 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Sales Lead Scoring with LLM-based Hierarchical Preference Ranking
Jun 03, 2026Sales lead conversion in high-stakes domains (e.g., automotive, real estate) differs fundamentally from e-commerce recommendation due to prolonged decision cycles and multi-stage funnels. Traditional lead scoring methods rule-based scorecards, machine learning, or pointwise CTR models face severe challenges: sparse supervision, a semantic gap in unstructured CRM logs, and inability to capture relative lead priority. While Large Language Models(LLMs) offer superior semantic understanding of customer interactions, general-purpose LLMs are ill-suited for lead ranking: they generate text rather than comparable scores, and lack alignment with the hierarchical priorities of sales funnels. We introduce an LLM-based discriminative framework for sales lead scoring, which supports joint modeling of structured CRM features and unstructured customer interactions. On top of this framework, we propose HPRO (Hierarchical Preference Ranking Optimization), which augments sales lead scoring with a hierarchical preference ranking objective. HPRO employs a margin-aware Bradley-Terry formulation to transform sparse binary labels into dense, funnel-aware preference pairs, enabling lead scoring to leverage both pointwise and pairwise supervision. Experiments on large-scale data from a leading NEV brand demonstrate state-of-the-art classification (AUC 0.8161) and ranking performance (+39.7% precision among top-ranked leads). A 132-day online A/B test validates 9.5% sales volume uplift, confirming real-world commercial impact.
SaliMory: Orchestrating Cognitive Memory for Conversational Agents
Jun 02, 2026Conversational agents that serve as lifelong companions must maintain persistent memory across all interactions. However, simply expanding context windows with raw retrieval degrades reasoning quality, while training memory agents via standard reinforcement learning creates a severe credit assignment bottleneck in a multi-stage pipeline. To solve this, we introduce SALIMORY, a framework that trains a single language model to manage a cognitively-structured memory-spanning user facts, preferences, and working memory. By introducing a hierarchical stage-wise process reward and reward-decomposed contrastive refinement, SALIMORY provides isolated supervision for distinct memory operations (selective filtering, consolidation, and cue-driven recall) end-to-end. SALIMORY cuts memory-attributed failures by one-third, outperforms the state-of-the-art by over 10% in end-to-end accuracy, and more than doubles the Good Personalization rate.
Unsupervised Denoising of Diffusion-Weighted Images with Bias and Variance Corrected Noise Modeling
Feb 22, 2026Diffusion magnetic resonance imaging (dMRI) plays a vital role in both clinical diagnostics and neuroscience research. However, its inherently low signal-to-noise ratio (SNR), especially under high diffusion weighting, significantly degrades image quality and impairs downstream analysis. Recent self-supervised and unsupervised denoising methods offer a practical solution by enhancing image quality without requiring clean references. However, most of these methods do not explicitly account for the non-Gaussian noise characteristics commonly present in dMRI magnitude data during the supervised learning process, potentially leading to systematic bias and heteroscedastic variance, particularly under low-SNR conditions. To overcome this limitation, we introduce noise-corrected training objectives that explicitly model Rician statistics. Specifically, we propose two alternative loss functions: one derived from the first-order moment to remove mean bias, and another from the second-order moment to correct squared-signal bias. Both losses include adaptive weighting to account for variance heterogeneity and can be used without changing the network architecture. These objectives are instantiated in an image-specific, unsupervised Deep Image Prior (DIP) framework. Comprehensive experiments on simulated and in-vivo dMRI show that the proposed losses effectively reduce Rician bias and suppress noise fluctuations, yielding higher image quality and more reliable diffusion metrics than state-of-the-art denoising baselines. These results underscore the importance of bias- and variance-aware noise modeling for robust dMRI analysis under low-SNR conditions.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
Feb 12, 2026The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.
ShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
Unified Multimodal and Multilingual Retrieval via Multi-Task Learning with NLU Integration
Jan 21, 2026Multimodal retrieval systems typically employ Vision Language Models (VLMs) that encode images and text independently into vectors within a shared embedding space. Despite incorporating text encoders, VLMs consistently underperform specialized text models on text-only retrieval tasks. Moreover, introducing additional text encoders increases storage, inference overhead, and exacerbates retrieval inefficiencies, especially in multilingual settings. To address these limitations, we propose a multi-task learning framework that unifies the feature representation across images, long and short texts, and intent-rich queries. To our knowledge, this is the first work to jointly optimize multilingual image retrieval, text retrieval, and natural language understanding (NLU) tasks within a single framework. Our approach integrates image and text retrieval with a shared text encoder that is enhanced by NLU features for intent understanding and retrieval accuracy.
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage
Oct 02, 2025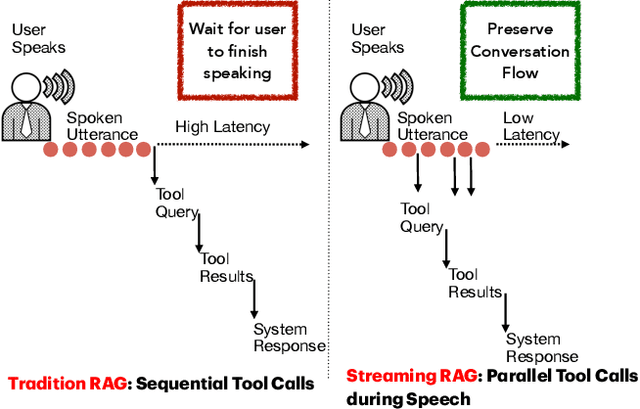
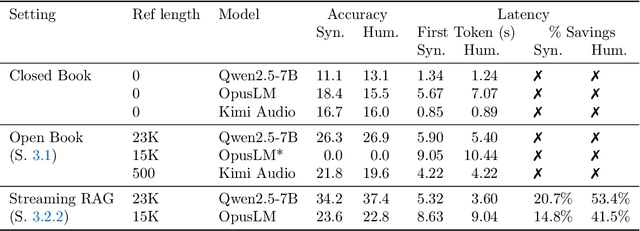
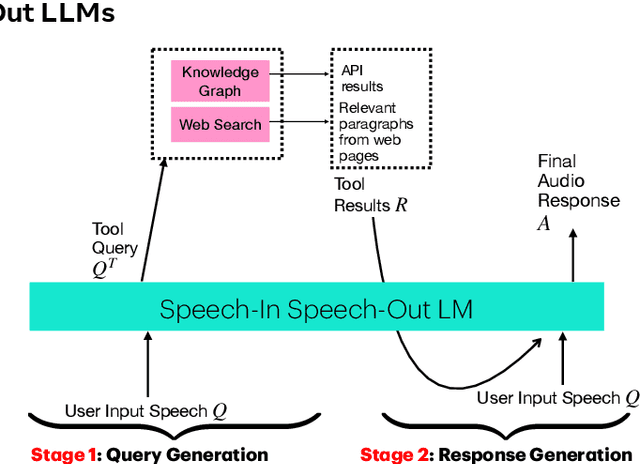
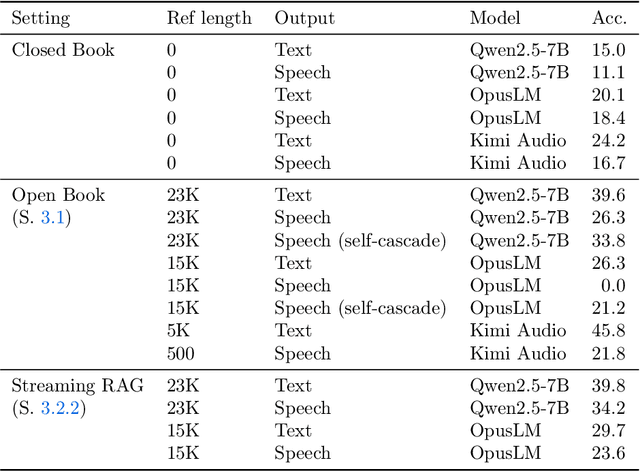
End-to-end speech-in speech-out dialogue systems are emerging as a powerful alternative to traditional ASR-LLM-TTS pipelines, generating more natural, expressive responses with significantly lower latency. However, these systems remain prone to hallucinations due to limited factual grounding. While text-based dialogue systems address this challenge by integrating tools such as web search and knowledge graph APIs, we introduce the first approach to extend tool use directly into speech-in speech-out systems. A key challenge is that tool integration substantially increases response latency, disrupting conversational flow. To mitigate this, we propose Streaming Retrieval-Augmented Generation (Streaming RAG), a novel framework that reduces user-perceived latency by predicting tool queries in parallel with user speech, even before the user finishes speaking. Specifically, we develop a post-training pipeline that teaches the model when to issue tool calls during ongoing speech and how to generate spoken summaries that fuse audio queries with retrieved text results, thereby improving both accuracy and responsiveness. To evaluate our approach, we construct AudioCRAG, a benchmark created by converting queries from the publicly available CRAG dataset into speech form. Experimental results demonstrate that our streaming RAG approach increases QA accuracy by up to 200% relative (from 11.1% to 34.2% absolute) and further enhances user experience by reducing tool use latency by 20%. Importantly, our streaming RAG approach is modality-agnostic and can be applied equally to typed input, paving the way for more agentic, real-time AI assistants.
SCRIBES: Web-Scale Script-Based Semi-Structured Data Extraction with Reinforcement Learning
Oct 02, 2025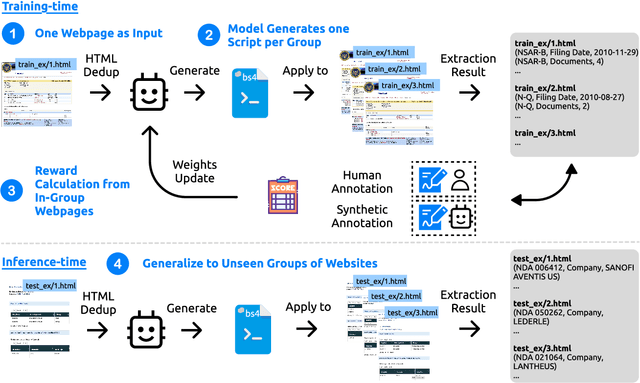
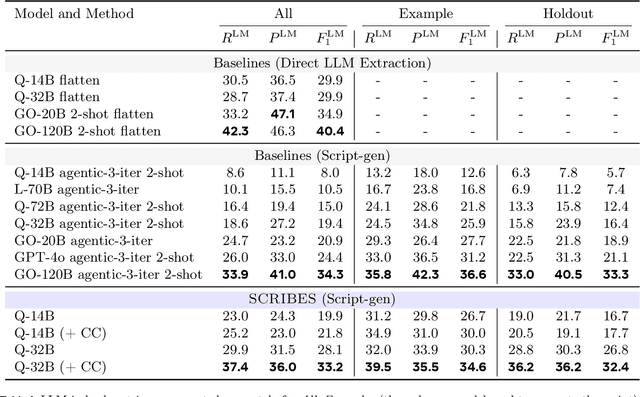
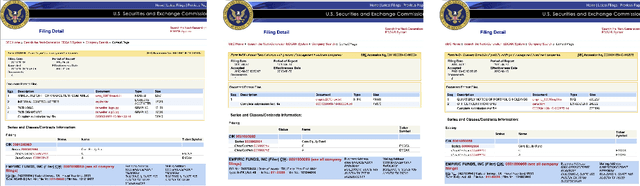

Semi-structured content in HTML tables, lists, and infoboxes accounts for a substantial share of factual data on the web, yet the formatting complicates usage, and reliably extracting structured information from them remains challenging. Existing methods either lack generalization or are resource-intensive due to per-page LLM inference. In this paper, we introduce SCRIBES (SCRIpt-Based Semi-Structured Content Extraction at Web-Scale), a novel reinforcement learning framework that leverages layout similarity across webpages within the same site as a reward signal. Instead of processing each page individually, SCRIBES generates reusable extraction scripts that can be applied to groups of structurally similar webpages. Our approach further improves by iteratively training on synthetic annotations from in-the-wild CommonCrawl data. Experiments show that our approach outperforms strong baselines by over 13% in script quality and boosts downstream question answering accuracy by more than 4% for GPT-4o, enabling scalable and resource-efficient web information extraction.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.