 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Paralinguistic Understanding and Generation in Speech LLMs via Multi-Task Reinforcement Learning
Mar 16, 2026Speech large language models (LLMs) observe paralinguistic cues such as prosody, emotion, and non-verbal sounds--crucial for intent understanding. However, leveraging these cues faces challenges: limited training data, annotation difficulty, and models exploiting lexical shortcuts over paralinguistic signals. We propose multi-task reinforcement learning (RL) with chain-of-thought prompting that elicits explicit affective reasoning. To address data scarcity, we introduce a paralinguistics-aware speech LLM (PALLM) that jointly optimizes sentiment classification from audio and paralinguistics-aware response generation via a two-stage pipeline. Experiments demonstrate that our approach improves paralinguistics understanding over both supervised baselines and strong proprietary models (Gemini-2.5-Pro, GPT-4o-audio) by 8-12% on Expresso, IEMOCAP, and RAVDESS. The results show that modeling paralinguistic reasoning with multi-task RL is crucial for building emotionally intelligent speech LLMs.
WearVox: An Egocentric Multichannel Voice Assistant Benchmark for Wearables
Dec 25, 2025Wearable devices such as AI glasses are transforming voice assistants into always-available, hands-free collaborators that integrate seamlessly with daily life, but they also introduce challenges like egocentric audio affected by motion and noise, rapid micro-interactions, and the need to distinguish device-directed speech from background conversations. Existing benchmarks largely overlook these complexities, focusing instead on clean or generic conversational audio. To bridge this gap, we present WearVox, the first benchmark designed to rigorously evaluate voice assistants in realistic wearable scenarios. WearVox comprises 3,842 multi-channel, egocentric audio recordings collected via AI glasses across five diverse tasks including Search-Grounded QA, Closed-Book QA, Side-Talk Rejection, Tool Calling, and Speech Translation, spanning a wide range of indoor and outdoor environments and acoustic conditions. Each recording is accompanied by rich metadata, enabling nuanced analysis of model performance under real-world constraints. We benchmark leading proprietary and open-source speech Large Language Models (SLLMs) and find that most real-time SLLMs achieve accuracies on WearVox ranging from 29% to 59%, with substantial performance degradation on noisy outdoor audio, underscoring the difficulty and realism of the benchmark. Additionally, we conduct a case study with two new SLLMs that perform inference with single-channel and multi-channel audio, demonstrating that multi-channel audio inputs significantly enhance model robustness to environmental noise and improve discrimination between device-directed and background speech. Our results highlight the critical importance of spatial audio cues for context-aware voice assistants and establish WearVox as a comprehensive testbed for advancing wearable voice AI research.
Stream RAG: Instant and Accurate Spoken Dialogue Systems with Streaming Tool Usage
Oct 02, 2025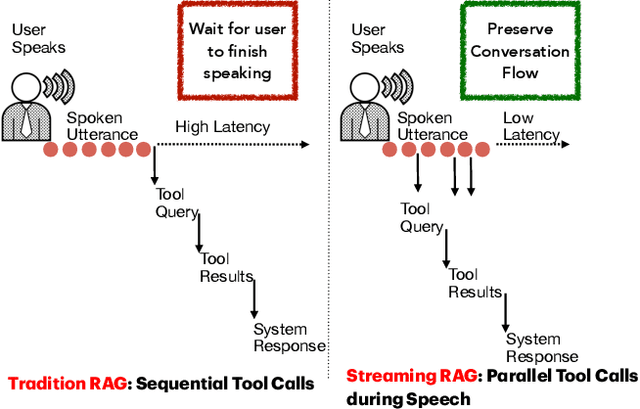
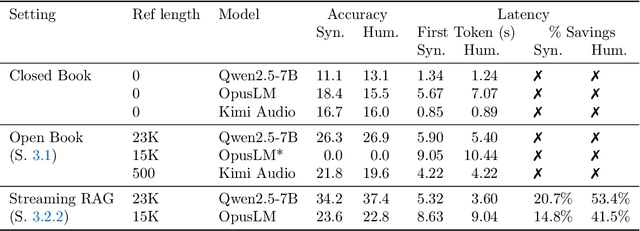
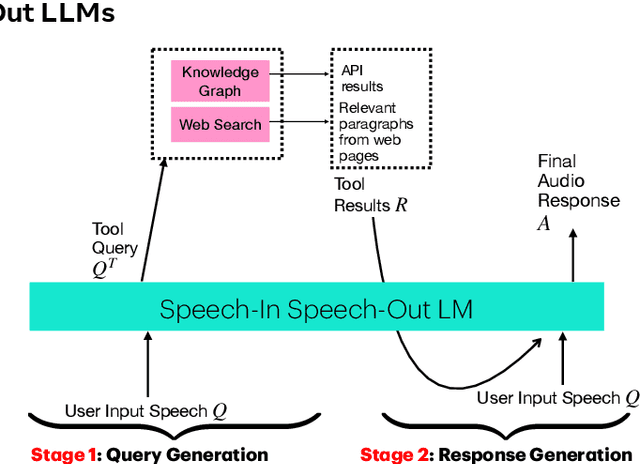
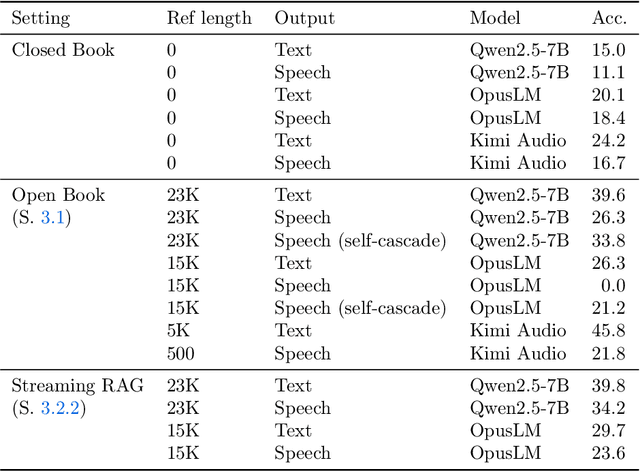
End-to-end speech-in speech-out dialogue systems are emerging as a powerful alternative to traditional ASR-LLM-TTS pipelines, generating more natural, expressive responses with significantly lower latency. However, these systems remain prone to hallucinations due to limited factual grounding. While text-based dialogue systems address this challenge by integrating tools such as web search and knowledge graph APIs, we introduce the first approach to extend tool use directly into speech-in speech-out systems. A key challenge is that tool integration substantially increases response latency, disrupting conversational flow. To mitigate this, we propose Streaming Retrieval-Augmented Generation (Streaming RAG), a novel framework that reduces user-perceived latency by predicting tool queries in parallel with user speech, even before the user finishes speaking. Specifically, we develop a post-training pipeline that teaches the model when to issue tool calls during ongoing speech and how to generate spoken summaries that fuse audio queries with retrieved text results, thereby improving both accuracy and responsiveness. To evaluate our approach, we construct AudioCRAG, a benchmark created by converting queries from the publicly available CRAG dataset into speech form. Experimental results demonstrate that our streaming RAG approach increases QA accuracy by up to 200% relative (from 11.1% to 34.2% absolute) and further enhances user experience by reducing tool use latency by 20%. Importantly, our streaming RAG approach is modality-agnostic and can be applied equally to typed input, paving the way for more agentic, real-time AI assistants.