this paper, we focus on a critical security threat: backdoor attacks. Given normal observations, an agent implanted with backdoors takes actions leading to high rewards. However, the same agent takes actions that lead to low rewards if the observations are injected with triggers that can activate the backdoor. In this paper, we propose Baffle (Backdoor Attack for Offline Reinforcement Learning) and evaluate how different Offline RL algorithms react to this attack. Our experiments conducted on four tasks and four offline RL algorithms expose a disquieting fact: none of the existing offline RL algorithms is immune to such a backdoor attack. More specifically, Baffle modifies $10\%$ of the datasets for four tasks (3 robotic controls and 1 autonomous driving). Agents trained on the poisoned datasets perform well in normal settings. However, when triggers are presented, the agents' performance decreases drastically by $63.6\%$, $57.8\%$, $60.8\%$ and $44.7\%$ in the four tasks on average. The backdoor still persists after fine-tuning poisoned agents on clean datasets. We further show that the inserted backdoor is also hard to be detected by a popular defensive method. This paper calls attention to developing more effective protection for the open-source offline RL dataset.